The term “heisenbug” borrows from Heisenberg’s uncertainty principle: the act of observing the system changes its behavior. Attach a debugger, add a log line, slow down execution by a single millisecond, and the bug disappears. It’s tempting to treat these as acts of God, the gremlins of software. I want to argue the opposite. Heisenbugs are not mysterious. They are the predictable consequence of writing code that depends on conditions you’ve decided not to make explicit.
That’s a strong claim, so let me defend it.
The Bug Is Always There. You Just Can’t See It Yet.
A heisenbug is almost always a race condition, a timing dependency, or a reliance on uninitialized state. Consider the classic example: two threads incrementing a shared counter without a lock. On your development machine, with its particular CPU scheduler and load profile, thread A always finishes before thread B touches the value. The bug is latent. Add a debugger breakpoint and you’ve introduced a pause long enough for the scheduler to context-switch, and suddenly the interleaving you never designed for becomes the interleaving you always get.
The bug didn’t appear because you looked. The bug was always there. You just created conditions where it could express itself.
This matters because the mental model most teams apply, “the bug is intermittent and therefore probabilistic,” leads them toward probabilistic solutions: run it again, wait for it to reproduce, add retry logic. These are coping strategies. The actual fix requires making the hidden dependency explicit, usually by eliminating shared mutable state, adding proper synchronization, or designing the code so the timing simply doesn’t matter.
Observation Changes Timing, Not Logic
The reason heisenbugs are so disorienting is that our primary debugging tool, the process of slowing down and inspecting, is precisely what makes them go away. A console.log in JavaScript, for all its simplicity, is synchronous I/O. It takes time. In a tight event loop or a concurrent system, that time is enough to change the ordering of operations.
This is why printf-debugging (inserting print statements to trace execution) is unreliable for this class of bug. You’re not observing the system; you’re modifying it. The appropriate tools are ones that either don’t alter timing (hardware watchpoints on certain platforms, post-mortem core dumps, certain kinds of tracing) or that reproduce the bug deterministically by controlling the scheduler explicitly.
Tools like ThreadSanitizer in the LLVM ecosystem, or Go’s built-in race detector invoked with go test -race, are specifically designed for this. They instrument memory access at compile time and report races without materially changing the timing of your production code. If you are debugging concurrency issues without a race detector, you are doing archaeology with a sledgehammer.
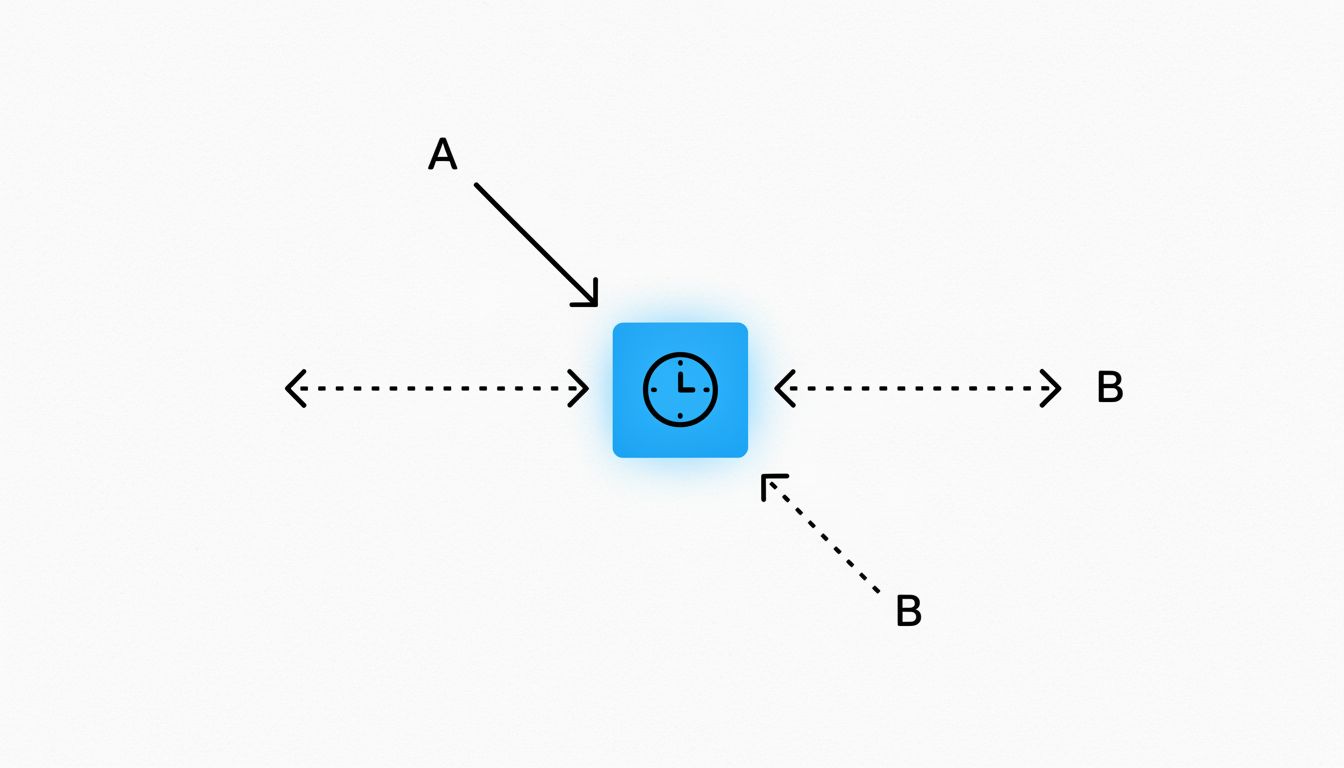
Non-Determinism Is a Design Choice You Made
Here is the uncomfortable part. Most heisenbugs exist because the developer made a choice, sometimes consciously, usually not, to allow non-determinism into a system without containing it.
Shared mutable state across threads is non-determinism. Depending on wall-clock time for ordering events is non-determinism. Relying on the order in which a hash map iterates its keys (a classic Python 2 footgun, corrected in Python 3.7 when dict ordering became guaranteed) is non-determinism. Reading uninitialized memory, which C and C++ permit, is non-determinism.
