

A large language model can synthesize a 10,000-word literature review, translate between 50 languages, and pass the United States Medical Licensing Exam in the 90th percentile. Ask it how many letters are in the word “strawberry,” and a significant portion of leading models will tell you there are two r’s. There are three. A child who can barely tie their shoes would not make that mistake. This is not a bug waiting to be patched. It is a window into something fundamental about how AI systems are built, and what intelligence actually means.
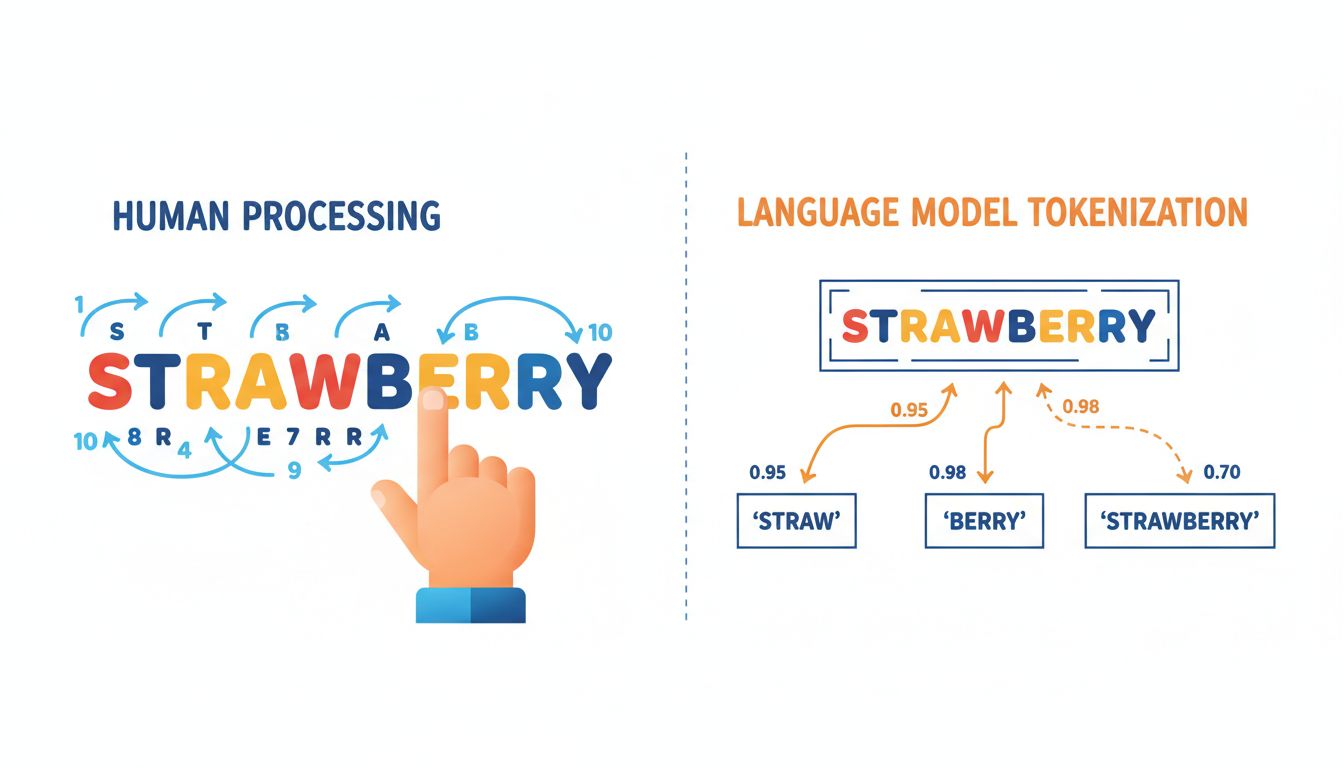
The gap is jarring precisely because we tend to think of intelligence as a single spectrum, where something that can do hard things should obviously be able to do easy things. But that assumption is wrong, and understanding why tells us a great deal about where AI is headed, and where it is likely to stay stuck for a long time. As we explored in our piece on why AI models give different answers to the same question every time, the probabilistic foundations of these systems create failure modes that are invisible from the outside but structurally baked in.
The “Strawberry Problem” Is Not a Trivia Issue
Let’s be precise about what is happening when an AI miscounts letters. A language model does not read text the way you do. It processes tokens, which are chunks of text that roughly correspond to syllables or common word fragments. The word “strawberry” might be tokenized as “straw” + “berry,” or some similar split. When you ask the model to count letters, it is not inspecting individual characters the way a child would, pointing to each letter with a finger. It is making a statistical inference about what a correct-sounding answer looks like, based on patterns in training data.
