Dead code is a solved problem in theory. Static analysis tools flag it, linters warn about it, and every engineer you’ve ever hired has nodded along when you explained that the codebase needs to stay clean. Yet walk into almost any mature engineering org and you will find functions nobody calls, feature flags that haven’t been toggled in years, and entire modules that survive only because no one is confident enough to pull the trigger.
This isn’t laziness. Deleting dead code is genuinely one of the hardest things a team can do, and the difficulty is almost never technical.
Nobody owns it, so nobody kills it
New code has a clear author. It shows up in git blame with a name attached, a ticket number, a reason for existing. Dead code, by definition, has outlived all of that context. The person who wrote it might have left the company. The feature it supported might have been sunset so quietly that no one filed a cleanup ticket. The flag that controlled it might exist in a configuration system that three different teams nominally own and none of them actually monitor.
When ownership is diffuse, inaction is the rational choice for any individual. You could spend two days tracing the call graph, verifying nothing depends on this code, writing the PR, reviewing the PR, and shepherding it through deployment. Or you could ship the feature your manager is asking about. Most engineers will make the second choice, and you shouldn’t blame them for it.
The teams that actually delete dead code at scale have solved the ownership problem first, usually by making pruning a first-class task with a named owner on a real ticket, not a comment in Slack that says “someone should clean this up.”
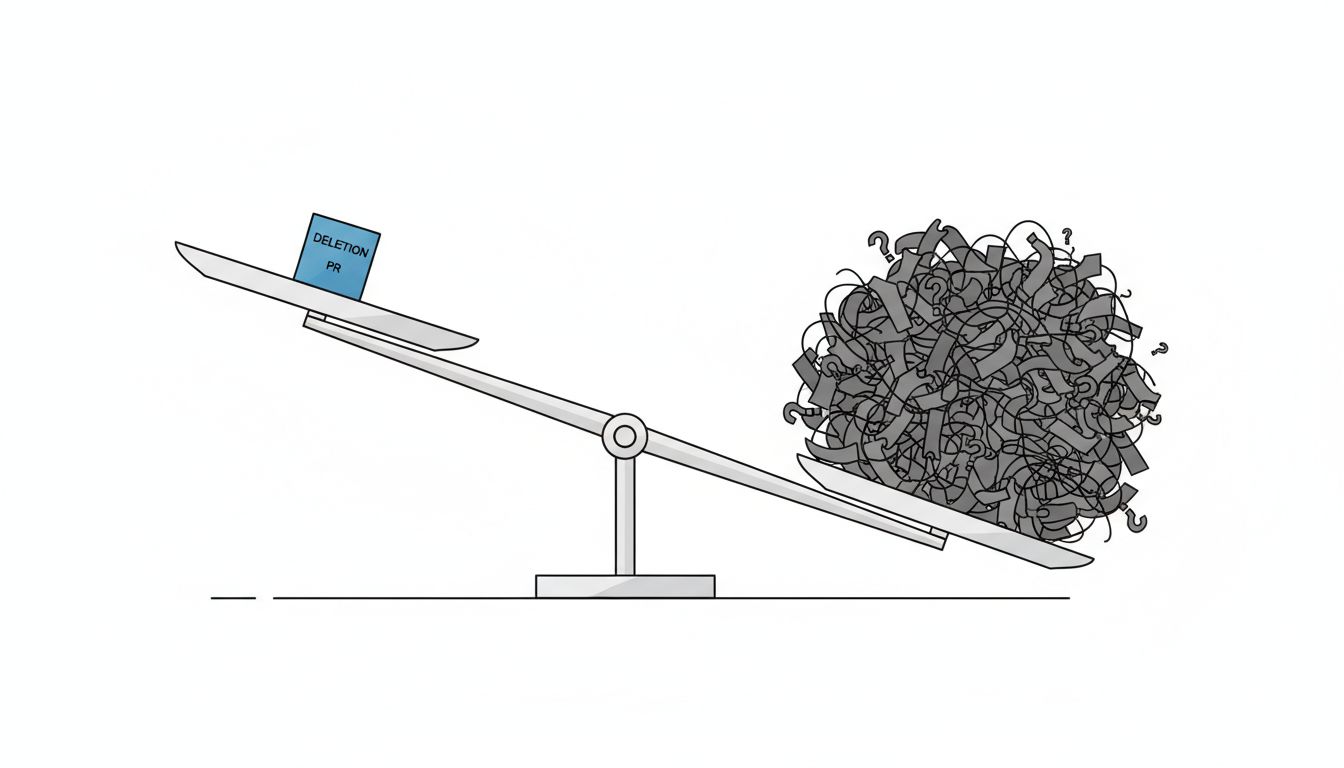
Uncertainty turns deletion into a bet
The hardest category of dead code isn’t the function that’s simply never called. It’s the function that’s called by the function that’s called by the thing that might be called during the one edge case in the payment flow that only fires on the third Tuesday of every month during a leap year.
