In 2013, NASA software safety engineer Michael Barr testified before a jury in an Oklahoma federal court about the source code running Toyota’s electronic throttle control system. His team had spent eighteen months auditing it. What they found wasn’t a single catastrophic bug. It was a codebase that had learned to look the other way.
Among the findings: task stack overflow potential, unsafe casting, and variables shared across tasks without proper protection. Many of these issues had been flagged, at some level, by the tools available at the time. The software had grown around them, not because engineers were careless, but because the warnings had become furniture.
The Setup
Toyota’s throttle control software was not written by amateurs. It was built to automotive industry standards, reviewed, tested, and shipped in millions of vehicles. The engineers involved were competent professionals working under real schedule and resource pressure, the same conditions under which most embedded systems software gets written.
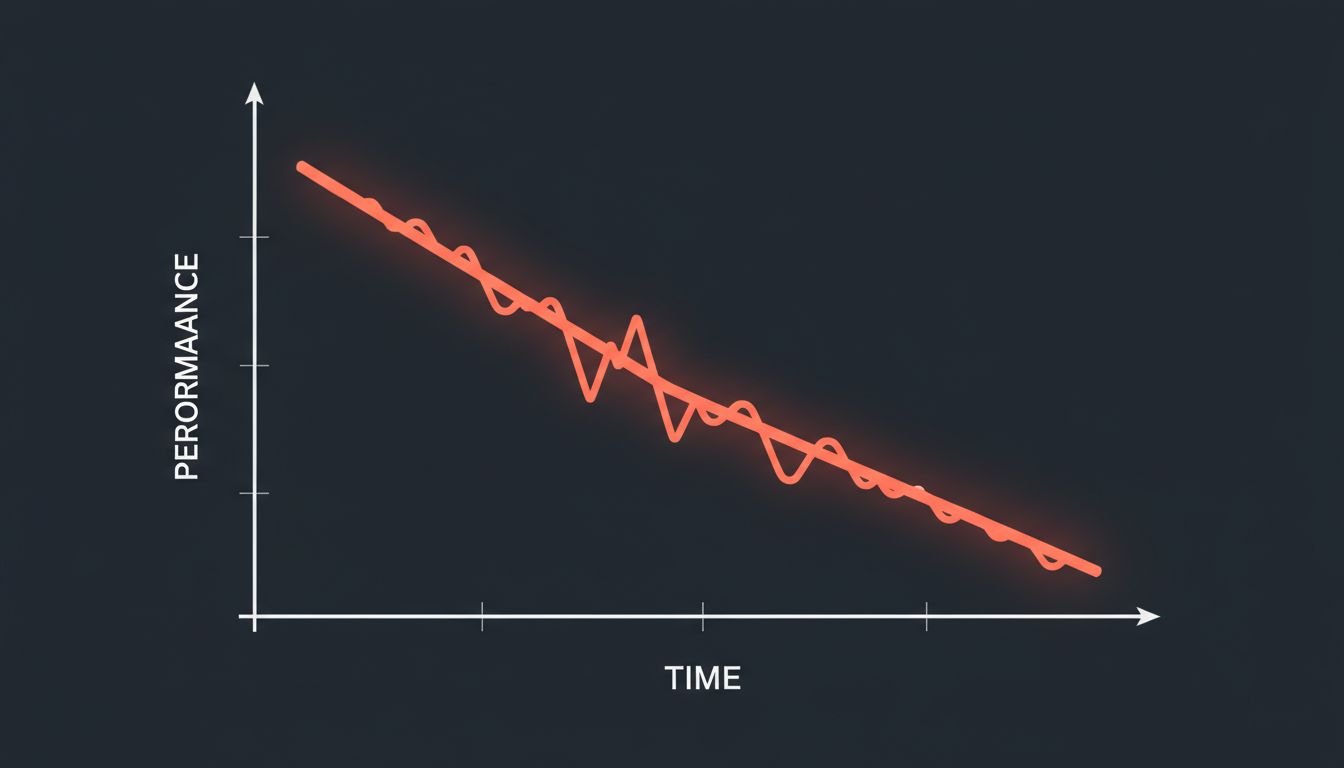
The problem wasn’t capability. It was a failure mode that shows up in every codebase that lives long enough: warning normalization. You see a warning, you can’t immediately trace it to a symptom, the deadline is real, and you move on. The next engineer sees the warning. Same calculus. After a few cycles, the warning stops registering as information. It becomes noise.
