There is a specific feeling you get when you first rewrite a slow, blocking function as async. The code suddenly looks lighter. The function returns immediately. You add await in a few places, the tests pass, and you ship it. The whole thing took forty minutes. You feel productive.
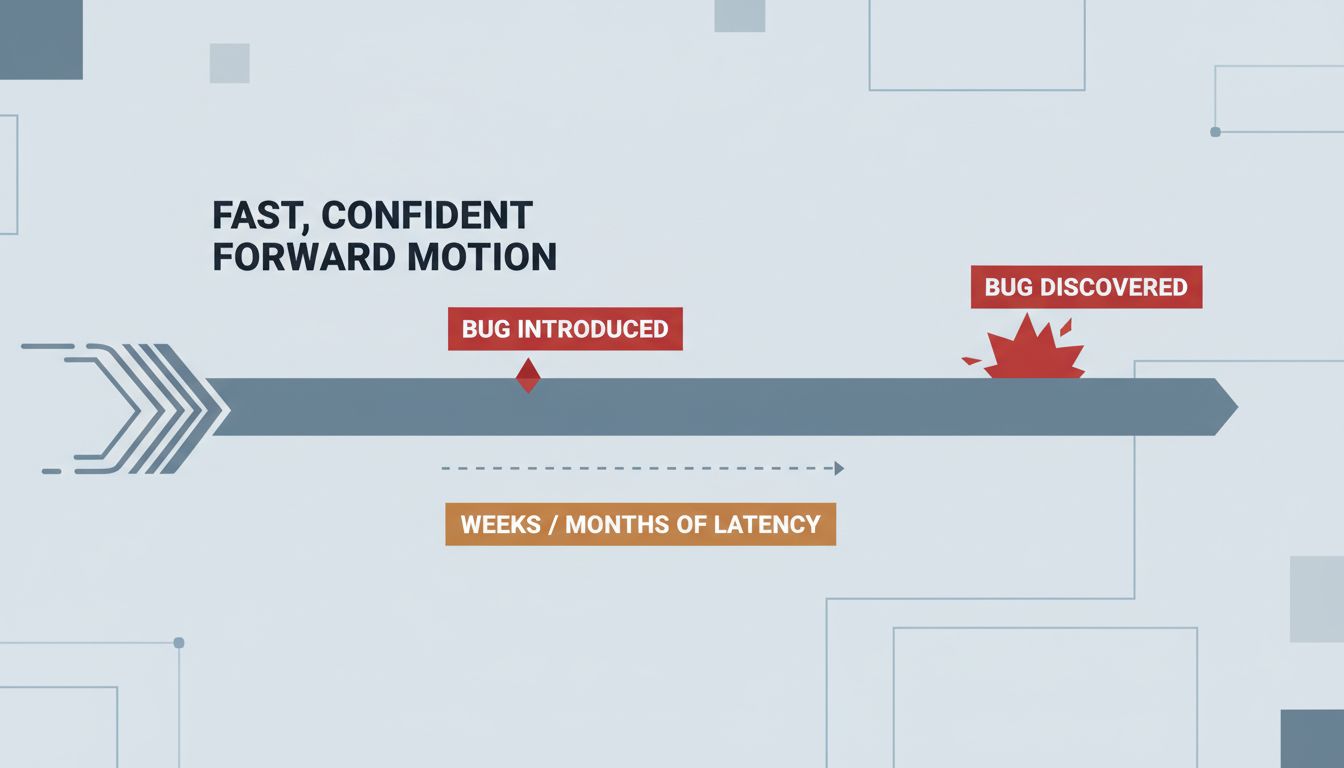
Then, three weeks later, a bug surfaces that you cannot reproduce consistently. The stack trace points somewhere irrelevant. You add logging, and the logs arrive out of order. You spend two days on it and end up reverting to a synchronous implementation just to confirm your mental model was wrong the whole time.
This is not bad luck. It is the structural consequence of a tradeoff that async programming makes explicit, but that developers often absorb unconsciously.
Writing Async Code Hides Complexity, It Doesn’t Remove It
Synchronous code has a property that is easy to take for granted: it executes in the order you wrote it. That sounds trivial until you lose it. When every line completes before the next one starts, reasoning about state is straightforward. The call stack is a faithful record of how you got here.
