

The simple version
Every AI chatbot has a setting called “temperature” that deliberately injects randomness into its responses. Turn it up and the model gets creative and unpredictable. Turn it down and it becomes repetitive but consistent.
Why this happens at all
When a language model generates text, it doesn’t pick words the way you’d look up a fact in an encyclopedia. Instead, it calculates a probability distribution over every possible next word. Given the prompt “The sky is,” the model might assign 60% probability to “blue,” 20% to “clear,” 10% to “gray,” and so on through thousands of options.
The question is: what do you do with that distribution?
One option is to always pick the highest-probability word. This is called greedy decoding, and it produces output that is consistent but often dull and repetitive. The model locks into the most statistically average path through its training data.
The other option is to sample from the distribution, meaning you let the probabilities act like weighted dice. Most of the time you still get “blue,” but occasionally you get “gray” or “overcast” or something genuinely surprising. This is where temperature comes in.
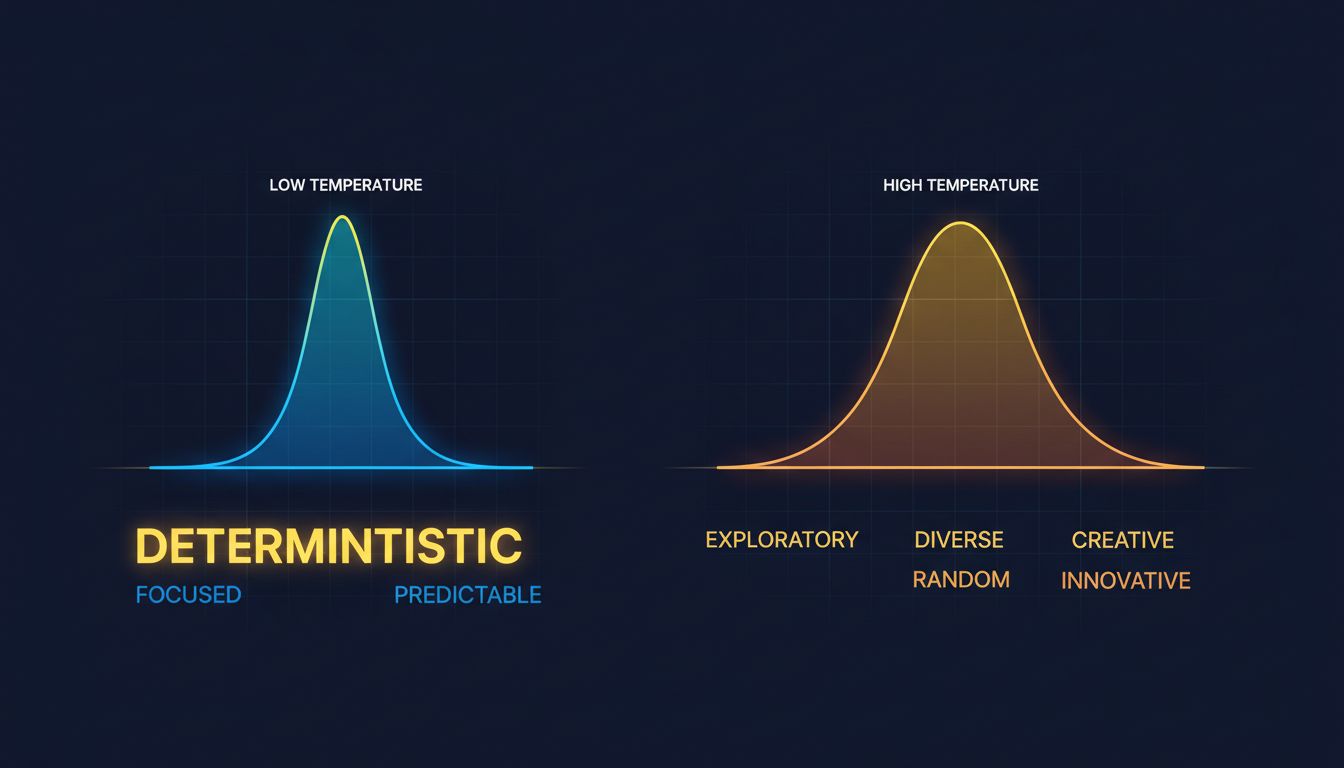
What temperature actually controls
Temperature is a number, typically ranging from 0 to 2 in most production systems. At temperature 0, the model collapses its probability distribution to a single point and always picks the most likely option. You get deterministic, reproducible output. At higher temperatures, the distribution gets flatter. Low-probability words get more of a chance. The model takes more risks.
The name comes from thermodynamics, where temperature describes how much energy particles have to move around. Low-temperature systems are ordered and predictable. High-temperature systems are chaotic. The analogy is genuinely apt.
Here’s what this means practically. If you ask a model at low temperature to write a product description, you’ll get competent, safe, slightly generic copy. Ask it at high temperature and it might produce something genuinely inventive, or it might produce something incoherent. The variance cuts both ways.
This is why the same chatbot can feel like a different tool depending on what the developers set under the hood. A customer support bot is probably running at low temperature because consistency matters more than creativity. A brainstorming assistant might run hotter because the occasional weird idea is the whole point.
The other knobs you don’t see
Temperature is the most important variable, but it’s not the only one. Two related settings show up in most serious implementations.
Top-p sampling (also called nucleus sampling) puts a ceiling on how many words are eligible to be chosen. Instead of sampling from the full distribution, the model only considers the smallest group of words whose combined probability adds up to p. Set p to 0.9 and you’re restricting the model to the words that collectively account for 90% of the probability mass. This prevents the model from making truly bizarre word choices even at higher temperatures.
Top-k sampling is simpler: just take the k most likely words and sample from those, ignoring everything else. Set k to 50 and the model is choosing from its top 50 options at each step.
Most deployed systems use some combination of these settings rather than raw temperature alone. The result is a model that can be creative without going completely off the rails.
These aren’t academic details. When you’re getting inconsistent results from an AI tool at work, understanding that there’s a randomness dial explains why your colleague got a better output from the same prompt. They might have regenerated until the dice rolled in their favor. That’s not a cheat. That’s the system working as designed.
What you can actually do with this
If you have API access to a model (OpenAI, Anthropic, Google, and most others expose temperature as a parameter), you can control this directly. Here’s a simple framework for thinking about what to set:
Use low temperature (0 to 0.3) when you need accuracy and consistency. Summarizing a document, extracting structured data, answering factual questions, writing code. You want the model’s best guess, not its most creative one.
Use medium temperature (0.5 to 0.7) for most writing tasks. Marketing copy, emails, explanations. You want some variety and natural flow without the output going weird.
Use higher temperature (0.8 to 1.2) for brainstorming, ideation, and creative work. You’re fishing for something unexpected, so you want the model to take more risks. Plan to generate several outputs and pick the best one.
If you’re using a consumer interface like ChatGPT or Claude without API access, you don’t control temperature directly. But you can approximate low-temperature behavior by asking the model to be concise and precise, and approximate high-temperature behavior by explicitly asking it to be creative, unusual, or to give you multiple different options.
The bigger lesson is that prompting and generation settings work together. A well-crafted prompt at the wrong temperature will still underperform. Understanding why AI models vary their outputs is the first step. Knowing which direction to push the dial for your specific task is what actually makes you more effective with these tools.
The randomness isn’t a bug someone forgot to fix. It’s load-bearing.





