The marketing around large context windows has gotten wildly ahead of the engineering. When Anthropic announced Claude’s 100,000-token context window, the coverage treated it like RAM: more space, more capacity, better performance. Pour in a whole codebase, a legal contract, a year of emails, and the model will reason across all of it with equal fidelity. That framing is wrong, and building on it leads to genuinely bad software decisions.
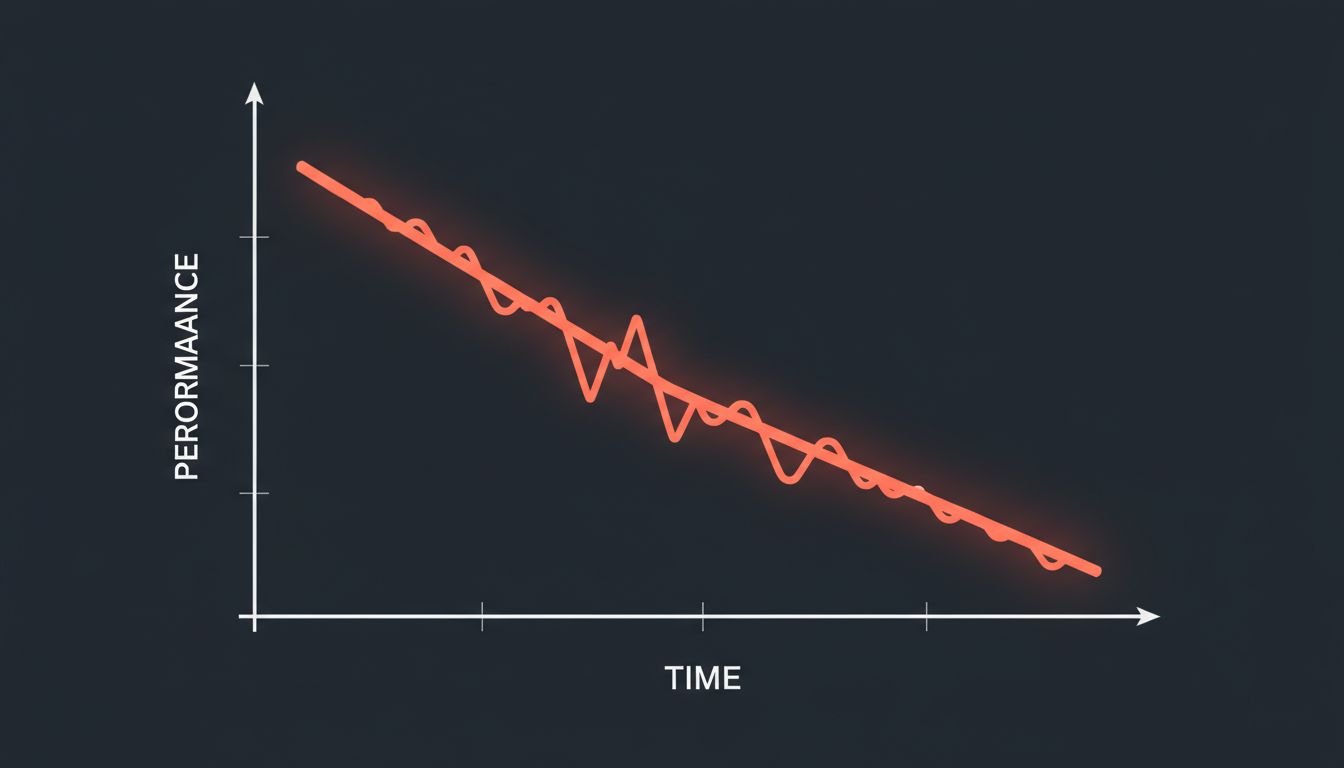
My position is simple: large context windows are a capability with a sharp performance curve attached, not a flat storage medium. The model does not treat token 500 the same as token 50,000. Understanding why changes how you should architect anything that depends on this technology.