Code that looks dead is sometimes merely dormant. And because a deletion that breaks production is a much worse outcome than a deletion that doesn’t happen, the asymmetry of consequences pushes teams toward leaving things alone. This is rational risk management applied in a way that makes the codebase worse over time.
The engineers who’ve seen staging pass and production still catch fire are not being paranoid when they hesitate here. They’re being experienced. The fix isn’t to shame them into deleting things anyway. It’s to build enough test coverage and observability that the uncertainty actually decreases before someone swings the axe.
Old code carries political weight
Some dead code isn’t technically ambiguous. It’s just politically sensitive. That SDK integration that was built as a custom favor for a major customer. That reporting module that the VP of Sales wrote themselves back in 2019. That authentication pathway that the CISO once approved personally and hasn’t been revisited since.
Engineers learn quickly that touching certain code is a way to step on invisible landmines. The technical case for deletion can be airtight and still lose to the political case for leaving it alone. This isn’t unique to engineering, but it plays out with particular frustration in codebases because the engineers can see the cost clearly, they can measure the extra build time and the increased cognitive load, and they still can’t get the PR approved.
If your team has code that people know is dead but won’t touch, the question worth asking is whether there’s a political reason, not a technical one.
The psychological cost of deleting something that worked
Engineers are trained to worry about breaking things. Deleting code that currently does nothing feels safe, right up until you discover that it was doing something you didn’t realize. That experience, once it happens to you, tends to stick.
There’s also a subtler effect: code that represents a lot of past effort feels wrong to throw away, even when keeping it is clearly the right move to make. This is the sunk cost fallacy playing out in your file system. Nobody wants to be the person who deleted the module that took three engineers six months to build, even if that module is no longer called anywhere.
Good engineering culture pushes back on this. Your commit message should document why something was removed, not just what was removed, so future engineers can understand the reasoning instead of second-guessing themselves.
The counterargument
The reasonable objection here is that plenty of teams do delete dead code regularly and it’s not that complicated. Just enforce it in code review. Just run a dead code analysis tool in CI. Just make it a team norm.
This is true for teams that have solved the underlying conditions: clear ownership, strong test coverage, a culture where deletion is treated as a first-class contribution rather than a risky indulgence. Those teams exist. They’re not the majority, and they didn’t get there by accident. They got there by explicitly investing in the preconditions, which is exactly the work that most teams skip because it doesn’t ship features.
Deletion is a discipline, not a task
The reason deleting dead code is so hard is that it’s downstream of almost every other problem a team might have: unclear ownership, insufficient tests, weak observability, political friction, and a reward structure that values adding things over removing them. You can’t fix it by scheduling a “code cleanup sprint” once a quarter.
If you want a codebase that actually shrinks when it should, start by making deletion visible and valued. Track it. Celebrate it. Write the postmortem when a deletion goes wrong and use it to build better tooling rather than using it as a reason to stop deleting. The teams that manage this well have made it a habit, not a heroic act.