
The Counterintuitive Core of Modern AI Training
If you asked most people how to build an accurate AI model, they’d say: give it the best, cleanest, most accurate data you can find. It seems obvious. Garbage in, garbage out. The phrase is practically a proverb in computing.
The reality of how state-of-the-art models are actually trained is more interesting, and initially harder to accept. Researchers routinely and deliberately corrupt their training data. They add noise, flip labels, drop entire chunks of input, mask words, and introduce systematic errors. This is not a workaround for imperfect datasets. It is a core technique, and the models trained this way consistently outperform models trained on cleaner data.
Understanding why this works requires rethinking what “accuracy” actually means in a machine learning context.
What Overfitting Actually Looks Like
Before getting into the deliberate corruption techniques, it helps to understand the failure mode they’re designed to prevent: overfitting.
A model that overfits has essentially memorized its training data. It can reproduce answers from the training set with near-perfect accuracy, but ask it something slightly different and it falls apart. The classic analogy is a student who memorizes every practice exam answer verbatim but can’t solve a new problem because they learned the specific questions, not the underlying concepts.
In machine learning terms, an overfit model has learned the noise in its training data alongside the signal. Every real-world dataset contains quirks, flukes, and artifacts specific to how it was collected. If the model treats these as meaningful patterns, it becomes brittle. It performs beautifully in the lab and poorly in deployment.
The field has known about overfitting since the early days of neural networks. What took longer to fully appreciate was how deliberately introducing new, structured forms of noise could actually immunize models against this problem.
Dropout: Teaching Models to Work Without Their Best Tools
One of the most elegant examples of deliberate corruption is dropout, introduced by Geoffrey Hinton and colleagues in a 2012 paper and now ubiquitous in neural network training.
The mechanism is almost aggressively simple. During each training pass, a random subset of neurons in the network is temporarily disabled, set to zero, switched off. The network has to make predictions without them. Then they come back, a different subset is dropped, and the process repeats.
What this forces is a kind of redundancy. Because any given neuron might not be available on any given training pass, the network can’t learn to rely on small clusters of neurons doing all the heavy lifting. Every part of the network is pushed to carry useful information independently. When you then run the full network at inference time (with all neurons active), you effectively get an ensemble of many differently-configured sub-networks all voting at once.
The deliberate wrongness here is destroying part of the network’s input on purpose during every training step. You are, by definition, training on degraded versions of your data. The result is more robust, more generalizable models. Dropout reduced error rates on standard image classification benchmarks when it was introduced, a meaningful improvement that has held up across years of follow-on research.
Data Augmentation: When Mistakes Are the Point
Dropout operates inside the network. Data augmentation operates on the data itself, and it’s where the “deliberate wrongness” framing becomes most literal.
For image recognition models, data augmentation means taking training images and systematically corrupting them before the model sees them: rotating them, flipping them horizontally, cropping random sections, adjusting brightness and contrast, adding Gaussian noise, or blurring them. The label stays the same. A dog with the contrast cranked up is still labeled “dog.”
This is unambiguously feeding the model wrong data in a technical sense. The pixel values have been altered. The image is not what it was. The model is being trained on fabricated inputs.
It works because the real world is also full of imperfect inputs. A camera might be slightly overexposed. The subject might be at an odd angle. The model that trained only on pristine, perfectly-lit, centered images will fail when deployed against actual photographs. The model that trained on thousands of variations of every image has already encountered most of the ways reality can deform a picture.
This extends well beyond images. Text models are trained with random word deletions, synonym substitutions, and character swaps. Audio models are trained with background noise added and pitch shifted. In each case, the training input is deliberately worse than the best available version of that input.
BERT and the Radical Power of Masking
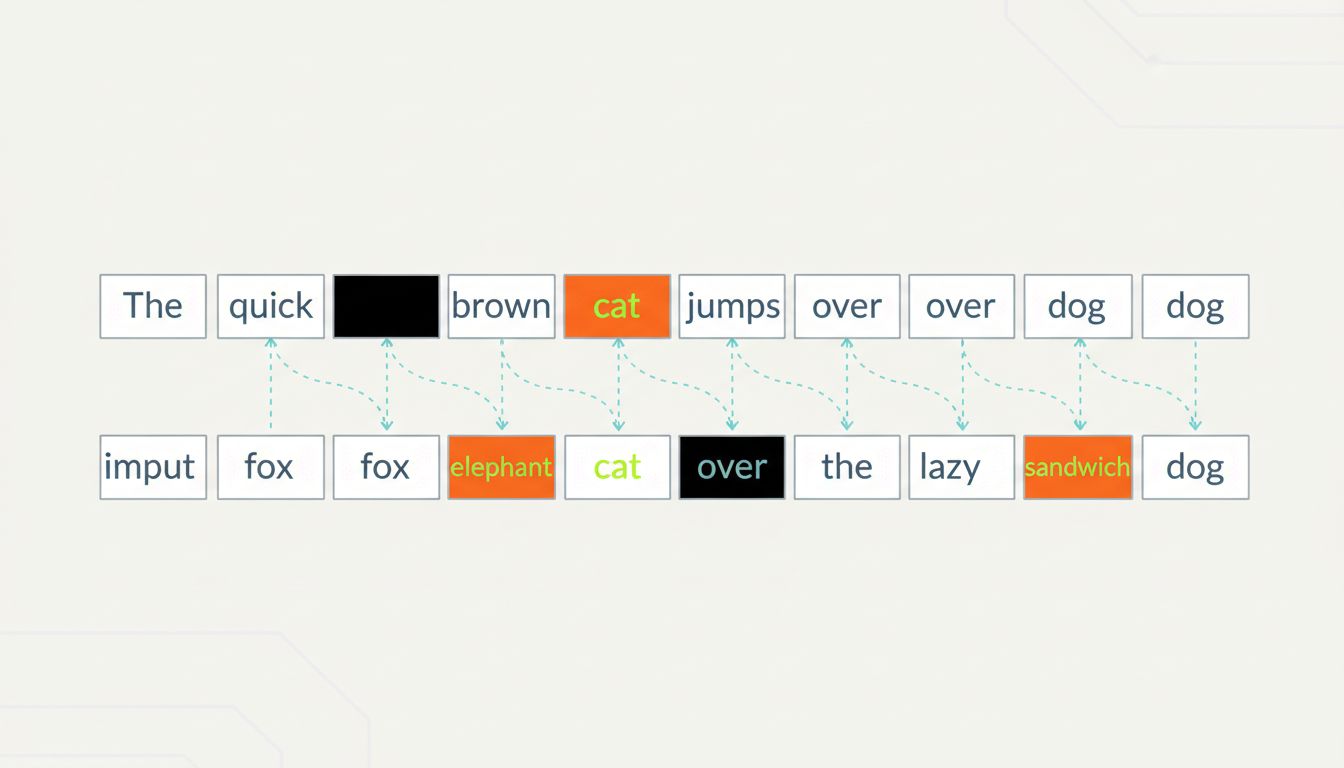
