The Setup
In 2021, a mid-sized product team at a B2B SaaS company, about 40 engineers and designers spread across three time zones, decided they had a focus problem. Slack was the obvious culprit. Messages arrived constantly. Threads forked into sub-threads. The red badge on the app icon had become so normalized that people checked it reflexively, the same way you might check a door handle even when you know it’s locked.
So they did what any reasonable team would do. They declared war on notifications.
They rolled out a set of rules that were, by most productivity-advice standards, genuinely aggressive. No direct messages during core hours (10am to 3pm in each person’s local time). All non-urgent requests had to go through a ticketing system. Slack notifications were disabled by default; people were expected to batch-check channels twice a day. Managers were told to model the behavior. The policy had executive sponsorship and a internal name, which I’ll call Project Quiet, because the actual name isn’t important.
Three months in, they surveyed the team. Self-reported focus had improved. Meetings per week dropped slightly. By every surface metric, the intervention worked.
But shipping velocity had not improved. And two senior engineers had quietly started job-searching.
What Actually Happened
When the team’s engineering lead dug into what was going wrong, she found something that the productivity literature doesn’t talk about enough. The interruptions weren’t the problem. The recovery pattern was.
Before Project Quiet, when an engineer got a Slack notification, they’d typically glance at it, decide it wasn’t urgent, and return to their code within 30 to 90 seconds. The notification was annoying, but it was bounded. It had a shape. You could ignore it or action it and move on.
After Project Quiet, those same engineers were batch-checking messages at noon and 4pm. But here’s what changed: because the batch contained everything that had accumulated over four or five hours, opening Slack had become a qualitatively different experience. It wasn’t a notification anymore. It was a pile. A pull request that needed a second review. A question about a design decision that had already been partially resolved by two other people’s responses. A thread that had gone in a direction someone disagreed with and now required a judgment call.
Engineers weren’t spending 30 seconds on a notification. They were spending 25 to 40 minutes untangling context from conversations they hadn’t been present for. The batching had reduced interruption frequency but dramatically increased the cognitive cost of each interruption event. And the recovery time, the time to get back to the actual work, was far longer than before because the re-entry cost into deep work scales with how cognitively loaded you are when you try to re-enter.
There’s a useful analogy here from how CPUs handle context switching. When a processor switches between tasks, it has to save the state of the current task and load the state of the new one. If the task being interrupted has a lot of in-flight state (open registers, cache data, pending operations), the context switch is expensive. Human working memory behaves similarly. The richer the mental model you were building before the interruption, the more state you have to reconstruct when you come back. Project Quiet had reduced the frequency of context switches but increased the cost of each one.
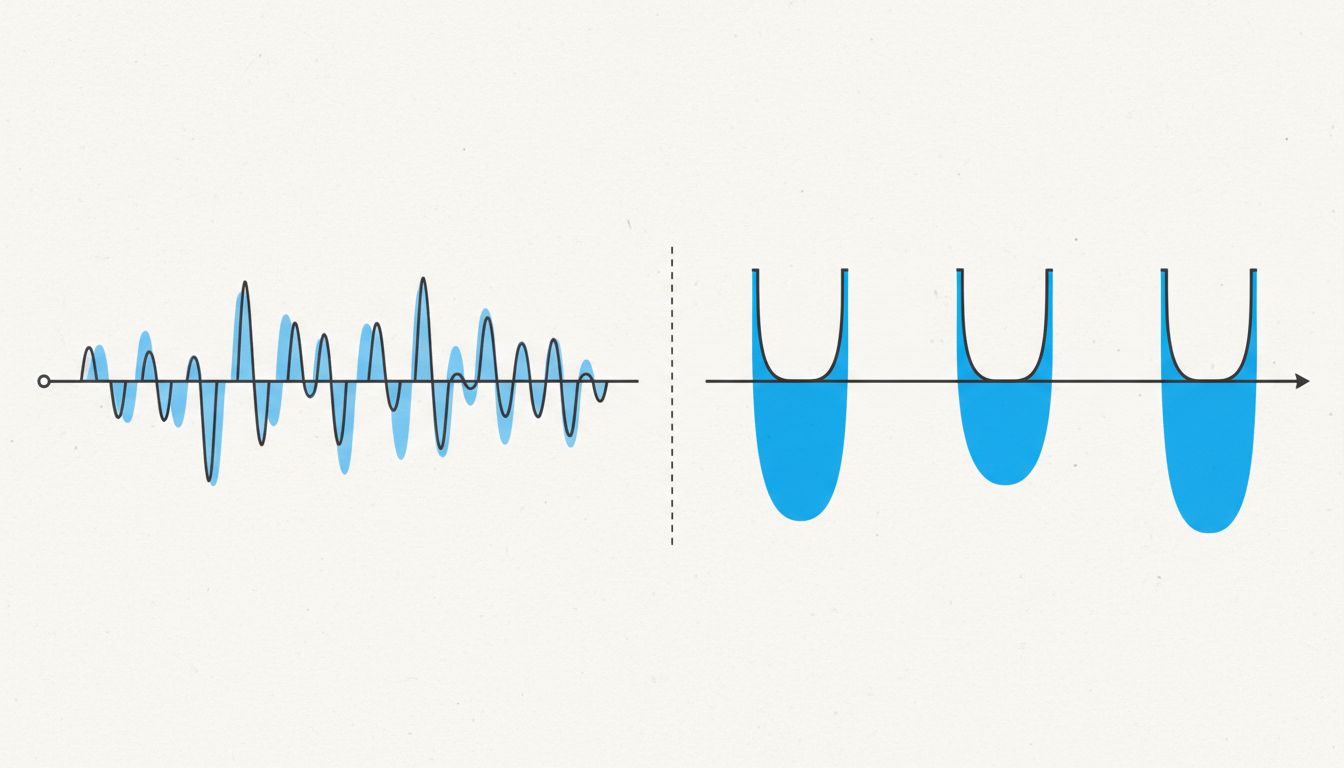
The two engineers who started looking elsewhere weren’t burned out by interruptions. They were burned out by the whiplash of trying to maintain deep concentration while knowing that at noon, they’d be handed a pile of asynchronous obligations requiring judgment, memory, and diplomacy, all at once. The predictability had gotten worse, not better.
