Starting a server is a solved problem. You write some code, install a process manager, maybe wire up a container, and the thing runs. The hard part isn’t the launch. The hard part is month fourteen, when the process has been running for 400 days, memory usage has crept up 3% per week for reasons nobody can explain, and the engineer who wrote the original service left eight months ago.
The software industry has a bias toward creation over maintenance, and it shows in how we think about reliability. We celebrate deploys. We track time-to-first-byte. We optimize startup time. What we underinvest in is the discipline of keeping something alive, healthy, and correct over years of continuous operation. That gap is where most production failures actually live.
The startup path is well-lit. The runtime path is not.
When you initialize a service, you control the environment. You pick the dependencies, set the configuration, define the initial state. The code runs against your assumptions because you just made them. As time passes, those assumptions erode. The database schema changes. A library you depend on ships a subtle behavioral change in a minor version. The traffic profile shifts from short read-heavy requests to large write-heavy batches. The operating system gets patched. None of these events are bugs in the traditional sense. No single one of them is the problem. Together, they compose an environment that your original code was never tested against.
This is what engineers mean when they talk about operational drift. The gap between the system you designed and the system you’re actually running widens invisibly. By the time it manifests as an incident, tracing it back to any single cause is genuinely hard.
Memory leaks are the canonical example, but they’re not the hardest one.
A memory leak at least announces itself eventually. Your monitoring catches heap growth. You page someone. The problem has a name and a well-understood class of solutions.
The more insidious category is state accumulation that never quite becomes a crisis. Connection pool state. Cache entries that were designed for a data model that has since evolved. Background job queues that drain slightly slower than they fill, building up a multi-hour backlog over weeks. These are the conditions that don’t trip any single alert threshold but quietly degrade service quality. Users notice latency creeping up. Conversion rates slip. The on-call rotation starts fielding more “the site feels slow” tickets without any corresponding spike in error rates.
This is also where cascading failures incubate. A service running with 80% of its thread pool occupied because of accumulated slow connections has almost no headroom when traffic spikes. Your system handles one failure fine. Two is different. The chronic low-grade degradation removes the buffer that would have absorbed the acute problem.
Observability tooling was built for incidents, not for aging.