Barr’s testimony described a system with over 80,000 lines of code and a global variable count in the thousands. The static analysis tool Toyota used had flagged hundreds of violations. Many were documented and formally deferred. Deferral, in software terms, often means permanent.
What Happened
The Bookout and Schwarz crash in 2007 (the case that went to trial in 2013) involved a Toyota Camry that accelerated without driver input and couldn’t be stopped. Jean Bookout survived. Her passenger, Barbara Schwarz, did not. Toyota eventually paid settlements in multiple cases.
Barr’s analysis concluded that the software was defective and that a single-bit corruption in a specific stack variable could cause unintended acceleration. The path to that corruption ran through exactly the kind of memory management issues that generate compiler and static analysis warnings: unchecked pointer arithmetic, shared state without synchronization, stack depth that exceeded safe bounds under certain call sequences.
None of this was invisible. The tools were producing signal. The signal had been administratively reclassified as acceptable risk.
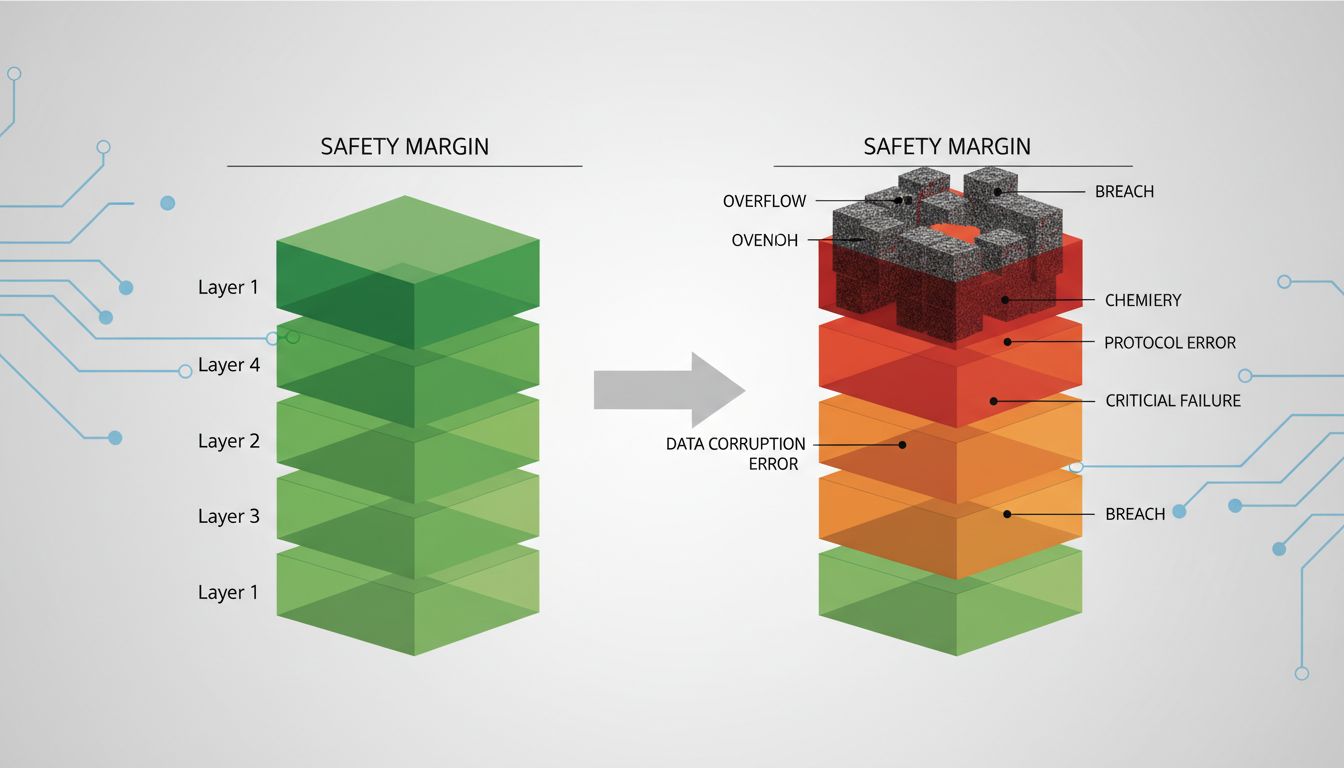
This is where the story moves from accident investigation to engineering culture. The individual warnings weren’t labeled “this will kill someone.” They were labeled things like “variable possibly used before initialization” and “unreachable code detected.” Individually, each looked manageable. Collectively, they described a system where the safety margins were thinner than anyone had formally acknowledged.
