The Obvious Win That Isn’t
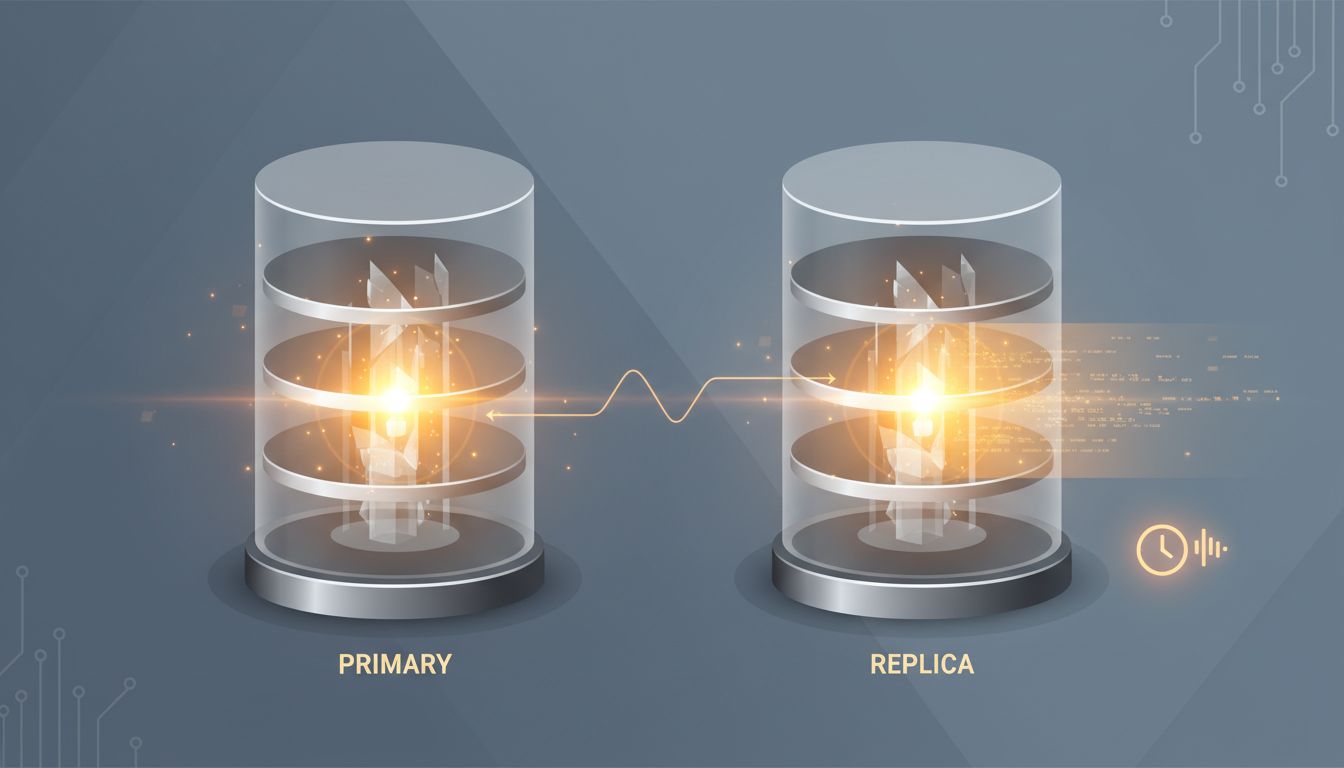
The pitch for read replicas is almost too clean. Your primary database is under load. Reads are overwhelming writes. The solution: spin up a replica, route your read traffic there, and watch your primary breathe again. No schema changes. No application rewrites. Just more database, pointed at the same data.
This is genuinely useful. Amazon RDS, Google Cloud SQL, and every managed Postgres service worth mentioning offer read replicas as a first-class feature, and teams adopt them constantly. The problem isn’t that read replicas don’t work. It’s that they work just well enough to obscure what they’re actually trading away.
