A mid-sized legal tech company, call them the kind of team that reads the research papers, spent several months building an AI-powered contract review tool. The core job was straightforward: flag risky clauses in commercial agreements. Early prototypes, running on sparse prompts and minimal context, were surprisingly good. Lawyers on the beta team were impressed.
So the engineers did what any sensible team would do. They made it better. They added the full contract history, previous versions of clauses, company-specific negotiation guidelines, jurisdiction-specific legal commentary, and a long system prompt explaining the firm’s risk appetite in detail. More information, better answers. That’s how it works, right?
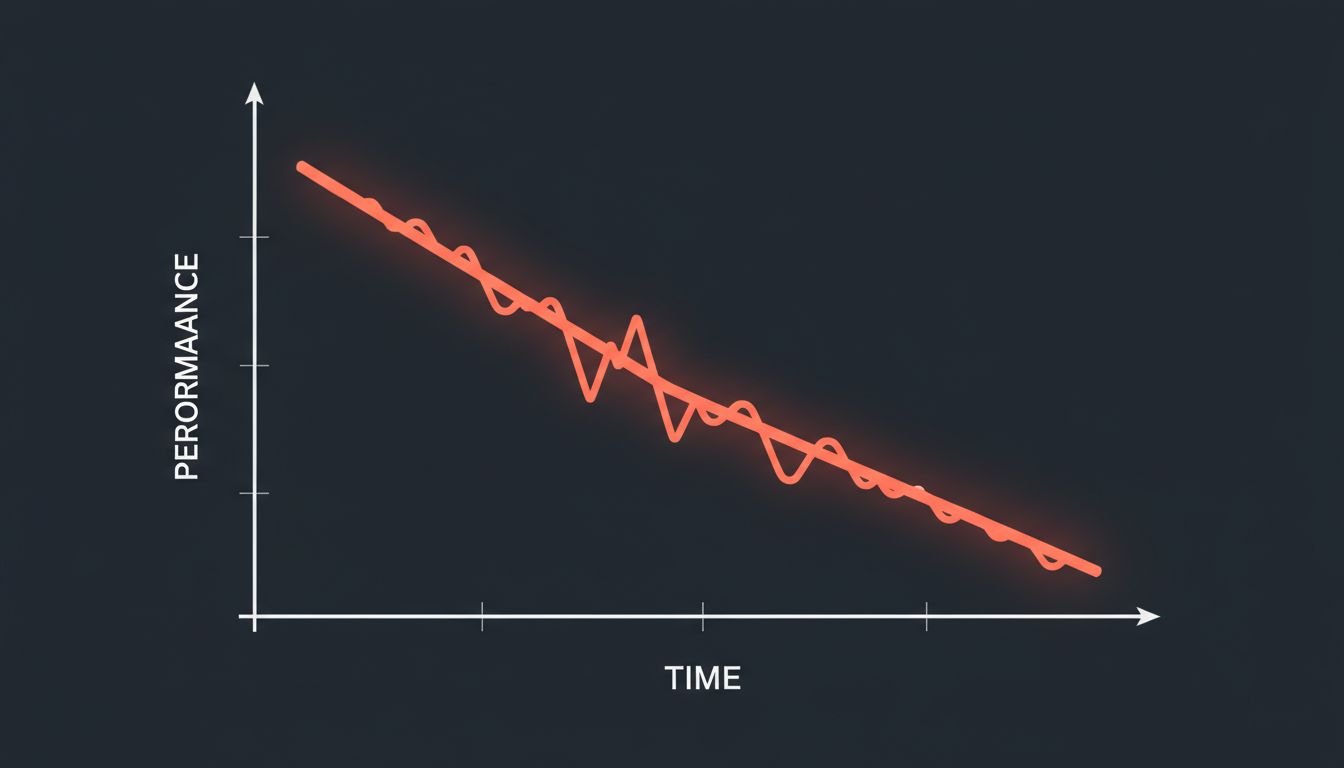
Accuracy dropped. Not catastrophically, but measurably and consistently. Clauses the early model had caught reliably started slipping through. The team spent two weeks hunting a bug that wasn’t there.
