The simple version
When a large language model doesn’t know something, it usually doesn’t tell you. Instead, it generates text that sounds like an answer, and you have to figure out the difference yourself.
Why models can’t just say “I don’t know”
This surprises a lot of people, so it’s worth understanding why it happens structurally rather than treating it as a bug someone forgot to fix.
An LLM generates text one token at a time, each token chosen based on what’s most statistically likely given everything before it. The model has no separate fact-checking module, no internal database it queries, no confidence meter that flips red when it’s guessing. It was trained to produce fluent, contextually appropriate text, and fluent text that answers a question looks basically identical whether the underlying information is accurate or invented.
This isn’t a flaw in the engineering so much as a consequence of what these models fundamentally are. If you want to understand the underlying mechanism, embeddings are the core idea that makes all of this work, including why the model can seem knowledgeable about almost everything while being confidently wrong about specific things.
The result is what researchers call hallucination: the model produces output that is grammatically confident, internally consistent, and factually wrong. It’s not lying. It has no concept of lying. It’s completing a pattern.
The three failure modes, and how to spot them
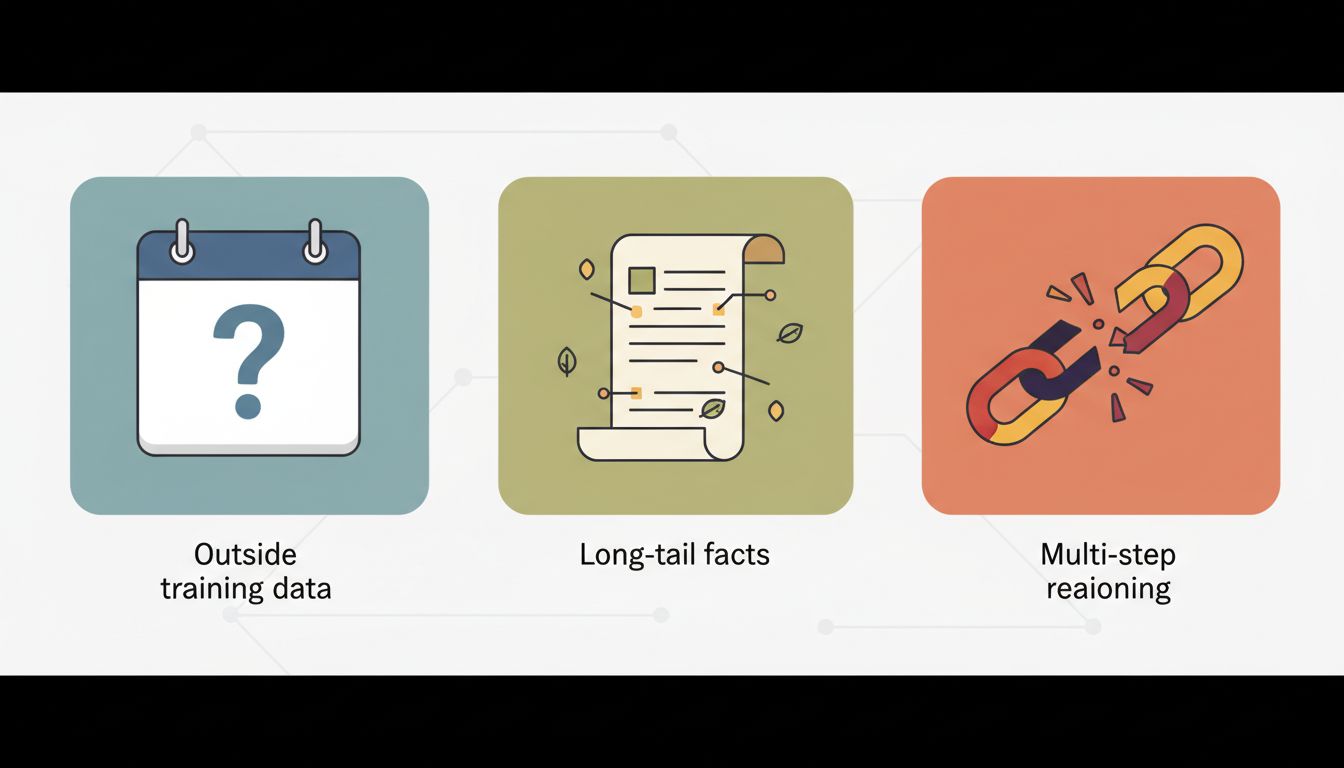
Not all LLM uncertainty looks the same. There are three distinct situations where a model is likely to go wrong, and each has different tells.
