

More data is supposed to be the answer. It’s the thing you ask for when a model isn’t performing well, the thing companies race to acquire, the thing researchers treat as a proxy for progress. But there’s a consistent, underappreciated pattern in machine learning: past a certain point, adding more data can actively hurt a model. Not just fail to help. Hurt.
This isn’t a niche edge case. It shows up in production systems, in academic benchmarks, and in the gap between a well-tuned specialist model and a bloated generalist. Understanding why it happens requires thinking carefully about what training data actually does to a model, which is more interesting than the headline suggests.
1. More Data Means More Noise, and Models Can’t Always Tell the Difference
When your training set is small and carefully curated, almost every example carries signal. When you scale up by scraping the internet or aggregating every available dataset, you inevitably pull in contradictions, mislabeled examples, low-quality text, and outright errors. The model can’t distinguish “this example is wrong” from “this is just a harder pattern to learn.” It tries to fit both.
This is the core tension in statistical learning: you want your model to generalize from examples, but generalization requires the examples to actually be representative. A model trained on a dataset where 5% of labels are wrong will learn, to some degree, to replicate those errors. Scaling the dataset doesn’t dilute this problem proportionally. If your data collection process has a consistent flaw, collecting more data just gives you more of the same flaw at larger scale.
The practical implication is that data quality compounds in ways data quantity doesn’t. A thousand clean, well-labeled medical images will often outperform ten thousand images where a significant fraction were labeled by non-specialists under time pressure. This pattern has shown up directly in medical AI, where domain-curated smaller datasets routinely beat larger general-purpose ones.
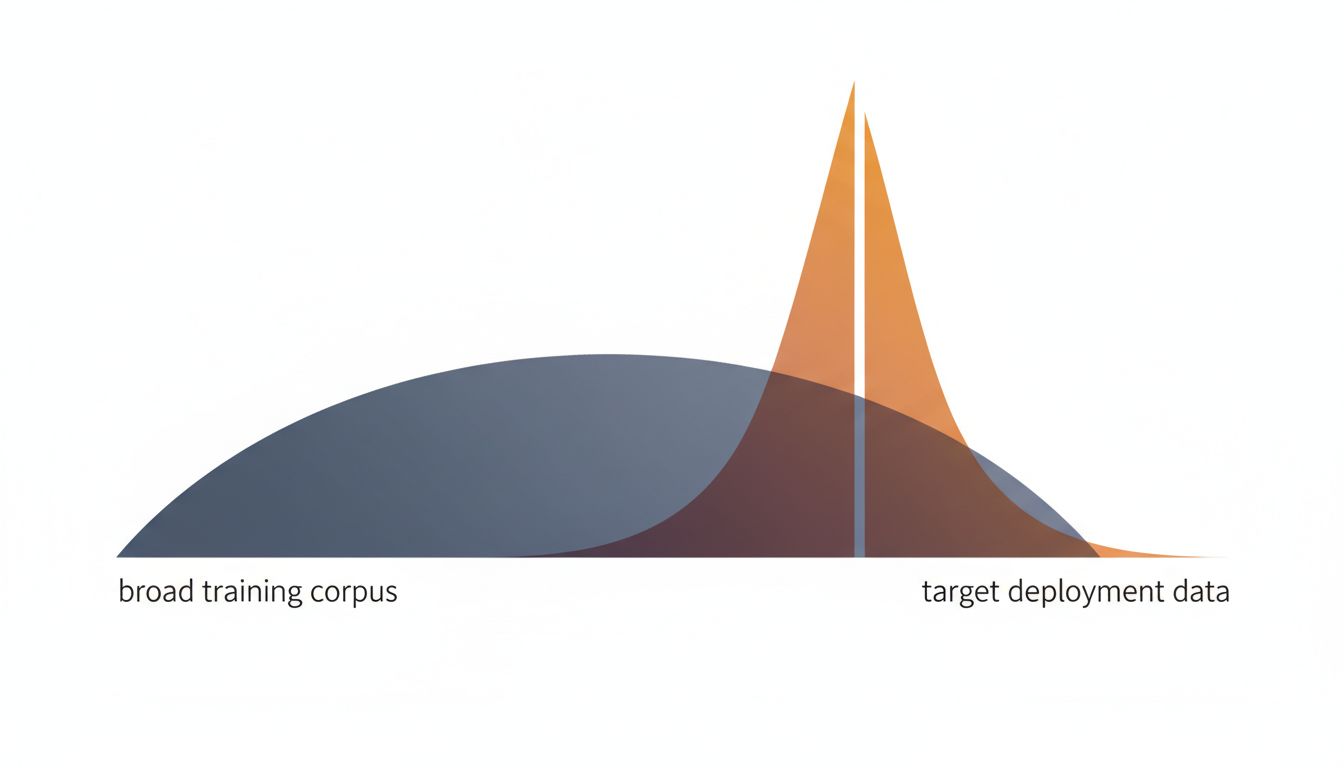
2. Distribution Shift Gets Worse as the Dataset Gets Broader
Distribution shift is when the data your model trained on doesn’t match the data it encounters in production. Every model deals with some version of this. But there’s a specific way that large, diverse training sets make this problem worse rather than better.
