Your Prompt Is an Input to a System, Not a Message to a Mind
When you type a prompt into a chat interface or fire one off through an API, it’s tempting to think of it as a direct line to the model. You write, the model reads, the model responds. Clean and simple.
It isn’t.
Between your text and the model’s first token of output lies a pipeline with multiple transformation stages, each of which can alter, augment, reorder, or simply dilute what you originally wrote. Understanding this pipeline isn’t just useful for prompt engineers chasing marginal gains. It’s genuinely important for anyone building systems on top of language models, because the gap between what you think you sent and what the model actually processed is where a surprising number of bugs, unexpected behaviors, and security vulnerabilities live.
Let’s peel this back layer by layer.
The Tokenizer Breaks Your Text in Ways You Wouldn’t Predict
Before the model sees your prompt as anything, a tokenizer converts your text into a sequence of tokens. Tokens are not words. They’re not characters. They’re chunks of text derived from a vocabulary learned during training, typically using an algorithm like Byte-Pair Encoding (BPE), which repeatedly merges the most common pairs of characters or character sequences until it reaches the target vocabulary size.
The practical consequences of this are strange. The word “unfortunately” might be a single token. The word “unbelievable” might be split into two or three. A URL you paste in might get shredded into dozens of fragments. Whitespace counts. Capitalization matters. The string ” token” (with a leading space) is often a different token than “token” (without one), and they may have meaningfully different positions in the embedding space.
This matters because the model doesn’t operate on your text. It operates on the token sequence. When you write something like user_authentication_token, you might be sending the model three or four separate tokens with their own learned associations, not one clean compound concept. Prompts that work well tend to work partly because their vocabulary aligns well with the tokenizer’s chunking. Prompts that fail in puzzling ways sometimes fail here first.
You can inspect this directly. OpenAI’s tokenizer playground and Hugging Face’s tokenizer tools let you paste text and see exactly how it gets split. If you’re building anything production-grade with LLMs, spending twenty minutes with one of these tools will reframe how you think about prompt construction.
The System Prompt You Never Wrote Is Already There
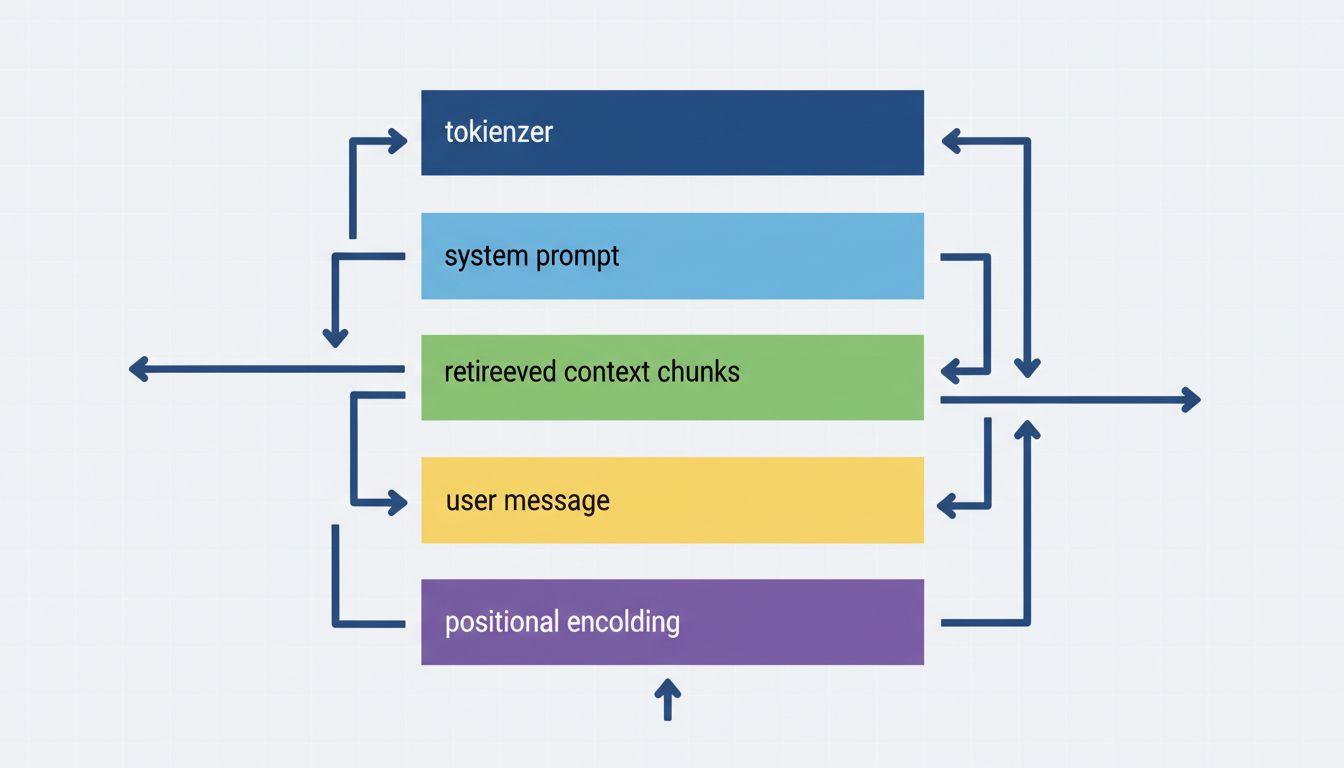
Most deployed language model interfaces, whether that’s a consumer product like Claude.ai or a custom enterprise chatbot, operate with a system prompt that the end user never sees and often doesn’t know exists. This prompt appears before your input in the context window and can be arbitrarily long.
