Shipping a trained model feels like an ending. Months of data prep, infrastructure decisions, and iteration cycles collapse into a single deployment. You push it to production, watch the accuracy metrics hold steady, and move on to the next thing.
That’s exactly when the trouble starts.
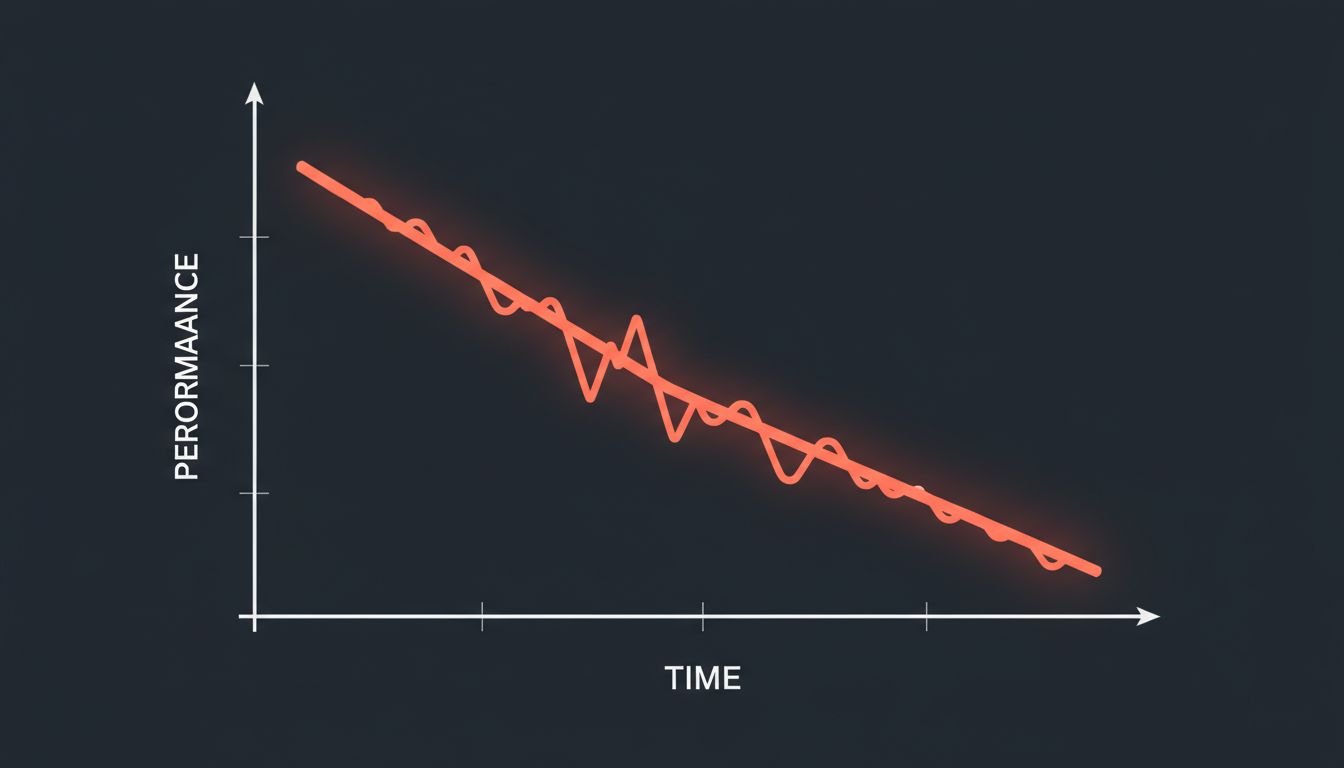
Model decay is the slow, unglamorous reality that most ML tutorials skip over entirely. It doesn’t announce itself with a crash or an error log. It seeps in quietly, and by the time your stakeholders notice, you’re already weeks behind where you should be.
What Decay Actually Means
The term most researchers use is “data drift,” but that phrase undersells how many distinct things can go wrong. You’re not dealing with one kind of decay. You’re dealing with at least three, and they have different causes and different fixes.
Concept drift happens when the relationship between your input features and your target output changes. A credit risk model trained before an economic shock behaves differently in the world after it, not because your data pipeline broke, but because the underlying reality it was modeling has shifted. The model isn’t wrong about the past. It’s just wrong about the present.
Data drift (or covariate shift) is subtler. The distribution of your input features changes, even if the underlying relationships stay the same. A content recommendation model trained on desktop browsing patterns starts seeing a majority of mobile traffic. The relationship between features and behavior might be identical, but the model was never exposed to that input distribution and performs poorly at the margins.
Label shift is the least intuitive. It occurs when the frequency of outcomes changes, independent of your features. A fraud detection system trained when fraud rates were low will be systematically miscalibrated if fraud rates spike, even if individual fraud patterns look identical.
