Consistency is a lie your database tells you to make you feel better. Not a malicious lie, exactly, more the kind a friend tells when they say they’ll be there at 7 and show up at 7:15. The spirit is right. The details are negotiable. And when your entire financial platform rests on that lie, the details start to matter enormously.
The core problem is physics, not engineering. When you have data on multiple machines, and those machines communicate over a network, you cannot simultaneously guarantee that every node sees the same data at the same time while also remaining available during network partitions. This is the CAP theorem, formalized by Eric Brewer in 2000 and proved by Gilbert and Lynch in 2002. You get two of three: consistency, availability, partition tolerance. Pick carefully, because the network will partition. It always does.
Most engineers know CAP in the abstract. Far fewer understand what it means when a user clicks “confirm purchase” and the acknowledgment travels through four services before anything actually commits.
The Illusion Starts at the Read
Consider what happens when you read data from a distributed system. You ask a node for the current value of something. The node tells you. That answer was true at some point in the recent past. Whether it’s true right now, in the moment you’re acting on it, is a different question entirely.
This is called eventual consistency, and it’s the default posture of most large-scale systems. Amazon’s DynamoDB, Apache Cassandra, and most NoSQL databases offer it as their primary mode. The tradeoff is deliberate: strong consistency requires coordination between nodes, and coordination costs latency. At scale, that latency compounds. Engineers choose eventual consistency because it makes systems faster and more available, and they accept that reads might be slightly stale.
The problem is that “slightly stale” is not a fixed quantity. Under normal conditions it might be milliseconds. During a network hiccup, or a high-write period, or a partition that takes longer than usual to heal, it might be seconds. Your system doesn’t tell you which situation you’re in. It just returns a value and lets you draw your own conclusions.
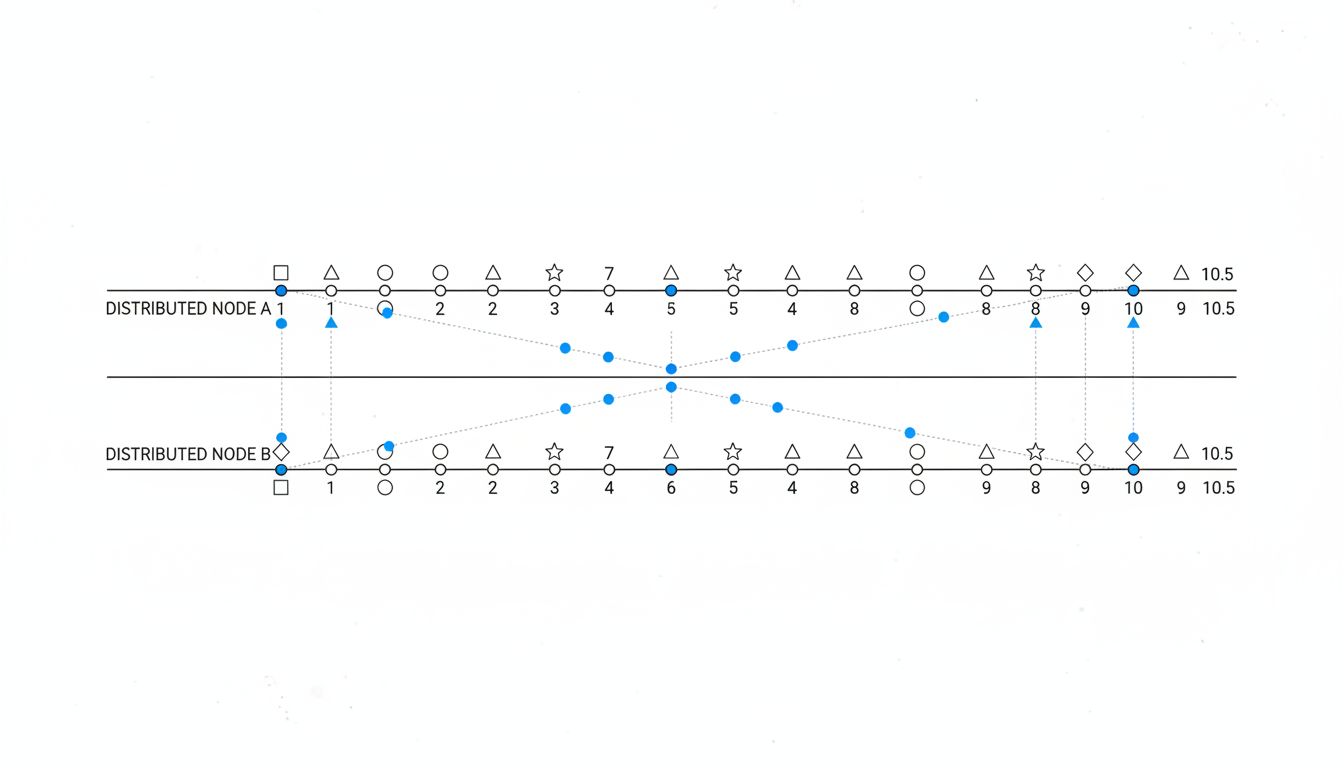
When the System Lies About Ordering
Event ordering is where distributed systems get genuinely deceptive. Two things happened. Which one happened first? The system often cannot tell you with certainty, and will sometimes tell you the wrong answer confidently.
