

Most explanations of embeddings start in the wrong place. They say something like: ‘An embedding is a way of representing text as a list of numbers so a computer can process it.’ Technically accurate. Completely misleading. That framing treats the numbers as the point. They aren’t. The point is what those numbers encode: relationships. Specifically, the idea that meaning can be expressed as position in space.
This distinction sounds philosophical until you realize it has real engineering consequences. When developers misunderstand what embeddings actually are, they make predictable mistakes in how they build systems that depend on them. Getting this right matters.
The number-list explanation buries the lead
Computers have always processed text as numbers. ASCII assigned integers to characters in the 1960s. Unicode does the same thing at larger scale. By the ‘text as numbers’ definition, embeddings are nothing new, which is obviously wrong.
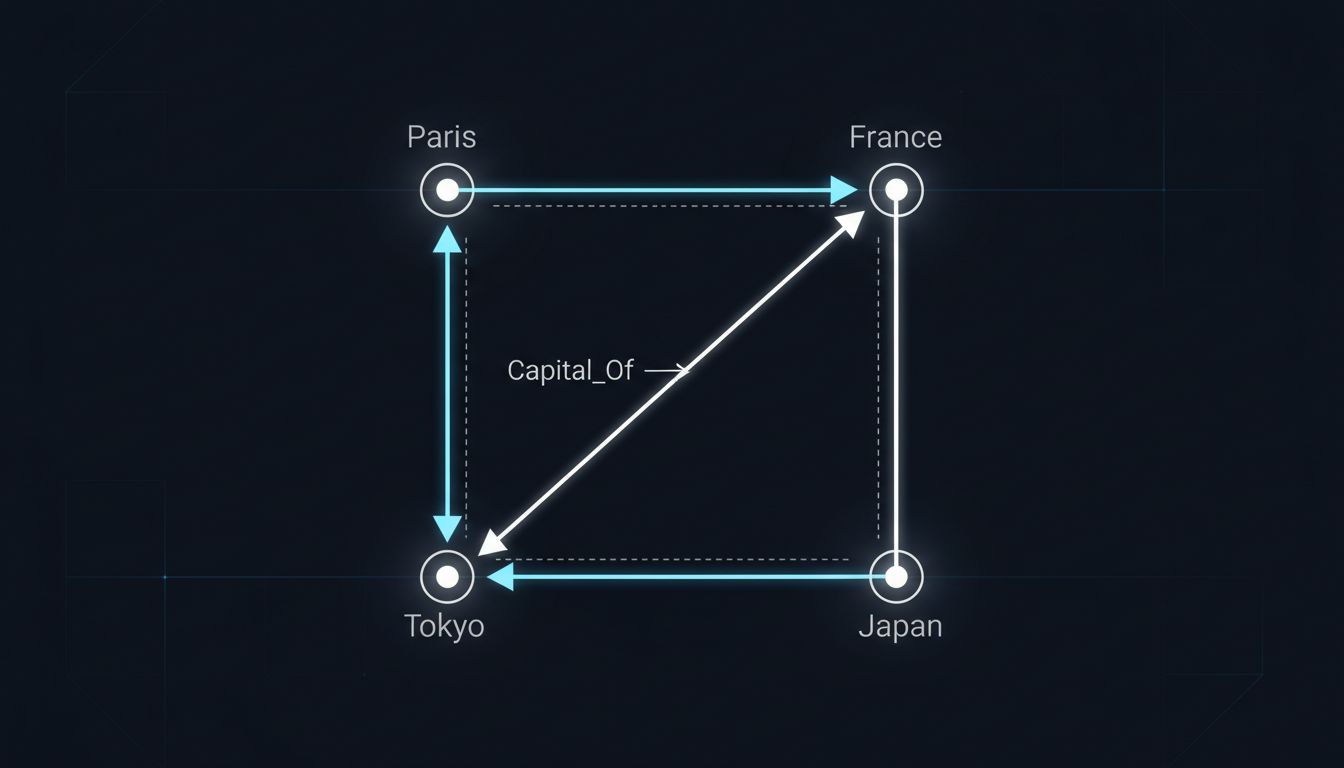
What makes embeddings different is not the encoding. It’s the geometry. In a well-trained embedding space, the vector for ‘Paris’ minus the vector for ‘France’ is approximately equal to the vector for ‘Tokyo’ minus the vector for ‘Japan.’ The famous Word2Vec result, published by Tomas Mikolov and colleagues at Google in 2013, demonstrated this cleanly. The model wasn’t programmed with geographic facts. It inferred relational structure from the statistical patterns in text. That’s not data compression. That’s representation learning, and it’s a fundamentally different idea.