The most influential application of deliberate data corruption in recent AI history is probably masked language modeling, the pretraining technique behind BERT (Bidirectional Encoder Representations from Transformers), published by Google researchers in 2018.
BERT’s pretraining task is constructed entirely around deliberate wrongness. Take a sentence. Randomly select 15% of the tokens (roughly, words or word-pieces). Replace 80% of those selected tokens with a special [MASK] token, replace 10% with a random wrong word, and leave the remaining 10% unchanged. Now ask the model to predict what the original tokens were.
The model is given corrupted text and asked to reconstruct the uncorrupted version. The training signal comes entirely from this reconstruction task, which requires the model to develop a deep, contextual understanding of language. To predict a masked word correctly, you have to understand grammar, semantics, and the relationships between words across a sentence.
The 10% random-word substitution is particularly clever. If the model only ever saw [MASK] tokens marking missing positions, it might learn to only apply its contextual reasoning when it sees that marker. By also replacing some tokens with random words silently, without any [MASK] indicator, the model is forced to consider context for every single token, not just the obviously marked ones.
BERT’s pretraining approach produced models that, when fine-tuned on specific tasks, outperformed previous state-of-the-art results across a wide range of natural language benchmarks. The foundation of that performance was a training process built on systematically corrupted inputs.
Why This Works: The Signal in the Noise
The underlying principle connecting all these techniques is the same, even though they operate at different levels.
When you corrupt data deliberately and ask a model to perform despite that corruption, you force it to learn invariances. An image model that’s been trained on rotated dogs learns that dogness doesn’t depend on orientation. A language model trained on masked text learns that word meaning depends on surrounding context. A network trained with dropout learns that any single neuron is expendable.
These invariances are exactly what you want in a model that has to handle real-world inputs. The real world does not send you clean, perfectly formatted, ideally structured data. It sends you whatever it sends you. A model that has only ever practiced on ideal conditions is like a surgeon who has only practiced on perfect anatomical specimens. Technically trained, practically fragile.
There’s also an information-theoretic angle. Clean, redundant data can be “explained” by many different models. Adding structured noise forces the model to find the hypotheses that are robust across many different versions of the data, which tend to be the hypotheses that are actually capturing real underlying patterns rather than surface artifacts.
The Limits and the Open Questions
None of this means more corruption is always better. These techniques require careful calibration. Too much dropout and you’re just training noise. Too aggressive masking and the reconstruction task becomes impossible, providing no useful gradient signal. Data augmentation that transforms images beyond recognition doesn’t help a model recognize real images.
There are also domains where deliberate corruption is harder to implement without domain expertise. Medical imaging, for instance, requires care about which augmentations are physically realistic. Flipping a chest X-ray horizontally might be fine for training purposes, but rotating it 90 degrees produces an input that would never appear in clinical practice, and training on it might teach the model something useless.
The field is also still developing a rigorous theoretical account of exactly why noise-based regularization works as well as it does. The empirical evidence is overwhelming. The mechanistic explanation is still being worked out. That’s a gap researchers are actively trying to close.
What This Means
The deliberate corruption of training data is now a foundational part of how modern AI systems are built. Dropout appears in nearly every serious neural network architecture. Data augmentation is standard practice in computer vision. Masked language modeling underlies most of the large language models that have become culturally prominent in the past few years.
The through-line is counterintuitive but consistent: a model that has only ever seen ideal data will fail when it meets reality, because reality is not ideal. Training on imperfect, corrupted, and deliberately broken versions of your data is not a compromise you make when good data isn’t available. It is a principled strategy for building systems that generalize.
The “garbage in, garbage out” proverb isn’t wrong exactly. It just turns out that some carefully chosen garbage is load-bearing.





