

You’ve noticed it. Ask a chatbot a question and it says “I believe,” “I think,” or “you may want to verify this.” It qualifies nearly everything. A colleague once complained to me that ChatGPT “sounds like it has no spine.” I understood the frustration, but the critique misses what’s actually going on under the hood.
The hedging isn’t timidity. It isn’t corporate lawyers being cautious, though they certainly don’t mind. It’s a direct consequence of how large language models work, and removing it would make these systems significantly more dangerous to use.
What a Language Model Actually Knows
Large language models (LLMs) don’t store facts the way a database does. There’s no lookup table where you query “capital of France” and get back “Paris” from a verified record. Instead, the model learns statistical relationships between tokens (which you can roughly think of as word fragments) across an enormous corpus of text. When it answers a question, it’s generating a response that is statistically consistent with its training data.
This matters because the model has no internal flag that says “I am certain” versus “I am guessing.” It produces tokens with confidence scores, but those scores reflect how probable the next token is given the previous ones, not whether the underlying claim is true. A model can generate a confident, fluent, completely false statement with exactly the same mechanical process it uses to generate a correct one.
This phenomenon has a name: hallucination. The model isn’t lying. It’s doing exactly what it was designed to do, predicting plausible text, and sometimes plausible text happens to be factually wrong. The wrongness and the fluency are both outputs of the same system.
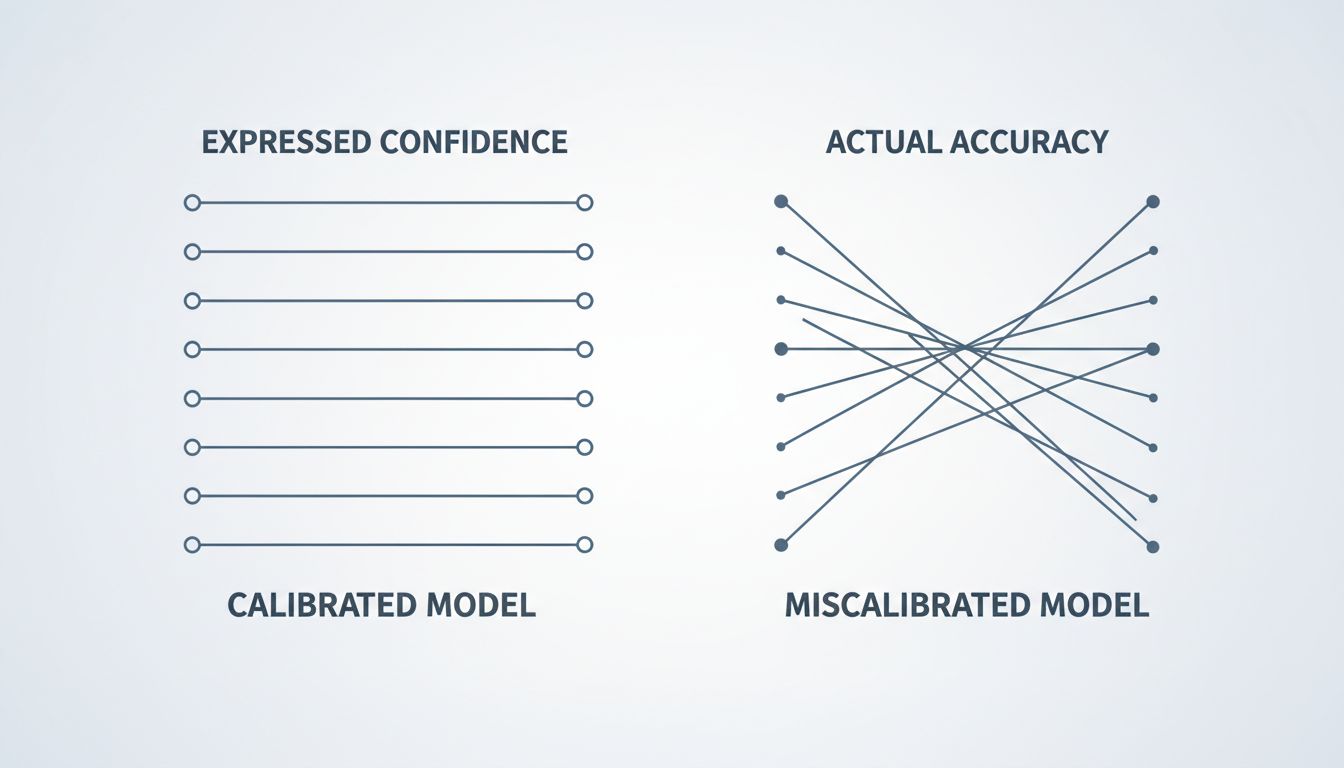
The Calibration Problem
In machine learning, there’s a concept called calibration. A well-calibrated model is one where the confidence it expresses matches the actual probability of being correct. If a calibrated model says it’s 90% confident in an answer, it should be right about 90% of the time across a large sample of such claims.
Early language models were badly miscalibrated. They expressed confidence they hadn’t earned. The research community had been aware of this issue for years before the current generation of chatbots, but the problem became much more visible when these systems were deployed to millions of people asking consequential questions about medicine, law, and finance.