What Actually Happened
The problem wasn’t the data. It was the shape of the prompt.
Large language models don’t process a 50,000-token context window the way you read a document, starting at the top and building understanding as you go. Attention is distributed across all tokens simultaneously, but that distribution is uneven in ways that matter practically. Research from teams at Google and Stanford has documented a phenomenon sometimes called the “lost in the middle” problem: when relevant information is buried in the middle of a long context, models retrieve it far less reliably than when that same information appears near the beginning or end.
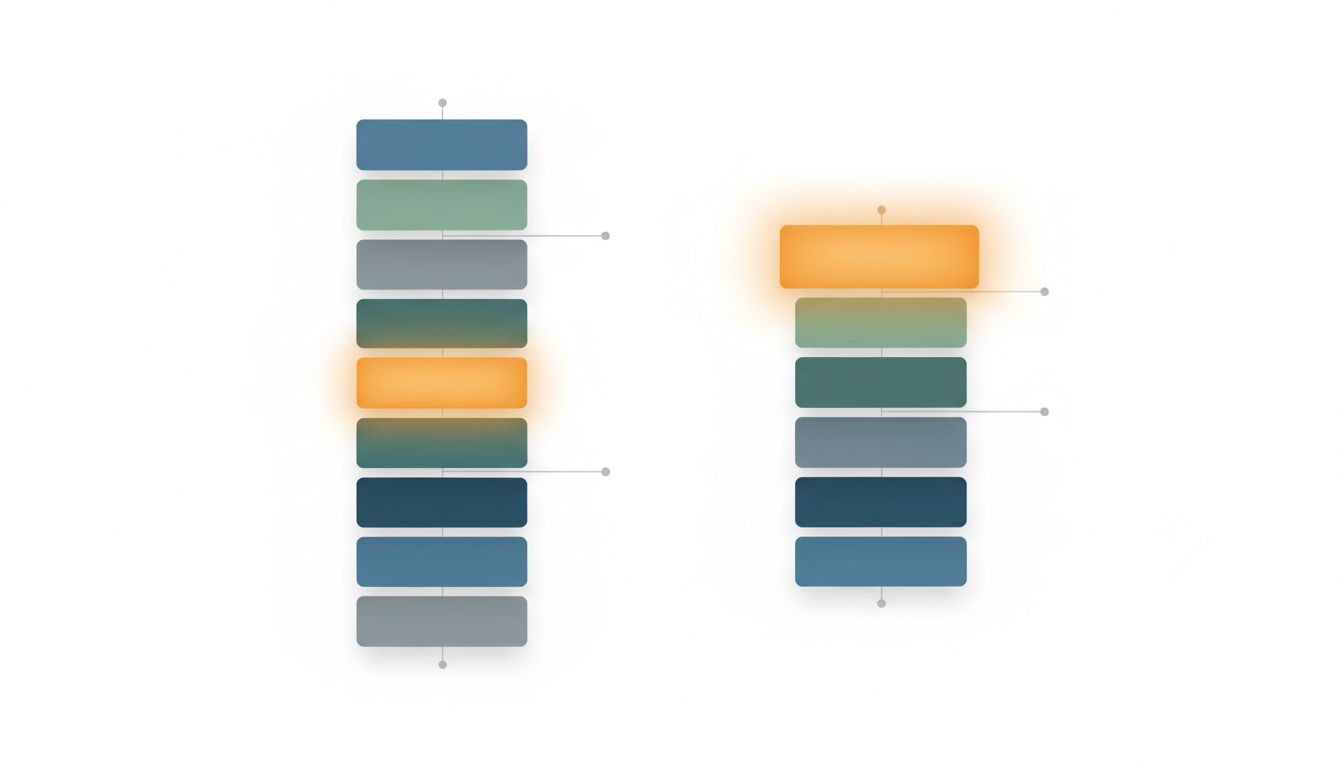
The legal team had structured their prompts logically, for a human reader. Background first, then guidelines, then the contract, then the question. That structure put the most decision-critical content, the specific clause being evaluated, somewhere in the middle of a very long document, surrounded by context that was technically relevant but practically diluting.
