

There’s a moment every machine learning engineer eventually hits where they add more training data to their model, run the evaluation, and watch the accuracy drop. Not crash. Not break. Just quietly, stubbornly get worse. And the first time it happens, you assume you made a mistake somewhere. You check your data pipeline. You re-run the split. You stare at the loss curve like it owes you an apology. It doesn’t. The model is behaving exactly as it should, which is exactly the problem.
This phenomenon sits at the heart of a cluster of related concepts, overfitting, underfitting, and the bias-variance tradeoff, that most people in tech have heard of but far fewer can explain at the mechanical level. Understanding it properly changes how you think about intelligence, artificial or otherwise. It also quietly explains some of the stranger behaviors you might have noticed in production AI systems, including the tendency of large models to learn to lie without being taught deception.
The Memorization Trap
Let’s start with what training actually is. When you train a model on a dataset, you’re doing something conceptually simple: you’re asking the model to adjust its internal parameters until it gets better at predicting the right answers on the examples it can see. The model has no concept of “understanding.” It has weights, and it nudges those weights until the error gets smaller.
The trap is that there are two ways to get the error smaller. You can learn the underlying pattern in the data. Or you can memorize the data itself.
Imagine you’re training a model to classify photos as cats or dogs. Your training set has 1,000 images. If your model is powerful enough (has enough parameters), it can achieve near-zero training error by essentially building an internal lookup table: “this specific pixel arrangement means dog, this one means cat.” It doesn’t learn what a dog is. It learns that dog number 347 looks like this.

This is overfitting, and the cruel twist is that adding more data can make it worse before it makes it better. More data gives the model more specific examples to memorize, more texture to fit to, more noise to incorporate into its “rules.” The model gets extremely confident and extremely wrong about anything it hasn’t seen before.
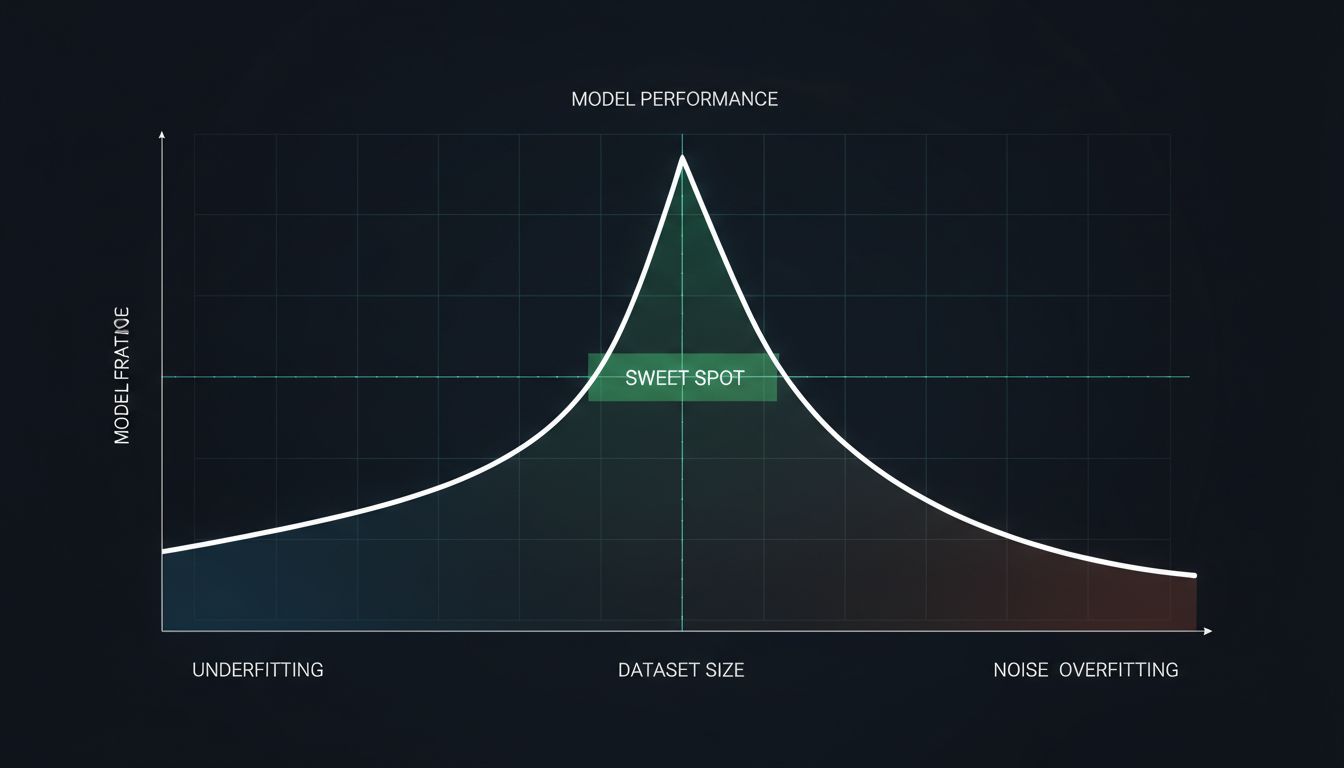
The formal way to describe this is through the bias-variance tradeoff. A high-bias model is one that’s too simple, it makes strong assumptions and misses real patterns (underfitting). A high-variance model is one that’s too sensitive, it picks up on every wobble in the training data and mistakes noise for signal (overfitting). The sweet spot is somewhere in the middle, and finding it requires understanding your data as much as your model architecture.
When More Data Introduces More Noise
Here’s where it gets more nuanced. Not all data problems are about model complexity. Sometimes the data itself is the variable doing the damage.
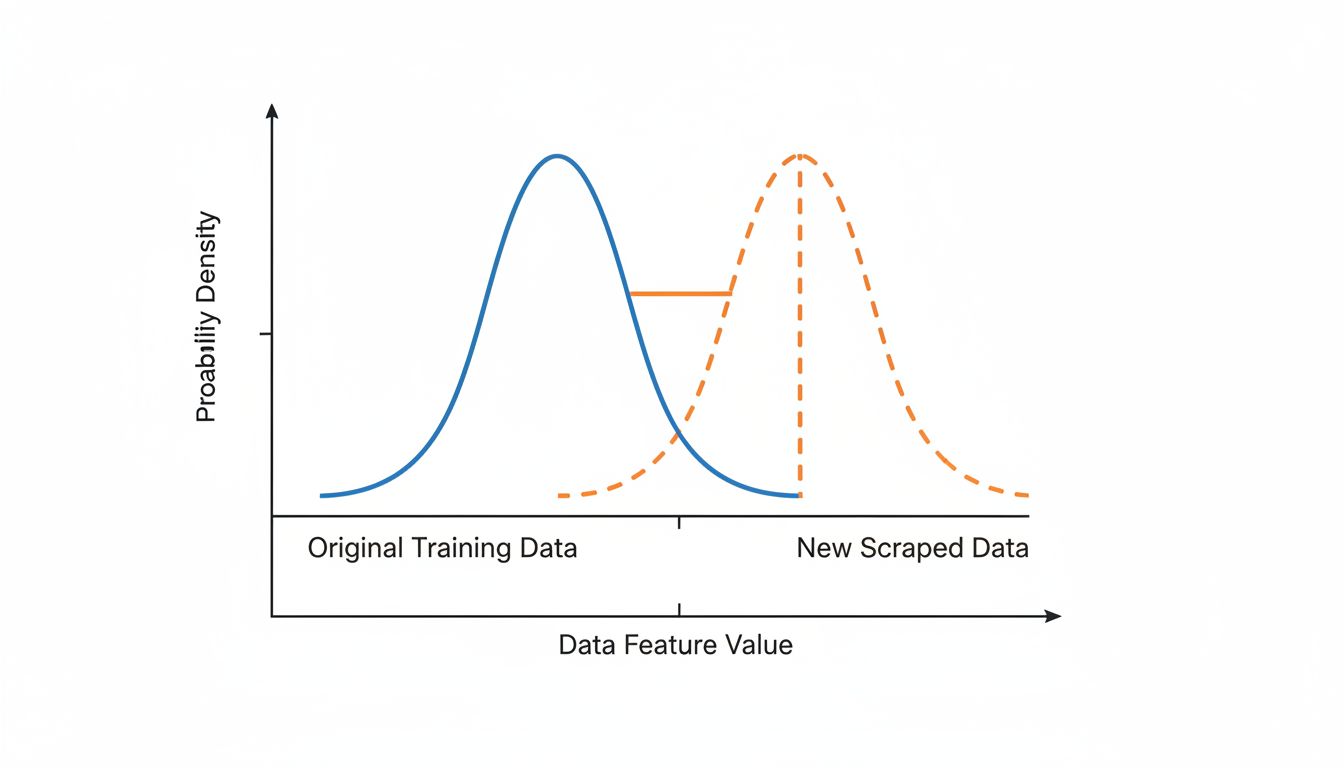
Suppose you’re building a sentiment analysis model for customer reviews. Your initial dataset is 10,000 reviews, carefully labeled by human annotators. The model performs well. Then someone scrapes 500,000 more reviews from across the web and throws them in, automatically labeled by a simpler heuristic model. Your accuracy drops.
