Everyone knows the Knuth quote. “Premature optimization is the root of all evil” has become the universal justification for not thinking ahead, not profiling, not caring about performance until something breaks. It’s a useful heuristic. It’s also dramatically overused.
The real productivity killer in most codebases isn’t a tight loop that should have been left alone. It’s the AbstractRepositoryFactoryManagerInterface that made sense in someone’s head in 2019 and now sits across seven files, three inheritance layers, and two abandoned use cases that never materialized.
Premature abstraction is worse than premature optimization, and we need to say so clearly.
Optimization mistakes are usually local. Abstraction mistakes are structural.
When a developer over-optimizes a function early, the damage is contained. The code is probably harder to read, maybe a bit brittle. But it lives in one place. You can find it, understand its intent, rewrite it.
A premature abstraction spreads. You build a plugin system before you have two concrete implementations that actually need it. You introduce an event bus because you read a blog post about loose coupling. You write a generic data-fetching layer on week one, before you’ve learned anything about your actual data access patterns. Then every subsequent piece of the system has to work around those early decisions. New engineers learn the abstractions as though they’re load-bearing, because by the time they arrive, they are. The scaffolding has become the building.
This is why deleting dead code is harder than writing new code. The hardest code to remove is code that other code has learned to depend on, even when the original reason for its existence is long gone.
Abstractions accrete carrying costs that optimizations don’t.
A premature micro-optimization adds maybe a few hours of cleanup when you eventually profile and realize it wasn’t needed. A premature abstraction adds carrying cost to every feature you ship afterward. Every new developer who touches the codebase has to understand the abstraction layer before they can do anything useful. Every bug investigation has to trace through the indirection. Every test has to mock the interfaces.
The real cost of keeping a software product alive is almost never raw compute. It’s the accumulated cognitive overhead of understanding what the system is doing and why. Abstractions that predate the problems they were meant to solve are a primary driver of that overhead.
Abstraction hides the problem instead of solving it.
There’s a particular failure mode where premature abstraction doesn’t just add complexity, it actively conceals the right solution. When you abstract too early, you commit to a model of the problem before you understand the problem. Then when the real shape of the problem emerges, you find yourself extending and bending the abstraction to fit, rather than rethinking from first principles.
This is how you end up with ORMs that fight you when you need a join, plugin architectures that make simple customizations impossible, and service boundaries that cut right through your most common data access patterns. The abstraction was built for a problem that never quite arrived, and now it’s in the way of solving the one that did.
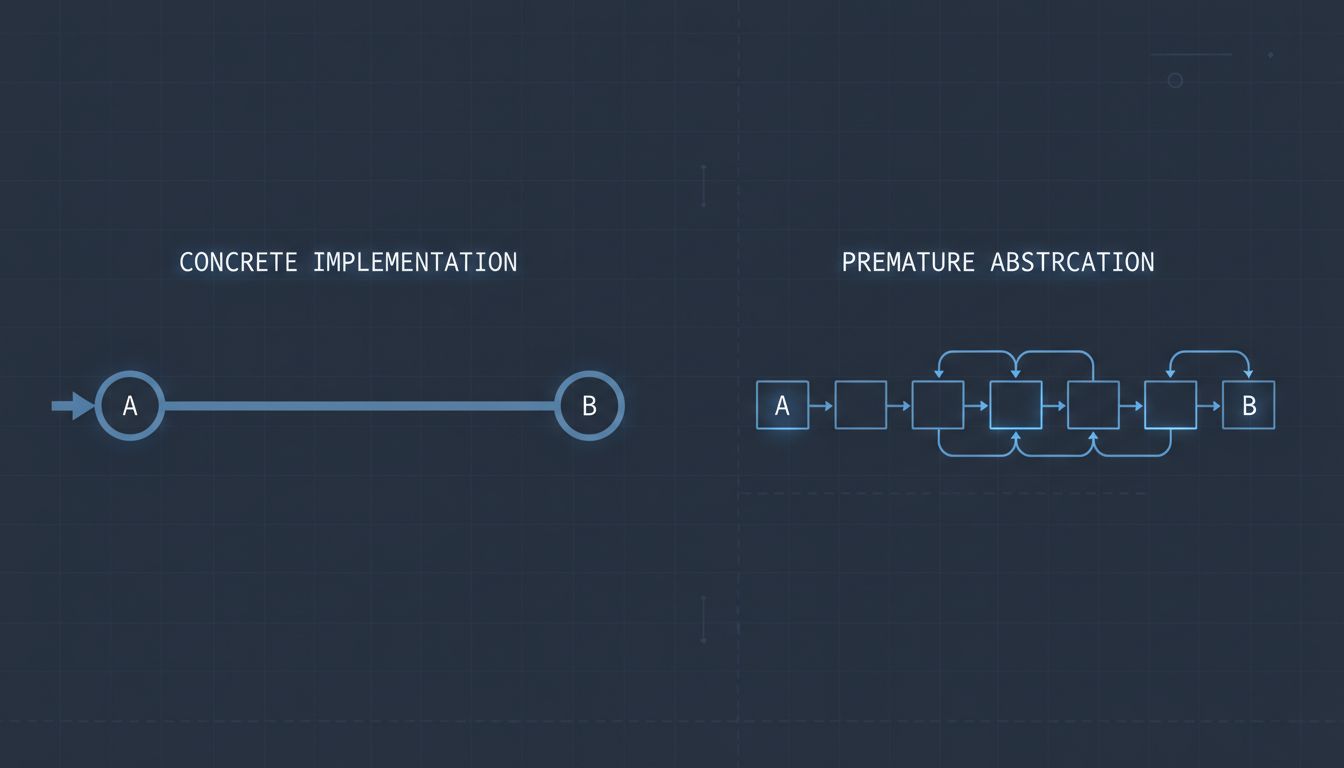
Optimization mistakes rarely do this. If you over-optimized a sort function for a dataset that turned out to be small, you didn’t constrain your system’s architecture. You just did some unnecessary work. You can undo it without redesigning anything.
The counterargument
The obvious objection is that good abstractions enable scale and collaboration. Without them, codebases devolve into spaghetti, and every engineer makes different local decisions that compound into chaos. This is true.
But the defense of abstraction in general is not a defense of abstraction that arrives before the thing being abstracted is fully understood. The rule of three exists for a reason: wait until you have three concrete cases before you generalize. In practice, many teams abstract after one, or before any. The pressure to appear “senior” or “architecturally minded” pushes engineers toward complexity they haven’t earned.
Knuth wasn’t wrong that optimization has its place and its time. The point is that you should do it when you have data, not when you have anxiety. The same logic applies to abstraction with even more force, because the blast radius is larger.
Ship the concrete thing first.
The practical upshot is simple. When you catch yourself building an abstraction, ask whether you have at least two real, concrete, currently-existing use cases that need it. Not hypothetical ones. Not use cases you expect to have in six months. Real ones, today. If you don’t, write the concrete implementation and move on.
You will sometimes under-abstract and have to refactor. That refactor will be easier than you fear, because you’ll do it with full knowledge of what the system actually does. That’s a much better position than maintaining an abstraction built on assumptions that aged poorly.
Premature optimization wastes hours. Premature abstraction wastes years.