You need to know which type you’re facing before you can fix anything. Treating concept drift like data drift is a good way to burn two months chasing the wrong solution.
The Timeline Problem Nobody Talks About
Here’s the uncomfortable truth about decay timelines: there’s no universal rule. Some models hold up for years. Others start drifting within weeks of deployment. The difference often has less to do with model architecture than with the domain it’s operating in.
Consider the difference between a model predicting next-day weather (stable physics, constant retraining cadence) versus a model predicting which marketing messages resonate with consumers (a target that shifts with culture, economy, and news cycles). The second model can become stale faster than your team can run a retraining job.
What makes this worse is that many teams don’t have a good baseline for what “normal” performance looks like over time. They set an accuracy threshold at deployment, watch it clear that threshold for a few weeks, and assume everything is fine. What they’re missing is the trend. A model that was 94% accurate at launch and is now at 91% might still be clearing your alert threshold, but if that slope continues, you’re six weeks away from a real problem.
You should be tracking trend lines, not just point-in-time snapshots.
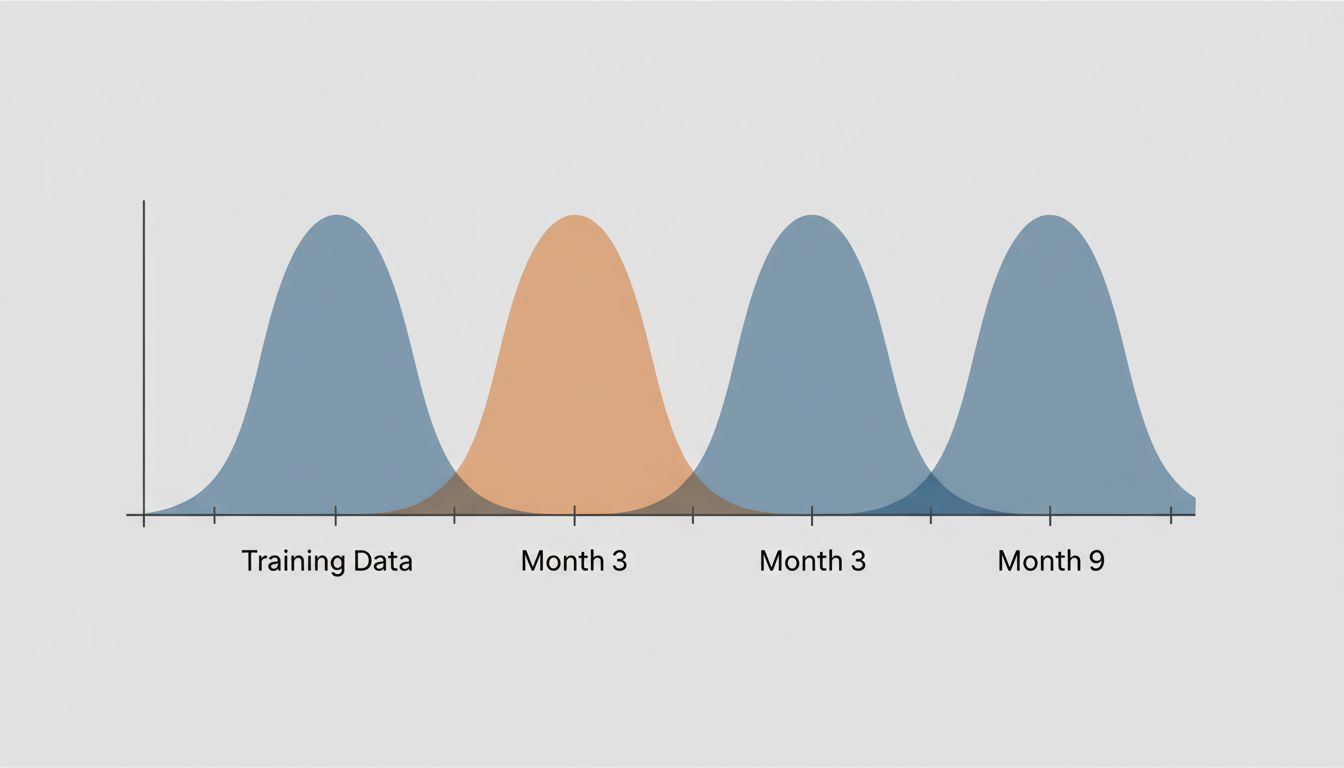
Why Your Monitoring Setup Is Probably Wrong
Most teams monitor model outputs. Fewer monitor model inputs. Almost none monitor the relationship between the two on a continuous basis.
Output monitoring catches catastrophic failures: the model starts producing nonsense, accuracy falls off a cliff, downstream systems break. It’s useful for catching acute problems. It’s nearly useless for catching slow drift.