When you train on a huge, heterogeneous dataset, the model learns patterns that span wildly different contexts. A language model trained on everything from legal briefs to Reddit comments to technical manuals develops statistical intuitions that average across all of those contexts. When you deploy it for a specific task, say, summarizing clinical notes, the model is drawing on a distribution that includes a lot of irrelevant priors. The smaller, domain-specific model has a much tighter prior that happens to match your actual use case.
This is why fine-tuning works so well as a technique. You take a large pre-trained model, then train it further on a small, highly relevant dataset. The fine-tuning phase essentially overrides the broad, noisy distribution with a narrower, more accurate one. The large dataset gives you the general capability; the small dataset makes it useful. But the small dataset is doing more work per example than anything in the original training corpus.
3. Overfitting Doesn’t Disappear at Scale, It Just Looks Different
Overfitting (when a model learns the training data so well that it stops generalizing) is usually discussed in the context of small datasets and models that are too complex for the data they’re given. The conventional wisdom is that more data cures overfitting. This is true in a narrow sense, but it misses a subtler version of the same problem.
With very large datasets and very large models, you can get what researchers sometimes call “dataset overfitting” or memorization at scale. The model doesn’t just learn the patterns; it memorizes specific examples. Large language models have been shown to reproduce verbatim text from their training data when prompted correctly. This is overfitting in spirit even if not in the classical statistical sense. The model is encoding specifics rather than abstractions.
There’s also a related phenomenon where scaling a dataset changes which patterns become statistically dominant. If your large dataset over-represents a particular writing style, demographic, or domain, the model’s “generalizations” are actually just reflections of that over-representation. You haven’t beaten overfitting; you’ve just overfitted to a larger, messier thing.
4. Benchmark Gaming Gets Built Into the Model
This one is uncomfortable to say directly, but it’s real: when you train on the entire internet, you’re almost certainly training on the benchmarks you’ll later be evaluated against. Many standard AI benchmarks, such as MMLU, HellaSwag, and others, have their questions and answers published online. A model trained on a cleaned, intentional dataset might never see those examples. A model trained on a broad web crawl almost certainly has.
This creates a situation where the larger model appears to perform better on benchmarks but isn’t actually more capable at the underlying task. It has, in effect, seen the test. Smaller models trained on curated data that deliberately excludes benchmark contamination sometimes demonstrate stronger genuine reasoning on novel problems, even when their published benchmark scores are lower.
This is genuinely hard to fix at scale. You can’t feasibly audit what’s in a multi-trillion-token training corpus. The benchmark contamination problem is one of the reasons evaluation methodology for large models is still a mess, and it systematically advantages larger-corpus models in ways that don’t reflect real-world utility.
5. The Model Gets Confused About What Task It’s Actually Solving
Every model is implicitly learning an answer to the question “what am I supposed to do with inputs like this?” With a focused dataset, that question has a clear answer. With an enormous, mixed dataset, the model is trying to learn a single parametric function that simultaneously handles translation, summarization, code generation, factual recall, creative writing, and a thousand other tasks.
The model can do all of these things reasonably well, but it doesn’t always know which mode to be in. When you prompt it for a specific task, it’s averaging across all the contexts where similar inputs appeared in training. A smaller model trained specifically for your task has a much cleaner objective. It knows what it’s doing because the data only ever showed it one thing to do.
This is, at bottom, the same argument that focused products consistently beat bloated ones. A model trying to be everything is making constant implicit tradeoffs between competing objectives. A model built for one job optimizes that job without apology.
The upshot is that “more data” is not a strategy. It’s a resource allocation. The question is always what data, how clean, how relevant, and for what specific distribution you actually care about. Anyone telling you that scale alone solves quality problems is selling you something.