What Attention Actually Does to Long Inputs
Transformers work through a mechanism called self-attention, where every token in the context is compared against every other token to figure out what’s relevant to what. The output for any given token is a weighted sum across all other tokens, where the weights represent relevance. Conceptually, it’s like asking every word in your input to vote on which other words matter most for understanding it.
This is powerful, but it has a physics problem. The computational cost of attention scales quadratically with sequence length. Double the context, quadruple the work. Engineers have developed approximations and architectural tricks (sparse attention, sliding window attention, and others) to make long contexts tractable, but these approximations are not free. They involve tradeoffs, usually around which parts of the context the model attends to most precisely.
The practical result is that attention is not uniform across 100,000 tokens. Models consistently show stronger recall and reasoning for content near the beginning and end of a long context. The middle degrades. Researchers who study this call it the “lost in the middle” problem, and it has been documented empirically across multiple model families. If your critical information lives at token 45,000 of a 90,000-token prompt, you are gambling.

More Context Can Actively Hurt
This is the part that should give every developer pause. Adding context to an LLM prompt is not a neutral act. Irrelevant or redundant content doesn’t just get ignored the way a search engine might ignore low-scoring documents. It introduces noise that the attention mechanism has to work against, and sometimes loses to.
Imagine you’re asking a model to find a specific function signature in a 10,000-line codebase dump. The model has to distribute its attention budget across all of that context. The relevant 20 lines of code compete with 9,980 lines of unrelated logic, comments, and boilerplate. Compare that to a retrieval-augmented approach where you surface just the relevant file and its immediate dependencies. The focused prompt frequently outperforms the exhaustive one. More context for your AI model can make it dumber is a real phenomenon, not a counterintuitive edge case.
The Compression Problem No One Talks About
Here’s the deeper issue. Human memory doesn’t work like a hard drive either. When you read a 400-page book, you don’t store every sentence verbatim. You compress it into a mental model: themes, arguments, character arcs, key facts. You can reason about the whole because you’ve built an abstraction over the parts.
LLMs do something structurally different. They process the entire context in a single forward pass and produce a response. There’s no iterative re-reading, no building of a separate summary structure, no flagging of sections for later review. The 100,000 tokens flow through the network all at once, and whatever synthesis happens, happens in that single computational sweep. For short contexts, this works beautifully. For very long ones, you’re asking the model to hold an enormous amount in attention simultaneously and reason coherently across it. Sometimes it does. Often, subtle connections across distant parts of the context get dropped.
If you need a model to reason about a very long document, chunking it, summarizing sections, and building up a hierarchical representation will frequently outperform raw context stuffing. This is more engineering work, but it maps better to how coherent reasoning about large information sets actually works.
The counterargument
The fair pushback here is that models are improving fast, and some benchmarks do show strong long-context performance. Google’s Gemini 1.5 Pro demonstrated impressive recall on needle-in-a-haystack tasks at one million tokens. You can construct demonstrations where long-context models do surprising things correctly.
I don’t dismiss this. The capability is real and improving. But benchmark performance on retrieval tasks (finding a specific fact buried in a document) is different from benchmark performance on reasoning tasks (drawing non-obvious inferences across multiple sections of a long document). The latter is much harder and the gap is much larger. And production systems live in the reasoning world, not the retrieval world. You’re not paying for an LLM to find a word in a document. You’re paying for it to understand what the document means and act on it intelligently.
Build for the Curve, Not the Ceiling
The 100,000-token context window is a real technical achievement, and it’s genuinely useful. Whole-document summarization, long-form editing, multi-file code review: these are legitimate applications where large context meaningfully helps. The mistake is treating the context limit as a measure of capability rather than a constraint to engineer around.
The model’s attention is a budget. Spend it deliberately. Put critical information near the beginning or end of your prompts. Use retrieval to surface relevant content rather than dumping entire corpora. Test with adversarial inputs where the key information is buried, not just cases where it’s prominent.
The engineers building serious applications on top of these models already know this. They’re building retrieval pipelines, rerankers, and chunking strategies precisely because they’ve watched raw context stuffing fail in production. The context window is the ceiling. Your architecture determines how close to the ceiling you actually get to operate.