None of these are acts of God. They are design decisions with consequences that become visible under particular scheduling conditions, load levels, or hardware configurations. The reason the bug only appears in production is that production has different timing characteristics than your laptop. More load, different CPU count, different kernel scheduler settings. The bug was always there; production just has better conditions for expressing it.
This is closely related to the broader problem of distributed systems lying to you about what just happened. In distributed systems the non-determinism surface area is just larger, spanning network partitions and clock skew rather than CPU scheduling.
Making the Implicit Explicit
The fix for heisenbugs is almost never “add more logging.” The fix is to find the hidden assumption and surface it as a constraint the code enforces.
If two goroutines share a counter, protect it with a mutex or use an atomic. If your function depends on events arriving in a certain order, encode that ordering requirement in your types or your protocol instead of hoping the runtime delivers it. If you’re testing concurrent code, use a framework that lets you control interleavings (like Go’s synctest package, currently in experimental status, or jcstress for JVM concurrency).
The goal is to write code where the failure mode is a compile error or a loud panic, not a silent wrong answer that appears three Tuesdays from now in production under a specific load pattern.
The Counterargument
Some engineers will say: distributed systems, hardware interrupts, cosmic ray bit flips. Not everything is a design flaw. Some non-determinism is genuinely irreducible, baked into the physical world.
That’s true, and I’m not claiming otherwise. But the class of heisenbugs most teams actually encounter in day-to-day work, the ones eating sprint capacity and causing 3am pages, are not cosmic rays. They are race conditions in async JavaScript callbacks, unprotected shared state in Python threads, or timestamp comparisons in distributed systems without vector clocks. These are solvable with deterministic design. The genuine irreducible non-determinism cases (hardware failures, Byzantine network behavior) have their own well-understood mitigation strategies.
The “it’s just mysterious” framing is a defense mechanism, not an analysis.
The Position, Restated
Heisenbugs feel like bad luck because they hide. But hiding is a property of the environment, not the bug itself. The bug is a deterministic consequence of a design that permits certain states or orderings that you haven’t ruled out. The act of observation changes the environment just enough to rule them out temporarily.
The correct response is not better observation techniques. The correct response is to redesign the code so that the problematic state or ordering is impossible, not just unlikely. Make your assumptions explicit. Use the tools that detect races without disturbing timing. Stop treating non-determinism as a given and start treating it as a liability that needs to be contained.
The bug isn’t hiding from you. You just haven’t closed off the conditions that let it exist.