Vector databases are everywhere right now. Pinecone, Weaviate, Qdrant, pgvector bolted onto your existing Postgres instance. Engineers are adding them to stacks the way a previous generation added Redis: because the technology feels important and the tutorials make it look easy. The problem isn’t the technology. The problem is that many teams adopt it before they can write a clear sentence describing what user problem it solves.
This isn’t a knock on vector databases. Semantic search, retrieval-augmented generation, and recommendation systems are real use cases with real value. But “we need semantic search” is not a problem definition. It’s a solution. And reaching for a solution before you’ve nailed the problem is how you end up maintaining infrastructure that costs money, adds latency, and confuses your next hire.
The Symptom: Solution-First Thinking
Here’s a pattern that plays out frequently. A team builds a chatbot or internal search tool. The keyword search feels dumb, returning literal matches instead of meaningful results. Someone reads about embeddings and semantic similarity, spins up a vector store over a weekend, and the demo looks great. Leadership approves the infrastructure. Six months later, the team is debugging why queries about “vacation policy” aren’t surfacing the right HR documents, and nobody can quite articulate what “right” means.
The tool got adopted because it produced an impressive demo, not because the team had defined what good retrieval actually looks like for their users. This is premature abstraction at the infrastructure level. You’ve built a retrieval system without a retrieval contract.
A retrieval contract sounds fancier than it is. It’s just answering: what queries will real users run, what does a correct result look like, and how will you measure whether you’re delivering it? If you can’t answer those three questions before you set up your embedding pipeline, you’re not ready for a vector database yet.
What You’re Actually Buying
A vector database stores high-dimensional numerical representations of your content and lets you find items that are close together in that space. Closeness means semantic similarity, roughly speaking. This is genuinely useful when the thing your user types doesn’t match the exact words in your content.
But “semantic similarity” is a relationship between vectors, not between user intent and business value. A document about “staff augmentation” might be semantically close to one about “hiring contractors,” which might be semantically close to one about “outsourcing.” Whether those are all correct results for a given query depends entirely on your domain, your users, and what they’re trying to accomplish. The database doesn’t know. You have to tell it, through your embedding model choice, your chunking strategy, your metadata filters, and your reranking logic.
None of that work is the vector database. The vector database is the last 10% of the problem. The other 90% is understanding what your users need and shaping your data to match it. Teams that adopt vector stores first and figure out the rest later often find themselves tuning parameters on a system they don’t fully understand, chasing a benchmark they never defined.
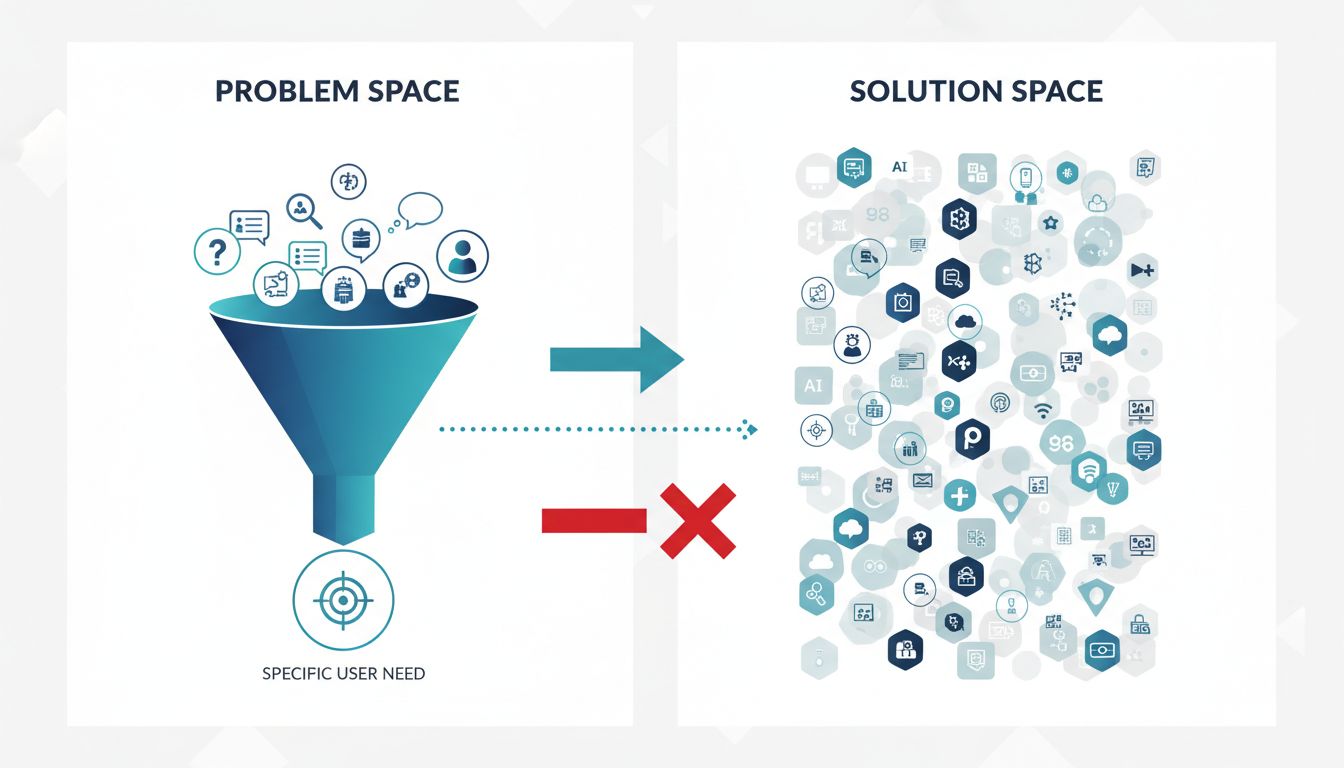
The Useful Forcing Function
