

Here’s something worth sitting with: when a chatbot tells you it doesn’t know something, that admission didn’t happen by accident. It was trained into the model, layer by careful layer, through a process that’s equal parts engineering and behavioral psychology. Most people assume AI confidence is a feature baked in by default, but the opposite is actually the engineering challenge. Getting a language model to say “I don’t know” is genuinely hard, and understanding how it works will make you a much smarter user of these tools.
AI chatbots give different answers to the same question based on settings you can actually control, and the same underlying mechanics that govern output randomness also shape how confidently a model presents information. The two are more connected than most people realize.
Why AI Models Hallucinate in the First Place
Before you can appreciate how chatbots learn to express uncertainty, you need to understand why they confidently say wrong things at all. Language models are trained to predict the next most probable word in a sequence. They’re not retrieving facts from a database. They’re pattern-matching across billions of text examples to generate responses that sound coherent and contextually appropriate.
The problem is that “sounds right” and “is right” are not the same thing. A model trained purely on next-token prediction has no internal mechanism that distinguishes between a statement it can support and one it’s essentially improvising. The architecture doesn’t natively encode “I have strong evidence for this” versus “I’m extrapolating wildly.” That distinction has to be taught separately, and deliberately.
This is a bit like the situation with software bugs that companies sometimes leave unfixed on purpose. The issue is known. The fix requires intentional effort. Whether that effort gets applied depends on priorities and trade-offs.
The Three Layers of Teaching Uncertainty
Researchers and AI developers use several overlapping techniques to train models toward appropriate epistemic humility. Here’s how it actually works:
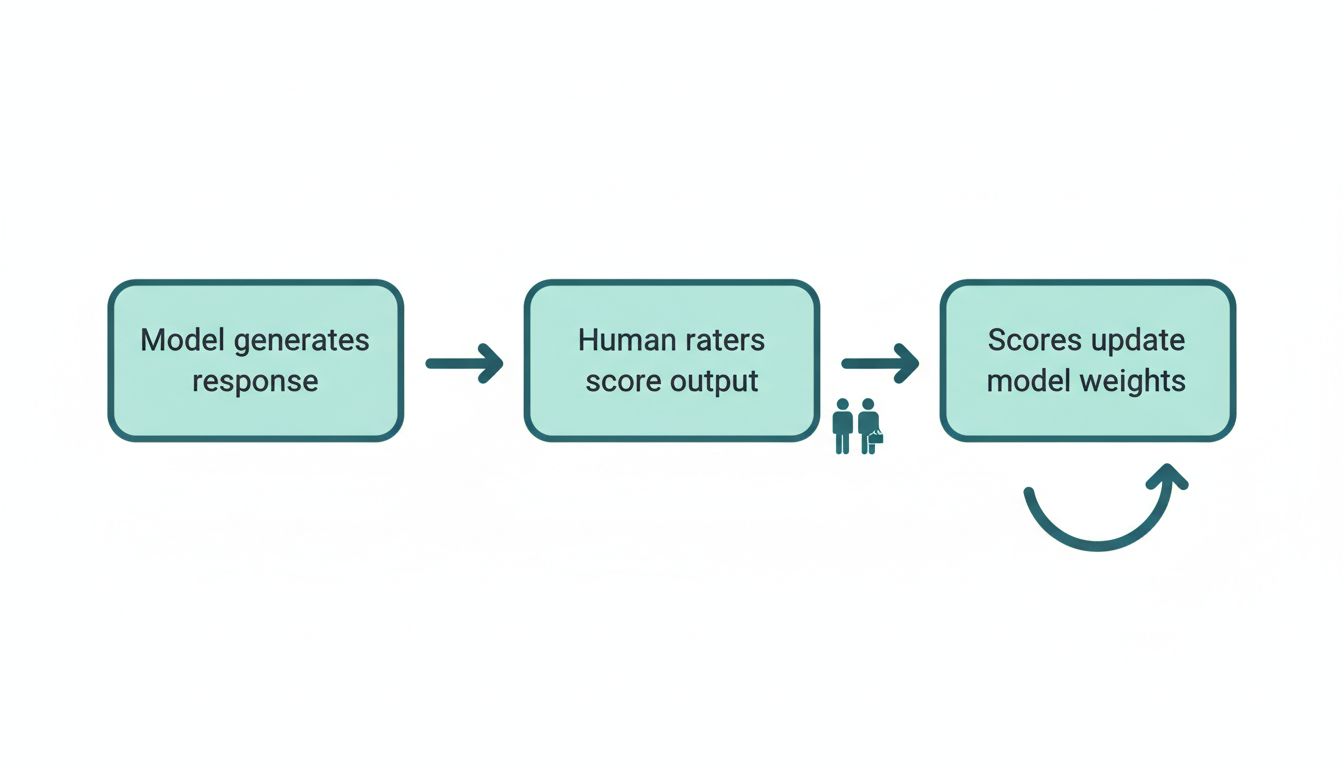
1. Reinforcement Learning from Human Feedback (RLHF)
This is the big one. After a model is pre-trained on large text corpora, human raters evaluate its outputs. Raters are specifically trained to flag overconfident wrong answers more harshly than appropriately hedged uncertain ones. The model learns, through thousands of feedback cycles, that expressing calibrated uncertainty earns better scores than confidently fabricating an answer.