Why This Matters
The popular framing around notifications and deep work borrows heavily from Cal Newport’s research and writing, which is good work, but it gets compressed into a simple directive: fewer interruptions equal more focus. That compression loses something important.
Focus isn’t a binary state. It’s not “distracted” or “deep working.” It’s a recovery curve. After an interruption, your ability to produce complex work climbs back gradually, and the slope of that climb depends on multiple variables: the cognitive load of the interruption itself, how much mental state you had built up before it, your confidence that you won’t be interrupted again soon, and how emotionally neutral the interruption was.
That last one matters more than most productivity frameworks acknowledge. A Slack message that says “hey, quick question” is interruptive. A Slack message that contains a thread where your architectural decision is being relitigated by three people while you were busy, and now someone has already acted on the wrong conclusion, is interruptive in a way that takes an hour to metabolize. The notification count is the same. The recovery time is not.
This is related to something that async communication frameworks often miss: the goal of async isn’t to eliminate synchronous moments, it’s to make the synchronous moments you keep more intentional and less costly. When you batch-check async communication carelessly, you’re not reducing cognitive load. You’re deferring it and compressing it, which is often worse.
What the Team Actually Fixed
The engineering lead, after talking to the people who were struggling, made three changes that were less dramatic than Project Quiet but significantly more effective.
First, they separated message types structurally, not just by convention. Anything that required a decision or judgment within the same workday went into a dedicated channel that was allowed to notify. Anything informational went into channels people could check at their own cadence. This wasn’t novel, but the key was enforcing it via tooling (Slack workflows that routed messages based on tags) rather than social contract. Social contracts erode under deadline pressure. Routing rules don’t.
Second, they introduced what the lead called “context packets.” If you were handing off a question to someone asynchronously, you were expected to include enough context that they could respond without needing to read back through the thread. This sounds like a small norm, but it directly addressed the reconstruction cost. An engineer could read a context packet in 90 seconds and give a useful answer. Reading back through a 40-message thread to understand why a question was being asked could take 20 minutes and still leave ambiguity.
Third, and most importantly, they stopped treating recovery time as personal failure. The previous culture, without anyone explicitly intending this, had developed an expectation that a good engineer bounced back from interruptions quickly. Admitting that a context switch had cost you an hour of productive work felt like admitting weakness. Once the lead named this openly and framed recovery time as a systems problem rather than a personal one, people started actually protecting it. Engineers began blocking 15-minute buffers after their noon batch-check, not to work, but specifically to finish the cognitive clearing before returning to deep work.
Six months after these changes, the job searches stopped. Shipping velocity improved in a way it hadn’t during Project Quiet. The number of daily notifications hadn’t changed much from the post-Project-Quiet baseline. What had changed was the shape and weight of each interruption event, and the explicit permission to take recovery time seriously.
What to Take From This
If your team is struggling with focus despite having already done the obvious things, notifications settings, no-meeting mornings, focus time blocks, the question to ask isn’t “how do we reduce interruptions further.” It’s “what happens in the 20 minutes after an interruption.”
Audit the recovery, not just the frequency. Count how long it actually takes your engineers to get back into complex work after a context switch, and whether that time is being treated as productive work time or invisible overhead. Invisible overhead is how individual inefficiencies compound into organizational slowdowns that nobody can quite locate or fix.
Batch-checking isn’t inherently good or bad. It depends entirely on what’s in the batch and how loaded that batch makes you when you open it. A batch of ten informational updates is fine. A batch of five items each requiring judgment in different contexts, with history you need to reconstruct, is a cognitive ambush.
And the deeper lesson: focus-recovery time is a real cost. It belongs in your engineering estimates, your team’s capacity planning, and your honest conversations about why delivery is slower than it looks like it should be. Once you see it clearly, you stop trying to eliminate it and start designing around it.