Lamport clocks, introduced by Leslie Lamport in 1978, gave distributed systems a way to reason about ordering without synchronized clocks. The insight was elegant: instead of tracking real time, track causality. If event A caused event B, B gets a higher timestamp. This works well for causal relationships. It fails completely for concurrent events, two things that happened independently with no causal link.
Vector clocks extend this to handle concurrency, tracking a timestamp per node rather than a single counter. Amazon famously used vector clocks in early Dynamo, as described in their 2007 paper. Even then, the system could detect concurrent updates but couldn’t always resolve them automatically. It punted conflicts to the application layer, which then punted them to users, which is why you sometimes see two versions of your Amazon shopping cart.
The deeper issue is that real-world timestamps are worse, not better. Network Time Protocol synchronizes clocks across machines, but only to within some margin. Google’s TrueTime, used in Spanner, is an engineering marvel that bounds clock uncertainty to single-digit milliseconds using GPS and atomic clocks. Most companies don’t have GPS receivers in their data centers. They’re working with much wider uncertainty windows and trusting that it doesn’t matter often enough to cause problems.
Why Your Logs Don’t Tell the Full Story
Operators instinctively reach for logs when something goes wrong. Logs are the distributed system’s memory, the audit trail that answers “what just happened.” The assumption embedded in that instinct is that logs are reliable narrators. They are not.
Log entries are written locally, on individual nodes, with local timestamps. When you aggregate logs from multiple services, you’re correlating entries that were timestamped by different clocks in different locations. A request that bounced through three services might appear in your centralized logging system with events slightly out of order. The service that processed last might have logged first, because its clock was running ahead, or because the network path to your log aggregator was shorter.
Distributed tracing systems like Jaeger and Zipkin exist specifically to address this, propagating trace context through requests so you can reconstruct the actual call tree. They’re better than raw logs. They still rely on timestamps for timing information, which means the underlying clock uncertainty problem doesn’t disappear, it just gets managed more carefully.
The more insidious version of this problem is the event that almost happened. A write that was acknowledged but never replicated before the primary crashed. A transaction that committed on one node and was rolling back on another when the network partitioned. These events don’t always leave clean log entries. They leave gaps, or they leave entries that look fine until you try to reconcile them across nodes and the math doesn’t work.
Building Systems That Acknowledge the Uncertainty
The engineers who handle this best aren’t the ones who eliminate the uncertainty. They’re the ones who design around its existence.
Idempotency is the first line of defense. If you can design operations so that performing them twice produces the same result as performing them once, you’ve bought yourself enormous resilience against the failure modes above. Payment systems that process a “charge” operation versus a “charge with idempotency key” operation are building in this resilience deliberately. Stripe’s API design, which requires idempotency keys on payment intents, is a public example of this philosophy baked into product design.
Compensating transactions address what idempotency can’t. If you can’t guarantee an operation won’t happen twice, design a way to undo it. This is the logic behind sagas, a pattern for managing long-running distributed transactions by breaking them into local transactions with explicit compensating actions for rollback. It’s more complex than a single atomic transaction. It’s also more honest about what a distributed system can actually provide.
The least appreciated defense is tight observability, not just logging, but instrumentation that measures consistency lag, tracks replication delay, and alerts when nodes diverge beyond acceptable bounds. Most teams instrument the happy path. The teams that handle distributed failures gracefully instrument the uncertainty itself.
None of this makes distributed systems honest. It makes them predictably dishonest, which is as good as you’re going to get when the laws of physics are involved. A system that might lie to you occasionally, in ways you’ve anticipated and designed compensations for, is a reliable system. A system that lies to you in ways you haven’t accounted for is an incident waiting to find the worst possible moment to introduce itself.