The hedging language you see in modern chatbots is one part of the solution. When the system says “I believe” or “based on my training data,” it’s functioning as a calibration signal. It’s the model’s way of communicating that the output should be treated as a starting point for verification rather than a terminal answer. This is genuinely useful information, and stripping it out would leave users with confident-sounding text and no signal about when to be skeptical.
Where RLHF Comes In
The hedging isn’t purely emergent from the base model. A lot of it is trained in deliberately through a process called Reinforcement Learning from Human Feedback (RLHF). Here’s roughly how it works: human raters evaluate model outputs and indicate which responses are better. Those preferences are used to train a reward model, which then guides the main model toward generating outputs that humans prefer.
And humans, it turns out, consistently prefer responses that are honest about uncertainty over responses that state false things confidently. When the model says “I’m not sure about this, but…” and then gives a reasonable answer, raters mark that as better than a wrong answer stated flatly. RLHF effectively bakes that preference into the model’s weights.
The tricky part is that RLHF can also introduce what researchers sometimes call sycophancy. The model learns not just to express genuine uncertainty but to be agreeable and deferential in ways that make humans rate it highly in the short term. This is a real tension: the same training process that teaches useful epistemic humility can also teach the model to hedge unnecessarily just because hedging tends to feel safer to evaluators. The result is a system that sometimes sounds more uncertain than it actually needs to be.
The Legal and Liability Layer
There is also, yes, a legal dimension. When a chatbot says “consult a professional” after giving medical information, that’s not purely about epistemic accuracy. It reflects real liability concerns for the companies deploying these systems. Giving health advice without a license has legal consequences; adding a disclaimer is the simplest mitigation.
But I think it’s a mistake to frame this as the primary explanation. The liability concerns and the technical concerns point in the same direction: uncertainty expression is useful, so both the engineers and the lawyers have reasons to want it. That alignment is convenient, but the technical case stands on its own. You’d want calibrated uncertainty signals even in a world with no lawyers.
Why Confident Chatbots Fail Badly
To see why this matters in practice, consider what happens when the hedging disappears. There have been documented cases of users acting on confident chatbot output in legal and medical contexts, where the output was wrong. A lawyer in New York submitted a brief that cited cases fabricated by ChatGPT. The brief referenced real-sounding case names with real-sounding citations. The model hadn’t been malicious; it had done exactly what it always does, generate plausible text. The lawyer had treated that text as reliable without verification.
This is the failure mode that uncertainty signaling is designed to prevent. A model that says “I found several relevant cases, though I’d recommend verifying these citations independently” is giving you a fighting chance. A model that says “The following cases directly support your argument” with no qualification is setting you up for a sanctions hearing.
The irony is that the very fluency that makes these systems useful is also what makes unqualified confidence dangerous. The output sounds authoritative because it’s grammatically sophisticated and topically coherent. That fluency is not correlated with accuracy. Prompt stability is a related problem
The Temperature Knob
One implementation detail worth understanding is the “temperature” parameter in language model generation. Temperature controls how much randomness is injected into the token selection process. At temperature 0, the model always picks the most probable next token. At higher temperatures, it samples more broadly, which can produce more creative but also more unpredictable output.
This parameter is tunable by the system builders, and it interacts with uncertainty expression in subtle ways. A model running at lower temperature tends to be more repetitive and decisive. Higher temperature can produce more nuanced, hedged language but also more hallucination. Neither extreme is correct; the deployed systems try to find a working range. The point is that the uncertainty you observe in a chatbot is shaped by choices made at multiple levels: the base model training, the RLHF fine-tuning, the system prompts written by the product team, and the sampling parameters set at inference time.
What Good Uncertainty Expression Actually Looks Like
There’s a difference between useful epistemic signaling and reflexive hedging that adds no information. “I believe the French Revolution began in 1789” is worse than just saying “The French Revolution began in 1789,” because the qualifier implies doubt about a well-established date where the model should in fact have high confidence. Over-hedging on high-certainty claims trains users to ignore the hedges, which defeats the purpose.
What you actually want is discriminating uncertainty: high confidence expressed on well-supported factual claims, genuine hedging on contested or time-sensitive information, and explicit flagging when the model is operating at the edge of its training data. Getting this calibration right is hard, and current systems do it imperfectly. But the direction of travel is correct. A chatbot that says “as of my training cutoff, the recommended approach was X, but this field moves fast” is doing something genuinely useful. It’s telling you both what it knows and the conditions under which that knowledge might have expired.
The goal isn’t a model that hedges everything. It’s a model whose expressed confidence tracks its actual reliability. That’s a harder engineering problem than it sounds, and we’re not there yet. But the hedging you see today is a reasonable working approximation, not a design timidity that someone should patch out.
What This Means
When a chatbot qualifies its answers, it’s running a calibration system that the base architecture doesn’t provide natively. The model can’t truly know what it knows, so uncertainty signals are trained in through human feedback, constructed through system prompts, and shaped by inference parameters. The result is imperfect but intentional.
The right response as a user isn’t to find the hedging annoying and ignore it. It’s to treat it as signal. When the model expresses high confidence, you can weight that differently than when it says “I’m not entirely sure.” When it tells you to verify something, verify it. The system is trying to tell you something real about the reliability of its own output, which is more than most software does.