When they tested with shorter, focused prompts that put the clause and the specific risk criteria immediately adjacent, accuracy recovered. Some of the contextual information they’d been including wasn’t helping the model; it was giving the model more places to get lost.
Why More Information Isn’t Always Better
This runs against the intuition most people bring to AI tools. You’ve probably been told, correctly in many cases, that richer context produces better outputs. That’s true up to a point and in certain configurations. But several things can go wrong when you keep adding.
Relevance dilution. Every token in a context window competes for the model’s attention. When you add information that’s marginally related, you’re not just adding signal, you’re adding noise that the model has to sort through. If the marginal context isn’t directly useful for the specific decision, it often hurts more than it helps.
Instruction drift. Long system prompts are particularly dangerous here. When you write a 1,500-word system prompt explaining every nuance of how the model should behave, you create opportunities for internal contradictions, and models will try to satisfy conflicting instructions in unpredictable ways. Short, unambiguous instructions almost always outperform long, comprehensive ones. This connects to a broader issue with what LLMs do when they don’t know what to do: they guess, and a cluttered context gives them more material to guess from in the wrong directions.
Position sensitivity. The lost-in-the-middle problem is real and well-documented. If your most important information isn’t near the start or end of the context, you’re taking a reliability hit. This isn’t a bug that will be patched away entirely; it’s a structural feature of how transformer attention works.
Recency bias and primacy bias pulling in opposite directions. Models tend to weight recent tokens more heavily in some tasks and early tokens more heavily in others, depending on the architecture and training. You often can’t predict which direction a given model will lean without testing, which means long, mid-dense contexts introduce variance you can’t reason about in advance.
What the Legal Team Changed
The fix wasn’t to remove all context. It was to be ruthless about what earned its place in the prompt.
They introduced a retrieval step before prompting. Instead of including the full negotiation history, a retrieval system pulled only the two or three most relevant precedent clauses for the specific language being reviewed. Instead of a comprehensive risk framework, they distilled it to a checklist of the five criteria most predictive of the risks that had historically mattered.
They also restructured the prompt itself. The specific clause under review came first. The evaluation criteria came second. Supporting context came last, and only if it cleared a relevance threshold. The system prompt shrank from around 1,200 words to under 300.
Accuracy returned to baseline and then improved beyond the early prototype results, because the focused context was genuinely better context, not just less of it.
The Framework You Can Apply
If you’re building on top of LLMs and you’ve been adding context hoping to improve results, here’s a practical way to audit what you have.
Test context removal aggressively. Take each section of your context and run an A/B test without it. You’ll often find that pieces you were certain were necessary turn out to be net negative. Be willing to be surprised.
Move critical information to the edges. Whatever the model absolutely needs to get right, that information should be near the top of the prompt or near the bottom, never buried in a long middle section. Restructure ruthlessly.
Compress guidelines into criteria, not explanations. Instead of explaining why a clause is risky, describe what a risky clause looks like. Operational criteria perform better than background explanation.
Use retrieval to replace static inclusion. If you’re tempted to include a large reference document, build a retrieval layer instead. Include only what’s directly relevant to the specific query. This scales better and usually performs better.
Watch for prompt length and accuracy correlating negatively. If you add context and performance doesn’t improve, stop adding. If you add context and performance drops, start removing. Most teams only measure in one direction.
The broader lesson here is about what these models actually are. They’re not databases you fill up with knowledge. They’re pattern matchers that work best when the pattern is clear. Clarity comes from focus, not comprehensiveness.
Your instinct to give the model everything it could possibly need is a human instinct, the same one that makes you over-prepare for a meeting you’ve never had before. The model doesn’t get more confident with more material. It gets more confused. The discipline of deciding what the model doesn’t need to know is at least as valuable as deciding what it does.