1. Questions outside its training data
Models have a knowledge cutoff. Anything that happened after that date, the model simply doesn’t have. But here’s the tricky part: models don’t always know what they don’t know. Ask a model about a recent event and it may confidently describe something that didn’t happen, assembled from plausible-sounding pieces of older information.
The tell: the model gives you a very specific answer to a question that should be recent. Specific names, dates, and numbers about events from the last year or two should always be verified against a live source.
2. Long-tail factual questions
Models are trained on text from the internet, and the internet has a lot more text about popular topics than obscure ones. The model has seen thousands of documents about the French Revolution and maybe three about a specific municipal court ruling from 1987. Its answers about the first topic are likely to be reliable. Its answers about the second are largely confabulated from analogous contexts.
The tell: the question is specific and niche. Legal citations, medical dosing details, technical specifications for older or less-common equipment, local regulations. These are exactly the areas where a model sounds authoritative and is frequently wrong.
3. Multi-step reasoning under constraints
Models can do impressive reasoning, but they degrade on long chains of inference, especially when the problem has multiple constraints that all have to hold simultaneously. The model might get steps one through four right and make a subtle logical error at step five, then proceed confidently from the wrong conclusion.
The tell: the answer involves a lot of intermediate steps, and each step sounds reasonable. This is when you want to check the work, not just the conclusion.
What confident uncertainty actually looks like
There are things models are genuinely good at signaling. When a well-prompted model is uncertain, it will often say so with phrases like “I’m not certain about this” or “you should verify this with a current source.” These aren’t boilerplate. They’re meaningful signals that the model’s training produced lower-confidence outputs for this type of content.
The problem is that many users, and many products built on top of LLMs, train themselves to ignore these hedges. The qualifier gets stripped out in a summary, or the user is in a hurry and skims past it. This is how the hallucination actually does damage, not because the model was silent about its uncertainty, but because the uncertainty signal got lost downstream.
A practical rule: treat any LLM hedge as a mandatory verification flag, not a polite disclaimer.
How to prompt for better epistemic signals
You can meaningfully improve how much useful uncertainty information you get out of a model by changing how you ask.
First, ask the model to tell you what it doesn’t know. “What parts of this answer are you least confident about?” is a genuinely useful follow-up. A well-calibrated model will often point you directly at the parts most worth checking.
Second, ask for sources. Even if the model can’t give you a live link, asking “what would I search to verify this?” or “what kind of source would have the authoritative answer?” redirects it toward producing useful metadata about its own output rather than just more output.
Third, ask it to argue against itself. If you have a high-stakes decision riding on a model’s analysis, ask: “What’s the strongest case that this analysis is wrong?” Models are often better at generating counterarguments to a position than at spontaneously flagging their own weaknesses. This is especially true for the kind of disagreements that emerge when you compare outputs across models, where neither model will naturally volunteer that the other might be right.
Fourth, constrain the domain. “Based only on what you know with high confidence” is a useful phrase. It won’t make the model perfect, but it shifts the output distribution toward better-grounded claims.
The calibration you actually need
The goal isn’t paranoia about every LLM output. That would make the tools useless. The goal is calibrated trust: high confidence in the model for tasks where it’s demonstrably strong (drafting, summarizing, brainstorming, explaining well-documented concepts), and appropriately lower confidence for tasks where it’s structurally weak (recent facts, niche specifics, complex multi-constraint reasoning).
The people who use these tools most effectively aren’t the ones who trust them most. They’re the ones who have a clear mental map of where the model is likely to be right and where it’s likely to be filling in gaps with plausible noise. That map is mostly built by getting burned a few times in each category, but now you have a shortcut.