When you treat embeddings as mere number-lists, you miss why the distance between two vectors is meaningful. You end up asking the wrong questions, like ‘how many dimensions should I use?’ instead of the right ones, like ‘what training data and objective function will produce the relational structure I actually need?’
Similarity search is a downstream application, not the definition
A related mistake is teaching embeddings primarily through semantic search. The tutorial goes: embed your documents, embed your query, find the nearest vectors. That workflow is real and useful. But it teaches people that embeddings exist to support similarity search, which gets causality backwards.
Embeddings exist because neural networks need continuous, differentiable inputs. The original motivation was practical: you can’t backpropagate through a categorical label. By representing inputs as dense vectors in a continuous space, you give the network something it can actually learn from. Semantic search came later, as a happy side effect of the fact that a well-structured continuous space happens to cluster similar things together.
This matters because if you think embeddings are fundamentally a search tool, you won’t think to use them for classification, for anomaly detection, for data deduplication, or for the kind of transfer learning that lets a model trained on English text reason about French. As we’ve covered with vector databases, the retrieval use case is real, but it’s one consequence of a deeper property, not the property itself.
The ‘black box’ framing is both true and useless
When embeddings get explained as opaque neural outputs that somehow capture meaning, the explanation usually ends with a shrug. ‘We don’t really know what each dimension represents.’ True. Also beside the point.
You don’t need to interpret individual dimensions to reason about the space. What you can examine is whether the geometry is doing what you want. Are semantically similar items clustering together? Are known analogical relationships preserved? Are there unexpected clusters that reveal bias in training data? These are answerable questions. Researchers have built entire subfields around probing and interpreting embedding spaces precisely because the geometry is legible even when individual dimensions aren’t.
The black-box framing encourages passivity. Developers treat embeddings as something that either works or doesn’t, rather than as something they can evaluate, audit, and improve. Given that embedding quality directly determines the quality of anything built on top of it, that passivity is expensive.
The counterargument
Some will argue that the simplified explanation is fine for practitioners who just need to ship something. If you’re calling an API that returns a vector and plugging it into a cosine similarity function, do you really need the theoretical grounding?
Yes. Not because theory is intrinsically valuable, but because the practical failure modes come directly from conceptual gaps. Teams that don’t understand what embedding spaces encode tend to use general-purpose embeddings for specialized domains without validating that the relational structure they need is actually present. They treat embedding models as interchangeable commodities and then can’t diagnose why their retrieval system keeps surfacing irrelevant results. They optimize for dimension count instead of training data quality. The misunderstanding doesn’t stay abstract. It shows up in production.
Simplified explanations are fine as entry points. The problem is when they become the complete mental model. With embeddings, the simplified version omits exactly the part that tells you how to use them well.
What the right explanation looks like
Embeddings are a learned mapping from a discrete, high-dimensional space (words, tokens, items, users) into a continuous, lower-dimensional space where geometric relationships encode semantic or functional similarity. The numbers are a vehicle. The geometry is the point.
Once you have that framing, everything else follows more naturally. You understand why attention mechanisms work by computing weighted combinations of vectors in embedding space. You understand why fine-tuning on domain-specific data changes the geometry of the space, not just the outputs. You understand why two models with the same embedding dimension can produce wildly different results depending on what they were trained to represent.
The idea behind modern AI is not that computers can process text as numbers. It’s that you can teach a model to build a map of meaning, and then navigate that map. Getting that wrong from the start makes everything downstream harder than it needs to be.