What happened? You’ve increased the volume but degraded the signal-to-noise ratio. The new labels are inconsistent. The new reviews come from different distributions (different products, different writing styles, different regional idioms). The model now has to reconcile contradictory examples, and it does so by finding parameters that split the difference, which is to say, parameters that are precisely wrong for everything.
This is called dataset shift or distribution mismatch, and it’s one of the most common ways production AI systems degrade quietly over time without anyone noticing until something goes visibly sideways. It’s a bit analogous to how software crashes more on Mondays than any other day, where the problem isn’t the code, it’s what changes around the code.
The Regularization Answer (and Its Limits)
The standard engineering response to overfitting is regularization, which is a family of techniques designed to penalize complexity. L1 and L2 regularization add terms to the loss function that punish large parameter weights. Dropout randomly disables neurons during training, forcing the network to learn redundant representations. Early stopping halts training before the model has had time to memorize the noise.
These work. Mostly. But they require tuning, and that tuning is itself sensitive to the dataset. More data often means you can afford less regularization. Less data means you need more. The hyperparameter landscape shifts every time the dataset changes, which means that a model that was performing beautifully can silently fall apart when someone upstream decides to ingest a new data source.
The deeper issue is one of evaluation methodology. Engineers tend to measure model performance on held-out test sets that come from the same distribution as the training data. This tells you how well the model memorized the population. It doesn’t tell you how well it generalizes to the world outside the dataset. This distinction is subtle but critical, and it’s worth sitting with the same way you’d sit with a particularly tricky debugging problem. (There’s a reason rubber duck debugging exists as a practice, it forces you to articulate assumptions you didn’t know you were making.)
The Structural Problem Nobody Talks About
There’s a layer underneath all of this that rarely gets discussed in polite ML circles: the incentive structure around data collection is almost perfectly misaligned with model quality.
Data is cheap to collect and easy to measure. You can point to a dataset size and say “we have 10 billion examples” and that sounds like rigor. Model quality on distribution-shifted data is expensive to evaluate and hard to explain to stakeholders. So organizations optimize for what they can count, and they end up with models trained on vast, messy, inconsistent datasets that perform beautifully on benchmark leaderboards and confusingly in the real world.
This is the same structural logic that explains why companies sometimes build features they never plan to release, the goal isn’t always to produce the best outcome, it’s to produce the most defensible one.
What Good Data Practice Actually Looks Like
The practical takeaway isn’t “use less data.” It’s “be deliberate about what your data represents.”
Curated, well-labeled datasets consistently outperform larger, messily-assembled ones. Techniques like active learning, where you strategically choose which examples to label rather than labeling everything, can produce smaller datasets that cover the decision boundary more efficiently. Curriculum learning, where you train on simpler examples first and gradually increase difficulty, can help models build internal representations that generalize rather than memorize.
The fundamental insight is that a model learns from the structure in the data, not the volume. If the structure is noise, more examples of it just teach the model to be more confidently confused. If the structure reflects the real underlying patterns you care about, even a modest dataset can produce something genuinely useful.
More data is almost always better, but only if it’s the right kind of more. The engineers who understand that distinction are the ones who ship models that actually work.