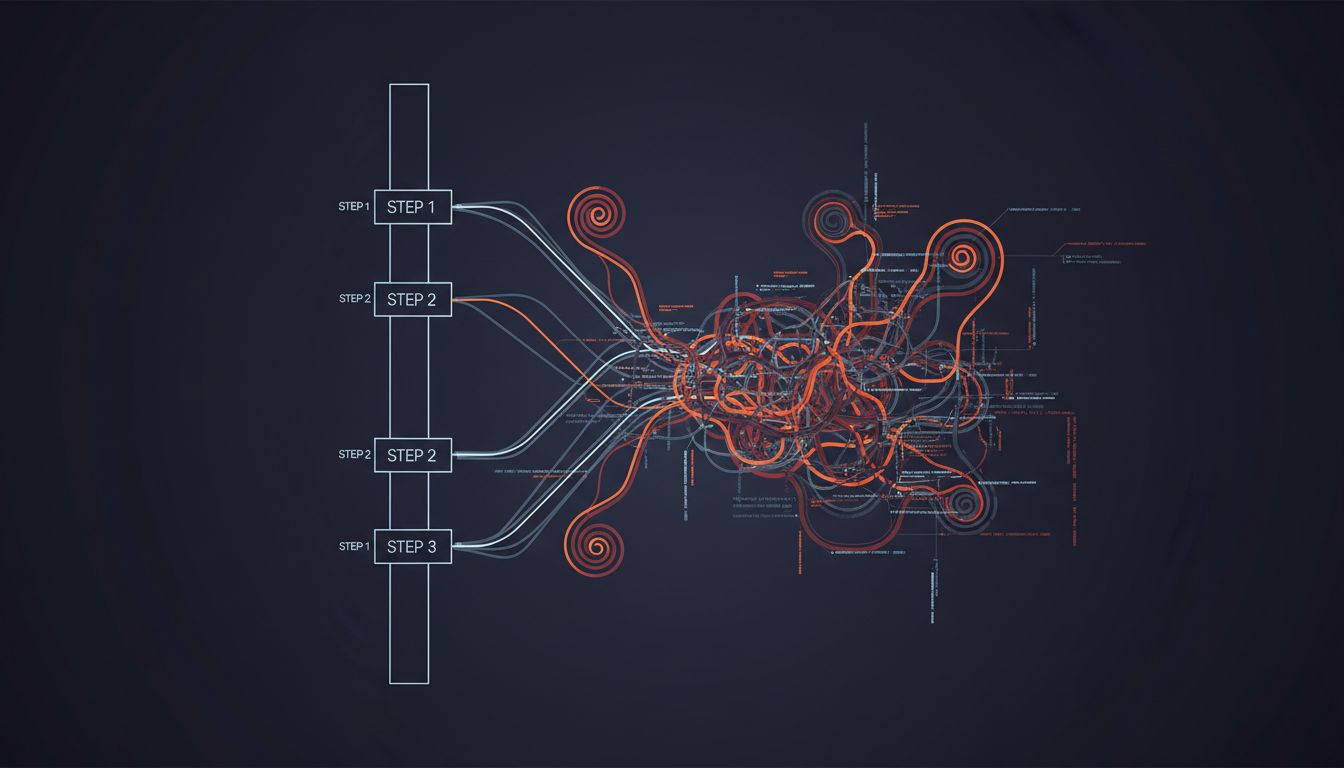
Async code breaks that contract deliberately. The entire point is to let the runtime do other things while waiting for I/O, network calls, or disk reads. But the complexity that the synchronous model made obvious, the sequential relationship between operations, does not disappear. It gets pushed into the structure of your program, into the ordering assumptions buried in your await chains, into the implicit expectations about what state will look like when a callback fires.
Python’s asyncio, JavaScript’s event loop, Go’s goroutines — they all manage concurrency differently, but they share the same fundamental property: the programmer is now responsible for reasoning about time as an explicit dimension of correctness. With synchronous code, time mostly takes care of itself.
The Debugger Lies to You
Debugging synchronous code is unpleasant but tractable. You set a breakpoint, you step through, you observe state. The environment cooperates with your mental model.
Async debugging breaks that cooperation in several specific ways. Stack traces lose meaning because the call that initiated an operation may have long since returned by the time something goes wrong. Error messages get raised in contexts that bear no obvious relationship to where the bug was introduced. Race conditions produce failures that only appear under timing conditions you cannot reliably replicate in a debugger, because attaching the debugger changes the timing.
This is not a tooling problem that better debuggers will eventually solve. It is a representation problem. The linear, step-through model of debugging is built on the assumption that execution has a single thread of causality you can follow. Async programs deliberately have multiple. You can improve your tools, but you cannot debug your way out of a conceptual mismatch between the tool’s model and the program’s actual behavior.
The practical consequence is that async bugs require a different debugging strategy entirely. You need logging that includes correlation IDs so you can reconstruct which events belong to which operation. You need to reason about happens-before relationships the same way distributed systems engineers do, because in a meaningful sense, an async program running on a single machine shares properties with a distributed system. If you’ve spent time with the failure modes of distributed systems, async bugs will feel grimly familiar.
Why It Feels Faster to Write
Async code is genuinely faster to write in the early stages of a project for a few real reasons, not imagined ones.
First, modern async frameworks have excellent ergonomics. Python’s async/await syntax, introduced in 3.5 and refined since, makes concurrent I/O look almost as clean as sequential code. You get the performance characteristics of non-blocking I/O without the callback hell that made early async JavaScript so hostile. The syntax hides the complexity, which is good for productivity and dangerous for understanding.
Second, async code is usually faster at runtime, particularly for I/O-bound workloads. A web server that can handle thousands of concurrent connections on a single thread is genuinely better than one that spawns a thread per connection. The performance wins are real, so the productivity tax feels worth paying. You write it, it benchmarks well, and you move on.
Third, async bugs are often latent. They show up under load, under specific timing, in production but not in tests. So the feedback loop that would normally slow you down during development stays quiet. The code works well enough for long enough that you associate async with speed, not with the debugging session you haven’t had yet.
The Honest Accounting
None of this is an argument against async programming. For I/O-bound services, it is often the right choice. But the honest accounting of what you are signing up for looks different than the marketing version.
You are trading debugging tractability for runtime performance. You are moving complexity from the runtime environment into your own mental model. You are taking on an obligation to understand concurrency at a level that synchronous code never demanded, because synchronous code let you avoid it.
The teams that handle this well treat async code differently from the start. They invest in structured logging with correlation. They write tests that explicitly probe timing and ordering, not just correctness in isolation. They are conservative about what gets made async and deliberate about where the async boundary sits, rather than spreading it through an entire codebase because one layer of I/O needed it.
The teams that struggle are the ones that adopted async because the syntax looked clean and the benchmarks looked good, without updating their assumptions about how long debugging would take. They write async code at synchronous speed and debug it at a rate they did not budget for.
The tradeoff was always there. The language just made it easy to miss until it wasn’t.