So here’s a practical test you can run before committing to the infrastructure. Write down five real queries your users would submit. Not hypothetical ones, actual strings from your logs or support tickets or user interviews. Then write down, for each query, what a perfect top-three result set looks like. Be specific. If you’re building internal document search, name the actual documents.
Now go try to retrieve those results using your current approach, whatever it is. Keyword search, simple SQL LIKE queries, even just reading through your content manually. Where does it fail? What’s the failure mode? Is the failure “the exact words aren’t there but the meaning is” (a good candidate for semantic search) or is it “the content is badly organized and nobody knows where things live” (a content problem that no database will fix)?
This exercise does two things. It gives you an evaluation set before you build anything, which means you can actually measure whether your vector implementation is an improvement. And it often reveals that your problem is upstream of retrieval entirely. Many teams discover their content is the problem, not their search technology.
When Vector Search Is the Right Answer
To be clear: there are genuine cases where vector search is exactly what you need, and the sooner you reach for it the better.
If you’re building retrieval-augmented generation and your source documents use different terminology than your users, semantic search will outperform keyword matching substantially. If you’re doing recommendation at scale and you have enough interaction data to train meaningful embeddings, a vector store is the right infrastructure. If you’re running similarity search over images or audio, there’s no good alternative.
The signal that you’re in the right territory is specificity. You can name the query types, describe the failure mode of your current approach, and articulate what success looks like. You have data you can use to evaluate results. You’ve thought about how embeddings will be updated as your content changes. You’ve considered the operational overhead of a new infrastructure dependency.
If all of that is true, then yes, spin up your vector store. You’ve earned it.
Define the Problem First, Then Choose the Tool
The most useful thing you can do right now, if your team is considering or has already adopted a vector database, is to write one paragraph that describes the problem in user terms. Not “we need semantic search.” Something like: “Users searching our internal knowledge base type questions in natural language, but our keyword search only matches exact terms. When a user asks ‘what’s our policy on remote work,’ they get no results because the relevant document is titled ‘Flexible Location Guidelines.’ They then give up and ask a colleague, which costs time and creates inconsistency.”
That’s a problem. Semantic search might be the right solution. But now you can actually evaluate whether it is, because you know what you’re trying to fix and you can measure whether you’ve fixed it.
Tools are not strategies. A vector database is a powerful piece of infrastructure that can genuinely improve how your users find and interact with information. But it will not define the problem for you, and it will not tell you whether you’ve solved it. That work happens before you run pip install qdrant-client, and it’s worth doing carefully.