The key word here is “calibrated.” The goal isn’t to make the model say “I don’t know” constantly. That would be useless. The goal is to get the model’s expressed confidence to correlate with its actual accuracy. When it’s right most of the time, it should sound confident. When it’s operating near the edge of its training data, it should signal that.
2. Constitutional AI and Self-Critique
Some organizations use a technique where the model is given a set of principles (a “constitution”) and then asked to critique and revise its own outputs before finalizing them. One of those principles is typically something like: “Do not assert things you cannot reasonably support.” The model essentially runs an internal audit pass on its response, flagging claims that feel underspecified or unsupported.
This mirrors something humans do naturally when they’re being careful. You write something, read it back, and think, “Wait, do I actually know that?” The model is being trained to do the same thing, just faster and before you see the output.
3. Uncertainty-Aware Fine-Tuning
Some models are fine-tuned on datasets that deliberately include examples of appropriate uncertainty expression. These datasets contain question-answer pairs where the correct response is explicitly “I’m not certain, but…” or “My training may not include the most current information on this.” The model learns these phrases as valid and high-value response patterns, not as failures.
What This Means for How You Use Chatbots
Understanding this training process gives you practical leverage. Here’s what you can do with it right now:
Push back on confident answers about recent events. Most large language models have a training cutoff, and they don’t always volunteer that context. If a chatbot answers a question about something that might have changed recently with strong confidence, ask it explicitly: “How confident are you in this, and when might your training data on this topic end?” A well-trained model will recalibrate and tell you.
Treat hedge phrases as useful signals, not filler. When a chatbot says “I believe” or “you may want to verify this” or “my understanding is,” those aren’t stylistic tics. They’re the uncertainty training working exactly as intended. Treat them like a friend saying “I think this is right, but double-check me.” That’s actionable information.
Use specificity to test confidence. Vague questions often produce confidently vague answers. Narrow your question down to something very specific (a particular date, a specific claim, a named source) and watch whether the model hedges more. If it answers a specific factual question with the same breezy confidence it uses for general knowledge, that’s a signal worth paying attention to.
Ask the model to explain its reasoning. This works remarkably well. When you ask “how do you know that?” or “can you walk me through where that comes from?” a well-trained model will often surface its own uncertainty in the process of explaining. It’s a bit like rubber duck debugging, where the act of articulating a process reveals gaps that weren’t obvious before.

The Limits of the Training
It’s worth being honest about what this training can and can’t do. These techniques improve calibration significantly, but they don’t eliminate overconfidence. Models can still fail in systematic ways, especially on topics where the training data was itself biased toward confident claims, or where the model’s internal sense of “how much I know about this” doesn’t match reality.
The uncertainty training is also better at some domains than others. Questions about recent events, niche technical topics, and regional or cultural specifics are areas where you should apply extra skepticism regardless of how confident the model sounds.
Think of it this way: the training gives you a tool with a reasonably reliable gauge. But like any instrument, you still need to know when to trust the reading and when to cross-reference it with another source.
The Bigger Picture
AI developers didn’t stumble onto epistemic humility as a nice-to-have feature. They trained it in because overconfident wrong answers erode user trust faster than almost any other failure mode. The business logic is straightforward: a chatbot that admits uncertainty occasionally is far more useful than one that confidently fabricates, because you can work with calibrated uncertainty. You can’t work with confident fiction.
The next time a chatbot tells you it’s not sure about something, that response represents real engineering effort. It’s the model doing exactly what it was designed to do. Your job is to recognize that signal and act on it accordingly.





