
The Bug You Didn’t Think Of Is the One That Hits Production
Every developer has written code that worked perfectly under the conditions they imagined. The function handles a user ID, so you pass it a user ID. The API returns a status field, so you read the status field. The number is always positive, so you skip the check. Then a user does something unexpected, the API has a bad day, and suddenly you have a negative inventory count and an on-call rotation that ruins someone’s weekend.
Defensive programming is the practice of writing code that handles conditions you didn’t specifically anticipate. Not just edge cases you can enumerate, but the entire category of “things that could be wrong about my assumptions.” It’s a fundamentally different posture from writing code that handles the happy path well. You’re not just testing for the inputs you expect. You’re building code that degrades gracefully, or fails loudly, when reality diverges from your mental model.
This isn’t pessimism. It’s engineering.
Assertions Are the Cheapest Form of Documentation That Actually Stays True
The most underused tool in defensive programming is the assertion. An assertion is a statement in your code that says: “This must be true here, and if it isn’t, something has gone badly wrong.” In Python it looks like assert user_id > 0, "user_id must be positive". In C it’s assert(buffer_len <= MAX_BUFFER). The syntax varies; the idea is universal.
What assertions really do is encode your assumptions at the moment you have them, in the place where they matter. When you write a function that processes a payment, you probably assume the amount is positive, that the currency code is a known value, that the account object isn’t null. Without assertions, those assumptions live only in your head, or maybe in a comment that nobody reads. With assertions, they live in the code, and they fire immediately when violated.
The objection I hear most often is that assertions add overhead and should be stripped out of production code. This is sometimes right and often wrong. For performance-critical inner loops, yes, disable them in production. For anything else, the overhead is negligible and the diagnostic value of a clear assertion failure, with a message telling you exactly what was wrong, is worth more than the microseconds you save. Silent failures that corrupt state downstream are orders of magnitude more expensive to debug than assertion errors that point directly at the broken assumption.