Input monitoring (tracking the statistical properties of your feature distributions over time) gives you earlier warning. If the mean age of applicants in your loan model starts shifting, or the vocabulary distribution in your NLP pipeline starts diverging from your training corpus, you want to know before that shows up in output quality.
The more powerful approach is monitoring the relationship between predictions and eventual ground truth on a rolling basis. This requires closing the feedback loop, which is genuinely hard. Ground truth for some models arrives in minutes (click-through happened or it didn’t). For others, it might arrive in months (loan defaulted or it didn’t). The longer your feedback delay, the more sophisticated your monitoring infrastructure needs to be, because by the time reality confirms your model has drifted, you’ve already shipped many predictions based on the degraded version.
This is also why human evaluation pipelines matter more than most teams acknowledge. What a $12-an-hour Turker reveals about AI’s true cost is the kind of overhead that feels cuttable right up until your automated monitoring misses a drift problem that a human reviewer would have caught.
Retraining Is Not a Silver Bullet
The instinct when you discover decay is to retrain. Get fresh data, run the pipeline, redeploy. This works, sometimes. But retraining has failure modes that are easy to underestimate.
Frequent retraining on recent data can cause catastrophic forgetting. Your model gets good at the current distribution and loses performance on cases it used to handle well. If you’re operating in a domain where edge cases from a year ago still appear regularly, discarding that training history is genuinely dangerous.
There’s also the question of what data you’re retraining on. If your model has been running in production for six months and influencing outcomes (a recommendation system that shaped what users clicked on, a pricing model that affected what products sold), your new training data is partially a product of your old model’s decisions. This feedback loop can entrench biases that existed in the original model, silently.
Some teams use champion-challenger frameworks: keep the production model running and train a challenger on new data, then A/B test before switching. This is operationally expensive, but it catches the failure mode where your retrained model is better on recent data and worse on everything else. The overhead is worth it for high-stakes applications.
Continual learning architectures try to thread this needle automatically, updating model weights incrementally without full retraining cycles. They’re promising, but they introduce their own stability challenges. A model that’s always learning can also always be influenced by adversarial inputs in ways that periodic batch retraining isn’t.
How to Build a Decay-Aware Workflow
If you’re starting from scratch or trying to retrofit better practices onto an existing deployment, here’s a practical framework.
First, instrument before you deploy. Before your model goes live, define what “healthy” looks like across your feature distributions, your prediction distributions, and your outcome metrics. Snapshot these at deployment. You need a baseline to detect drift from.
Second, pick your monitoring granularity based on consequence, not convenience. A fraud model should be monitored daily or even hourly. A content tagging model for archival documents can probably be reviewed weekly. The cadence should match how quickly a degraded model can cause real harm.
Third, build feedback loops explicitly. For every model you deploy, answer this question before launch: how will we get ground truth, and how long will it take? If the answer is “we’re not sure” or “months,” you need a proxy metric strategy. What short-term signal correlates with the outcome you actually care about?
Fourth, document your retraining triggers. Don’t let retraining be an ad-hoc decision made when someone raises a complaint. Define in advance: if feature distribution X shifts by more than Y, or if rolling accuracy drops below Z over a 30-day window, we retrain. Make it a policy, not a judgment call made under pressure.
Fifth, version everything. Your model artifacts, your training data snapshots, your evaluation datasets. When something goes wrong six months after deployment, the most valuable thing you can have is the ability to reproduce the state of your system at any point in time. This sounds obvious and gets skipped constantly.
The Organizational Problem Underneath
Model decay isn’t just a technical problem. It’s an organizational one. ML teams tend to be structured around the training and deployment phase. There’s a lot of energy for shipping a model and much less structural support for maintaining one.
This mirrors a pattern that shows up across software engineering more broadly, where keeping a process running is harder than starting it. The unsexy maintenance work gets deprioritized in favor of new projects, right up until something breaks publicly.
The teams that handle model decay well tend to have one thing in common: they treat deployed models as live systems requiring ongoing ownership, not shipped artifacts that belong to the past. Someone’s name is on the model. Someone’s on-call for it. Someone’s accountable for its performance six months from now, not just at launch.
If that accountability structure doesn’t exist, the monitoring dashboards don’t matter. They’ll be ignored until there’s already a crisis.
What This Means
Model decay is predictable, measurable, and manageable, but only if you treat it as a first-class concern from the start. Here’s what to take away:
- Identify which type of drift you’re most exposed to (concept, data, or label) before you deploy. Each requires different monitoring signals.
- Monitor input distributions, not just output metrics. Upstream changes predict downstream problems before they become visible in accuracy numbers.
- Define your retraining triggers as policy, not gut feel. Know in advance what will cause you to act.
- Close your feedback loops explicitly. Know where your ground truth comes from and how long it takes to arrive.
- Assign ongoing ownership. A model without an owner will decay without anyone noticing until it matters.
Your model isn’t done when it ships. That’s when its clock starts.