Most observability stacks are optimized for detecting sudden changes: error rate spikes, latency jumps, unusual traffic patterns. They’re genuinely good at this. What they’re not designed for is surfacing slow monotonic trends that stay within normal-looking bounds for a long time.
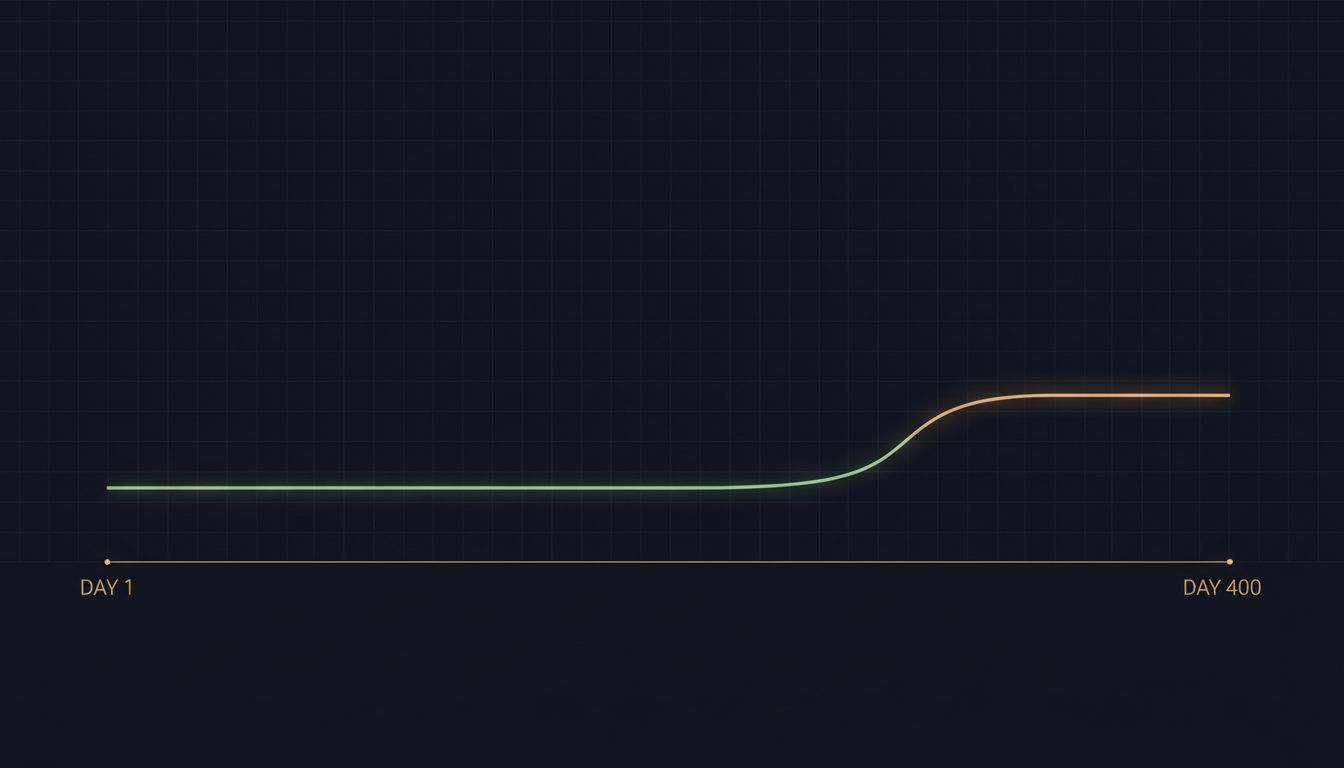
A process that takes 180ms to respond on day one and 280ms on day 400 has degraded significantly. If that drift happened linearly, at no point did your alert fire. Your dashboards showed green the whole time because the thresholds you set reflect what was normal when you set them, not what good looks like. You need baseline comparison across long time windows to catch this, and most teams either don’t build it or don’t look at it regularly.
The tooling gap here isn’t a product problem waiting to be solved. It’s a discipline problem. Someone has to own the question: “Is this service running better or worse than it was six months ago?” In most organizations, nobody does.
The counterargument
The reasonable objection here is that this is what managed services are for. Use a serverless function, a managed database, a container orchestration platform that handles restarts and health checks automatically, and the problem of long-running process health becomes someone else’s responsibility. And there’s real truth to this. AWS Lambda, for instance, sidesteps many long-running process problems simply by not having long-running processes.
But managed services don’t eliminate the category of problem, they move it. You still need to think about cold start latency accumulating under concurrency. You still need to think about how your function handles state that needs to persist between invocations. And at some point in a serious production system, you have stateful services that can’t be trivially re-architected as ephemeral functions. The discipline of thinking carefully about process aging is still necessary. You just get to apply it to a smaller surface area.
The engineers who are good at this are rare and undervalued.
Starting things is exciting. It’s the part that shows up in retrospectives, in launch announcements, in performance reviews. Keeping things running well, quietly, over years, is invisible when it goes right. The engineer who notices that connection pool size needs adjusting before it becomes an outage gets no credit. The engineer who touches nothing ships the most value is a real phenomenon, and it applies here.
The technical work of long-term process health, writing health checks with real diagnostic value, building long-window trend analysis, doing regular flamegraph reviews on services that aren’t currently on fire, deserves more institutional respect than it gets. Because the cost of not doing it isn’t a dramatic crash. It’s the slow accumulation of unreliability that eventually makes your system genuinely hard to trust.
Starting a server is a solved problem. Keeping it honest for years is the actual craft.