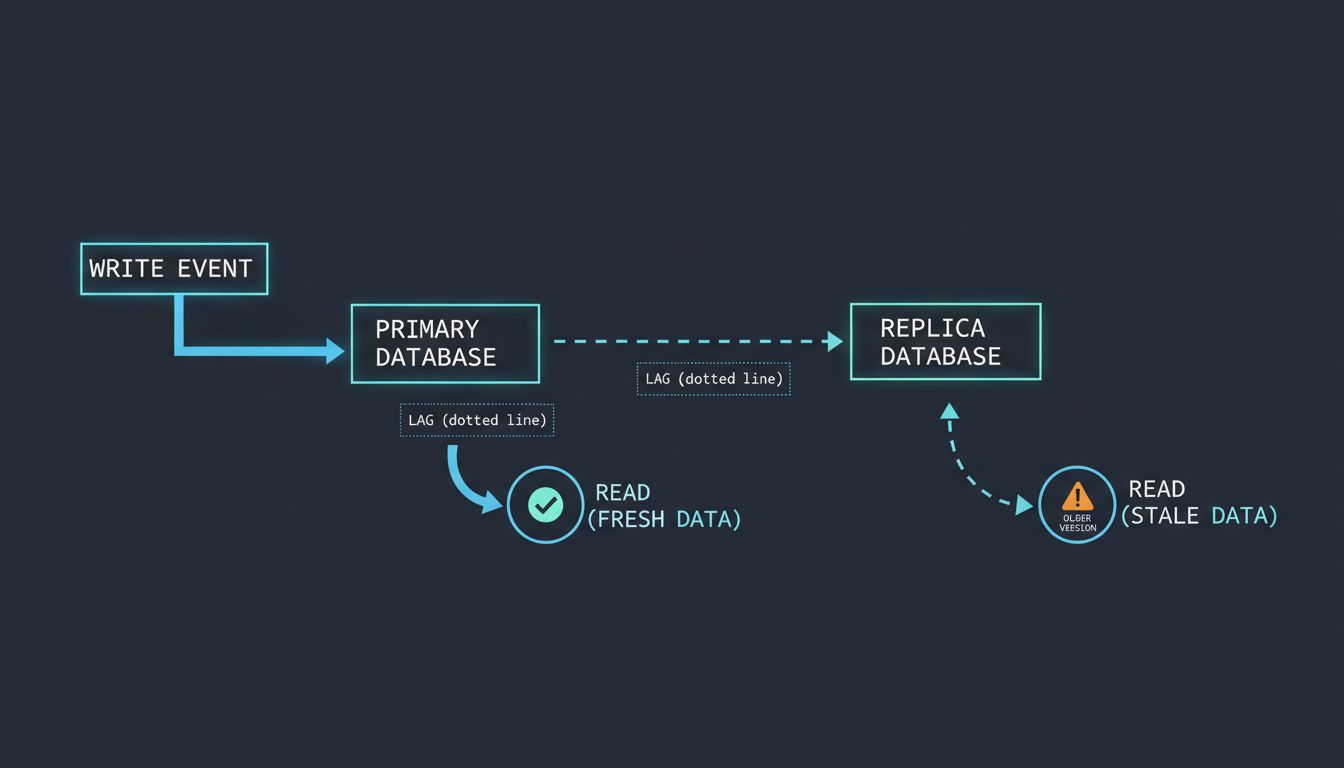
What they’re trading away is consistency. More precisely, they’re trading away the guarantee that a read reflects the most recent write. Replication lag, even in well-tuned systems, is real. It can be milliseconds. It can be seconds. In degraded network conditions or under heavy write load, it can be longer. The replica is always, to some degree, a snapshot of the past.
Most of the time, nobody notices. Then someone does.
Replication Lag Doesn’t Announce Itself
The failure mode for read replicas is insidious because it looks like correct behavior. The system returns data. The data is valid. It just isn’t current.
Consider a user who updates their email address and is immediately redirected to their profile page. If that profile page reads from a replica that’s two seconds behind, they’ll see their old address. They’ll hit refresh. Maybe they’ll see the new one, maybe not. In the best case, they assume a bug. In the worst case, they file a support ticket, try again, get confused, and tell someone the product is broken. They’re not wrong.