Why It Matters
Warning suppression is rational at the individual level and catastrophic at the system level. An engineer who turns off a -Wunused-variable warning to clean up build output isn’t making an obviously bad decision. An organization that has collectively suppressed 400 warnings across a safety-critical codebase has made a very bad decision, through a process that never felt like deciding anything.
This is the same dynamic that causes tiny data errors to take down entire systems: not a single dramatic failure, but a gradual erosion of the gap between normal operation and disaster.
The cognitive mechanism is well-documented. When warnings are always present, they stop being perceived as warnings. Researchers who study industrial accidents call this “normalization of deviance,” a term Diane Vaughan developed in her analysis of the Challenger disaster. The concept translates directly to software. A warning that fires on every build teaches engineers that warnings fire on every build. It communicates nothing about risk level.
The result is a codebase where the actual signal-to-noise ratio in the compiler output is unknown, because no one has tried to measure it in years.
What We Can Learn
The Toyota case is dramatic, but the underlying pattern shows up in less lethal contexts constantly. Financial systems with unhandled null dereference warnings that fire only on specific market data edge cases. Healthcare software with signed/unsigned comparison warnings in the code that calculates medication dosages. These aren’t hypotheticals.
There are a few concrete things the Toyota investigation suggests teams should do differently.
Treat warning count as a metric. If you don’t know how many compiler and static analysis warnings your codebase produces, find out today. Then set a policy: zero warnings on new code, and a tracked reduction target for existing warnings. This is not about perfectionism. It is about ensuring that when a genuinely dangerous warning appears, it is visible.
Separate deferral from dismissal. Toyota’s process allowed warnings to be formally deferred, which in practice meant they aged out of active attention. If you defer a warning, it should require re-review on a schedule. A warning that’s been deferred for two years without resolution is not a deferred warning. It’s an ignored one.
Audit your suppression pragmas. Most codebases accumulate #pragma warning(disable) directives, @SuppressWarnings annotations, or -Wno- flags over years. Pull them out into a single list and ask whether anyone alive at the company can explain why each one was added. You will find surprises.
Take the warnings your tools upgrade seriously. When a compiler version upgrade or a new static analysis rule starts producing new warnings in existing code, that’s not a maintenance burden. That’s the tool getting smarter about risks that were always there. The Toyota code didn’t become unsafe when Barr’s team analyzed it. It was already unsafe. The analysis just made the risk visible.
Barr’s conclusion was that the Toyota software had a quality problem, not just a safety problem. The distinction matters. A safety problem can sometimes be addressed with additional safeguards. A quality problem requires changing how the code is built and reviewed in the first place.
The warning your team has been ignoring might be benign. It might be a false positive introduced by a framework quirk three major versions ago. Or it might be pointing at the exact code path that will cause your worst production incident. The problem is you can’t tell the difference anymore, because you stopped looking.