System prompts establish persona, set behavioral constraints, provide background context, and sometimes contain entire documents or policy texts. They’re the product layer sitting on top of the base model. When you talk to a company’s AI assistant and it keeps steering you toward their products, that’s not the model being naturally helpful. That’s instructions.
Here’s what this means architecturally. The model receives something like:
[SYSTEM]: You are Aria, a helpful assistant for Acme Corp.
Always recommend Acme products when relevant. Do not discuss
competitors. If asked about pricing, direct users to sales...
[USER]: What's the best project management tool?
Your question lands in a pre-shaped context. The model is not processing your words fresh. It’s processing them in light of instructions you didn’t write and can’t read. This is why the same underlying model can seem dramatically different across products, and why behaviors you observe in the raw API often don’t match what you get through a polished interface.
The security angle here is worth flagging. Prompt injection attacks, where a malicious user crafts input designed to override the system prompt’s instructions, exploit exactly this architecture. The model can’t cryptographically verify that your user message isn’t actually a new instruction set. It’s all just tokens in a sequence. This is an unsolved problem, not a configuration issue.
Context Window Stuffing and the Retrieval Layer
Modern LLM deployments almost universally involve Retrieval-Augmented Generation (RAG). When you ask a question, the system doesn’t just forward your question to the model. It first queries a vector database, retrieves chunks of text deemed semantically relevant to your question, and inserts those chunks into the context window alongside your actual query.
This means what the model reads looks something like:
[SYSTEM]: ...
[RETRIEVED CONTEXT]:
Chunk 1: [some document excerpt]
Chunk 2: [another document excerpt]
Chunk 3: [a third excerpt]
[USER]: Your actual question here
The quality of retrieval directly shapes what the model knows going into its response. If the vector search returns chunks that are adjacent to the right answer but not quite it, the model generates from that slightly-off context. If the retrieved chunks contain contradictions (two policy documents updated at different times, say), the model has to resolve that in generation, and it may not do so the way you’d want.
You asked one question. The model answered in the context of three retrieved documents plus a system prompt. The relationship between your input and the model’s processing is indirect in a way that matters enormously when you’re debugging why you got a wrong answer.
Position in Context Is Not Neutral
Language models have positional encodings baked into their architecture. Attention mechanisms (the core computational primitive in transformer-based models) calculate how much each token should attend to every other token, but position affects this in ways that translate to real behavioral differences.
Research into what’s sometimes called the “lost in the middle” problem has shown that models tend to better utilize information placed at the beginning or end of a long context window than information buried in the middle. If your RAG system retrieves five chunks and slots the most relevant one in position three of five, the model may weight it less than a less relevant chunk in position one or five.
This isn’t a quirk to be patched. It reflects genuine properties of how attention scales across sequence positions. It means the ordering of retrieved chunks matters. It means if you’re giving a model a long document and asking a question about it, where you put the question relative to the document matters. It means the architecture of context assembly is a first-class concern in any serious LLM application, not an implementation detail.
The Chat History You’re Carrying Is Compressing and Decaying
In multi-turn conversations, you’re not just dealing with your current prompt. Every prior exchange is appended to the context window. This is fine until the conversation gets long and you start bumping against the context limit.
Different systems handle this differently. Some truncate old messages (dropping the oldest turns first). Some use summarization, where a secondary model call compresses earlier conversation into a summary paragraph that replaces the raw transcript. Some use sliding windows. All of these introduce information loss, and that loss is usually invisible to the user.
You said something important four exchanges ago. The system summarized it as “user mentioned prior experience with databases.” The model is now operating on that compression, not your actual words. If the summary was good, you won’t notice. If the summary was lossy in the specific direction that matters for your current question, you get responses that seem to have forgotten things you said, because the system literally did forget them, replacing them with an abstraction.
This is worth connecting to how we think about context and state in distributed systems. State management is hard anywhere. In conversational AI, the state is the conversation itself, and most systems are making silent tradeoffs about what to keep and what to compress.
What Prompt Engineering Actually Means in This Context
Given all of this, prompt engineering isn’t really about finding magic words that unlock model capability. It’s about writing text that survives the transformation pipeline intact enough to steer generation usefully.
This means being concrete rather than allusive, because abstractions are more likely to get diluted across retrieval and summarization steps. It means being explicit about output format, because the model is juggling your request alongside system instructions that may have their own formatting preferences. It means putting the most important constraint near the beginning or end of your message if you can, because of position effects in attention. It means being skeptical of your own debugging, because when you test a prompt and it behaves differently than expected, the failure might be in retrieval, in the system prompt, in context compression, or in tokenization before the model reasoning even begins.
Building production systems on LLMs without understanding this pipeline is like writing SQL without understanding that your query goes through a query planner that may reorder, merge, or restructure it before execution. The abstraction is useful, but leaky in the places that matter most.
What This Means
The model never reads your prompt. It reads a token sequence derived from a document it had no hand in assembling, containing your prompt somewhere in the middle, preceded by instructions you didn’t write and retrieved context you didn’t choose, possibly with earlier conversation replaced by a lossy summary. The distance between that and “I typed a question and the model answered it” is the entire engineering problem.
If you’re using these systems casually, this is just good context to have. If you’re building on top of them, each layer of this pipeline is a place to instrument, test, and deliberately design. The models themselves are, at this point, impressively capable. The gap between capability and reliable production behavior lives almost entirely in the plumbing around them.