The deeper point is that assertions make your code self-documenting in a way that comments cannot. A comment can lie. An assertion that fires proves the comment would have been wrong.
Failing Loudly Is a Kindness to Your Future Self
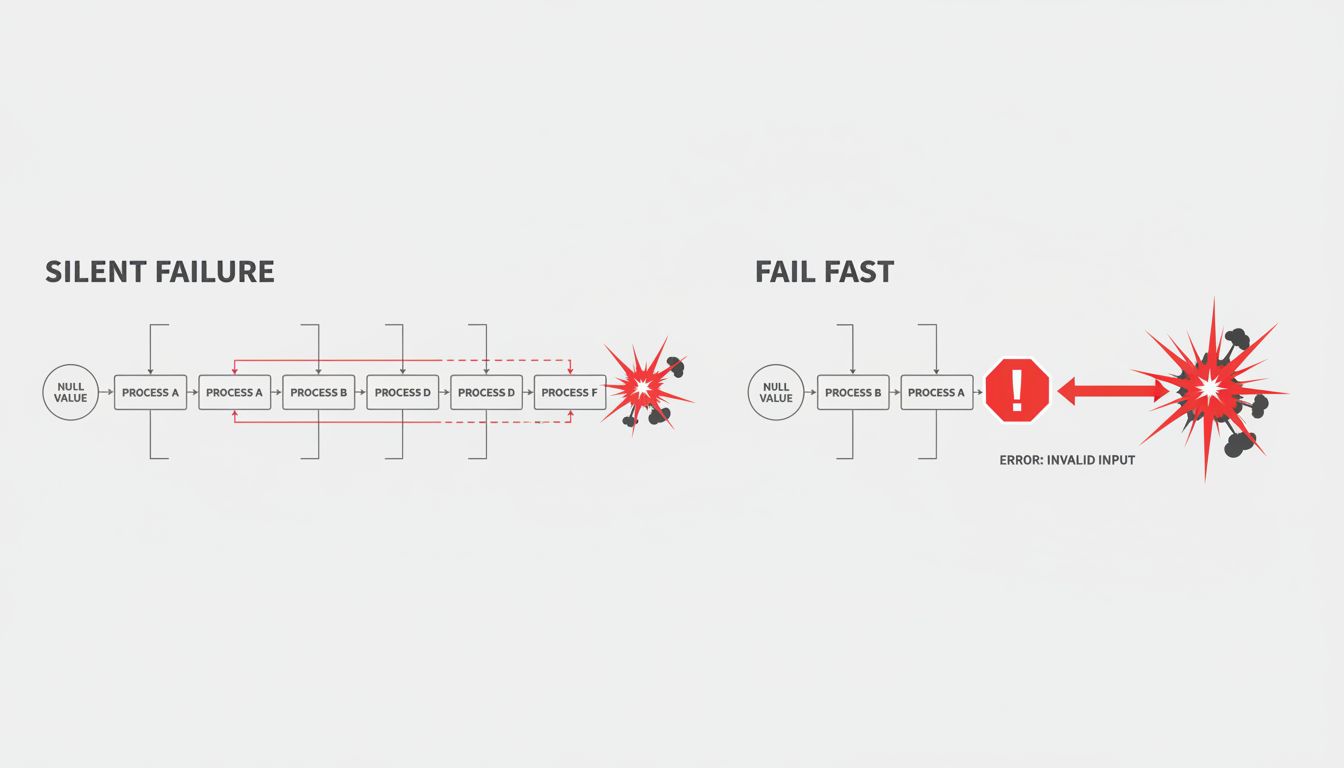
There’s a temptation in software to handle unexpected states quietly. The function gets a null where it expected an object, so it returns null. The config value is missing, so the code uses a default. The API response has an unexpected shape, so the code ignores the fields it doesn’t recognize. This feels robust. It isn’t.
Quiet failures are how you end up with bugs that never get fixed, only relocated. The null propagates through five layers of code before it causes an exception somewhere unrelated, and now you’re debugging the symptom instead of the cause. The missing config value means the system runs in a degraded state that nobody notices for weeks. The ignored API fields mean you’re making business decisions on incomplete data.
Defensive code does the opposite: it fails at the point of violation, with enough context to understand what went wrong. If a required config value is missing, throw an exception at startup with the key name and instructions for fixing it. If a function receives a type it can’t handle, raise an error immediately with the actual type it received. The pain of a loud failure at the right moment is much lower than the pain of a silent failure discovered two weeks later by a confused user.
This principle has a name in some circles: “fail fast.” The idea is that the earlier in the execution path you surface an error, the less state has accumulated around it and the easier it is to diagnose. A server that crashes on startup with a clear error message is friendlier than one that limps along in a broken state for days before anyone notices.
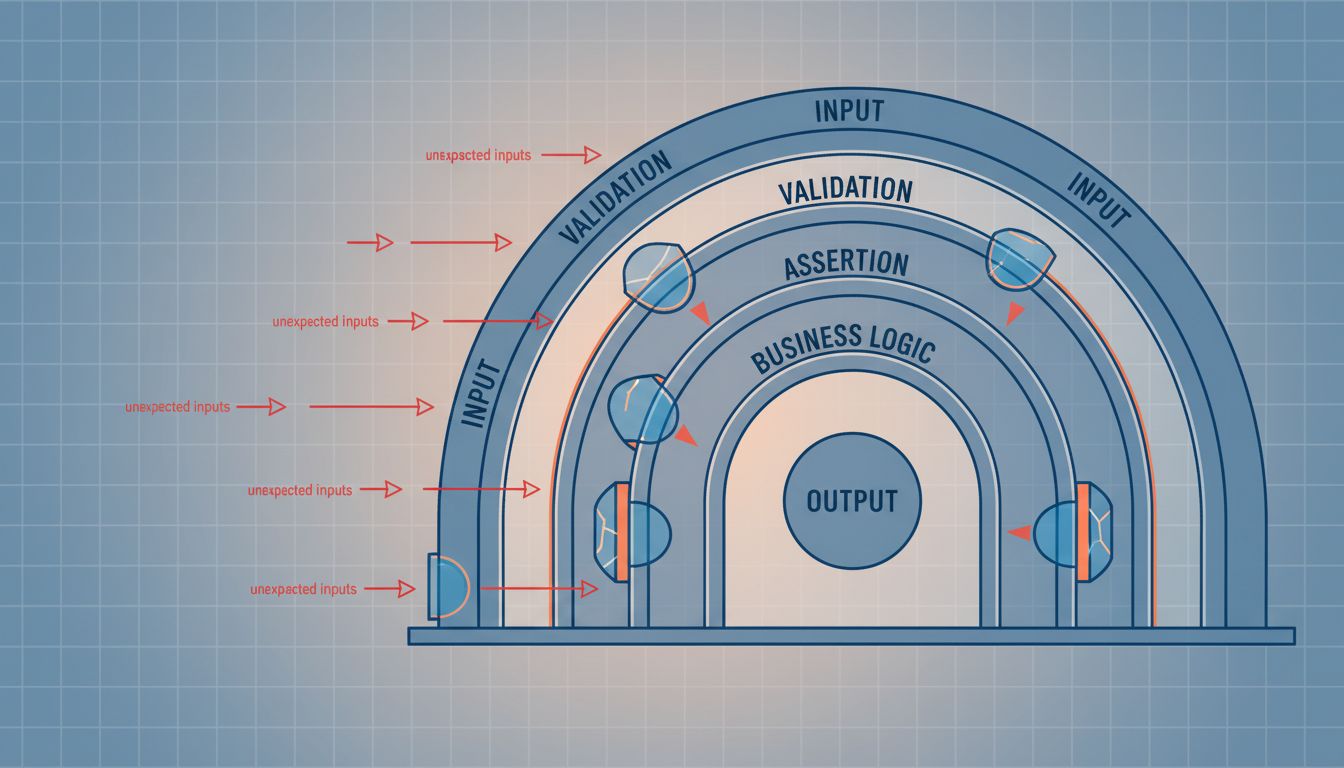
Input Validation Is Not Just About Security
Most developers learn input validation through the lens of security: sanitize user inputs, escape SQL queries, don’t trust data from outside your system. That’s correct and important. But defensive programmers apply input validation more broadly, treating the outputs of their own systems with nearly as much suspicion as external inputs.
Consider an internal microservice that fetches user preferences from a database and returns them as a dictionary. The calling service reads prefs['notification_frequency'] and uses it to schedule jobs. Straightforward enough. But what happens when a new code path in the preference service omits that key? What happens when a database migration changes the valid values? What happens when the key exists but contains a string where an integer is expected?