This is the core architectural issue. Large language models are extraordinary pattern matchers. They are not symbolic reasoners, and they do not maintain an explicit working memory that they can inspect step by step. A five-year-old counting letters is performing a genuinely different cognitive operation: sequential, deliberate, grounded in physical reality. The AI is doing something that looks similar from the outside but is mechanically alien underneath.
Spatial Reasoning and the World That Does Not Exist in Text
Letter counting is just one flavor of failure. Ask a state-of-the-art model to reason about physical space and things get worse. Classic examples include: if you stack a book on a cup on a plate, what is touching the table? Which way does water drain if you turn a bathtub upside down? These are tasks children solve instinctively by age four or five, using embodied intuition built from years of physically interacting with objects.
AI systems trained on text have never touched anything. They have read descriptions of physics, but descriptions and experiences are not the same thing. This is sometimes called the “grounding problem,” the gap between a symbol and the physical reality it refers to. A child knows that “heavy” means something specific because they have struggled to lift things. A language model knows that “heavy” co-occurs with words like “dense” and “difficult to move,” which is a shadow of knowledge, not the thing itself.
Multimodal models trained on images and video close some of this gap, but the problem runs deeper than adding more data types. It is about the structure of learning, not just its inputs. We covered a related dynamic in our piece on why more training data sometimes makes AI systems worse, where increasing volume can actually entrench certain failure modes rather than resolve them.
Common Sense Is Uncommon Data
Here is a task that trips up most AI systems but not any neurotypical adult: “A man walks into a restaurant and orders a steak. The waiter brings him a bowl of soup. What should the man do?”
Obviously, the man should say something. He ordered steak, not soup. But to know this, you need an enormous implicit framework about how restaurants work, what ordering means, what the social contract between customer and server entails, and that people generally want what they asked for. None of this needs to be stated explicitly to a human, because humans have lived in the world. Almost all of it needs to be either explicitly stated or somehow inferred for an AI.
This is why “common sense” benchmarks consistently reveal yawning gaps between AI performance and human performance, even when the same AI is outperforming humans on specialized professional tests. Common sense is not a simple thing that just needs better prompting. It is the accumulated residue of being an embodied agent living in a shared social and physical world. Training on text is an indirect and lossy way to acquire it.
The tech industry tends to treat this as a scaling problem, assuming that more compute, more data, and more parameters will eventually bridge the gap. Some researchers are skeptical. Gary Marcus, a cognitive scientist and prominent AI critic, has argued for years that the architecture of current models has fundamental ceilings that scaling alone cannot overcome. Whether he is right remains genuinely contested, but the failure modes are real and reproducible right now.
Why This Matters Beyond Party Tricks
It is tempting to treat the “AI can’t count letters” observation as a charming quirk, something to post about on social media and then forget. But the same structural limitations that cause letter-counting failures also cause more consequential errors in high-stakes domains.
Medical AI systems have been shown to fail on basic logical inference about patient histories. Legal AI tools miss reasoning steps that any first-year law student would catch. Navigation AI struggles with novel physical configurations. In each case, the failure traces back to the same root: these systems are optimizing for plausible-sounding outputs rather than grounding their reasoning in verifiable, step-by-step logic.
The digital transformation projects that fail 84% of the time often fail for exactly this reason: organizations deploy AI tools assuming capability in domains where the architectural limits make reliable performance impossible. They are solving the wrong problem, which is assuming AI is a general intelligence when it is a highly specialized and brittle pattern-matcher with impressive range but structural blind spots.
What Actually Needs to Change
The most promising approaches being explored are hybrid architectures, systems that pair language models with symbolic reasoning engines, explicit working memory, and in some cases robotic embodiment. Neuro-symbolic AI, which blends neural networks with rule-based logic systems, is one active research direction. OpenAI’s “reasoning models” like the o-series attempt to simulate chain-of-thought reasoning more explicitly, with measurable improvements on logic tasks, though they still stumble on tasks requiring physical intuition.
None of this diminishes what current AI systems can do. The ability to synthesize information, assist with writing, generate code, and surface patterns in large datasets is genuinely useful, and commercially significant. But we should be precise about what we are praising. A five-year-old who can count the letters in “strawberry” has something no current AI model reliably has: a grounded, embodied, causally structured model of the world. That is not a small thing. It is, arguably, the thing.
The honest framing is not “AI is dumb” or “AI is a fraud.” It is that current AI systems are a specific kind of intelligence, optimized for a specific kind of task, with specific and sometimes surprising failure modes. Knowing exactly where the edges are is what separates useful deployment from expensive disappointment.