This class of problem, reading your own writes, is one of the canonical consistency anomalies in distributed systems. It’s well understood in academic literature. It’s less well understood in sprint planning. Teams reach for read replicas during a performance crisis, route most of their queries there to maximize the benefit, and then discover months later that certain workflows have been subtly broken for just as long.
The discovery often happens through a user complaint or an audit, not through monitoring. Replication lag metrics exist in most managed database services, but lag of two seconds doesn’t trigger alerts unless someone thought to configure them. And even then, the alert tells you the replica is lagging, not which user just read stale data.
The Architecture Decisions That Make It Worse
Read replicas become more dangerous as systems grow more complex. A single-replica setup serving a modest application is manageable. You can reason about where reads go and design around the edge cases. The problems compound when teams treat replicas as a scaling strategy rather than a targeted optimization.
The common progression: one replica for reporting queries, a second for the API’s read path, a third added during a traffic spike that never gets removed. Each replica introduces its own lag characteristics. Reporting queries might tolerate five-second lag without consequence. User-facing reads that inform subsequent writes cannot. When all of this runs through the same connection pool middleware, the distinction collapses.
Microservices make this worse still. In a monolith, you can often enforce a rule that writes and their immediate reads share a connection. In a service-oriented architecture, Service A writes to the primary and fires an event. Service B consumes that event and queries what it assumes is current data from its own database client, which is pointed at a replica. The data it reads may predate the write that triggered the event. The system is consistent eventually, but Service B has no way to know when “eventually” has arrived.
This is the environment where eventual consistency stops being a theoretical property and starts being a category of production incidents.
Routing Logic Is the Real Engineering Problem
The technical solution to most of these problems exists. It’s called read-your-writes consistency, and the implementation is straightforward in principle: after a write, route subsequent reads for that session to the primary until the replica is confirmed to have caught up, or for some fixed window of time. Many application frameworks and database proxies support this. ProxySQL, PgBouncer with careful configuration, and application-level session tracking can all enforce it.
The difficulty is that this logic has to be designed in deliberately. It doesn’t come for free. Engineers have to identify which read paths require strong consistency, instrument them differently, and maintain that distinction as the codebase evolves. In practice, this is the step that gets skipped. Teams add replicas for performance, the performance improves, and the consistency work lands on a backlog where it ages quietly.
There’s also a subtler problem with routing logic: it can erode the performance benefit it’s meant to preserve. If a significant fraction of your reads require read-your-writes consistency and get routed to the primary anyway, you’ve added operational complexity without fully offloading the primary. The replica handles the long-tail queries, the analytics, the background jobs. The primary still absorbs everything that matters most to users. That might be the right tradeoff, but it’s a different tradeoff than the one that justified the replica in the first place.
When the Tool Is Right and When It Isn’t
None of this means read replicas are a mistake. For specific workloads, they’re the right answer. Analytics and reporting queries are the canonical use case: long-running, read-heavy, tolerant of lag measured in minutes, and capable of bringing a primary to its knees if run there. Routing those queries to a dedicated replica is straightforwardly correct. Same for full-text search indexing pipelines, bulk data exports, and internal dashboards where a few seconds of lag is invisible to the user.
The mistake is treating replicas as a general-purpose solution to database performance. When teams route all reads to replicas by default, they’re optimizing for the average case while creating failure modes in the cases that matter most. User-facing writes are almost always followed immediately by reads that need to reflect those writes. That’s not an edge case. That’s the core of most interactive applications.
The deeper issue is that database performance problems usually have a root cause, and replicas don’t fix root causes. They redistribute load. Missing indexes, N+1 query patterns, unbounded result sets, queries that should be cached but aren’t: all of these survive a replica deployment intact. They just move. The performance gain from the replica buys time. Teams that use that time to address the underlying problems come out ahead. Teams that treat the replica as the solution tend to add more replicas.
There’s a useful parallel in how SQLite’s author approaches optimization: the instinct to reach for infrastructure before understanding the problem is almost always the wrong order of operations. Adding hardware, or in this case adding read capacity, can mask inefficiency rather than eliminating it.
The replica that runs faster than the original is real. So is the bug it’s hiding.