The defensive approach is to validate at the boundary, every boundary. When data crosses a service interface, a module boundary, or a storage layer, you check that it has the shape you expect before doing anything with it. Libraries like Pydantic in Python, Zod in TypeScript, or simple schema validators in any language make this cheap and expressive. The cost is a few lines of validation code. The benefit is that you find data shape problems at the boundary where they originate, not somewhere arbitrary inside your business logic.
This connects to a broader principle: trust is not transitive. Just because your own code generated a value doesn’t mean it’s safe to consume without checking. Systems change, migrations happen, and the version of the code that wrote the data may have had different assumptions than the version reading it.
The Practical Discipline: Making It a Habit, Not a Heroic Effort
Defensive programming fails when it’s treated as something you do after writing the real code. The assertions you’ll add later, the validation you’ll fill in once the feature works, the error handling you’ll clean up before the release. This is how you end up with production systems held together with optimism.
The developers who do this well have made it load-bearing from the start. When they write a function signature, they immediately think about what inputs would break it. When they call an external service, they immediately think about what happens when it’s slow, wrong, or unavailable. When they introduce a new data structure, they immediately write the validation that will run when data enters it.
This is a habit, not a talent. It comes from having been burned enough times that the mental model permanently includes “what could go wrong here” as a required step before moving on. Junior developers often skip this step because they’re focused on making the thing work. Senior developers do it reflexively because they’ve learned that “making the thing work” has to include making it survive contact with the conditions it will actually encounter.
The interesting thing is that defensive code is usually shorter in aggregate, not longer. The assertions and validators you add are small. The debugging sessions, incident postmortems, and data cleanup operations you avoid are enormous. The code that looks lean because it skips the checks is only lean until it isn’t.





