Every software project in history has arrived late. Not slightly late, not fashionably late, but catastrophically, embarrassingly, budget-shatteringly late. The Denver International Airport baggage system. The FBI’s Sentinel case management software. The Healthcare.gov launch. Engineers who built these systems were not incompetent. They were caught in a trap that has nothing to do with skill and everything to do with how humans model complexity.
The standard explanation, the planning fallacy, says people systematically underestimate how long tasks will take because they imagine best-case scenarios. That’s partially true but it’s also incomplete. The deeper problem is that software teams are routinely solving problems they haven’t fully discovered yet, and no estimation methodology can account for unknown unknowns that only surface after months of work.
The Iceberg Nobody Talks About in Sprint Planning
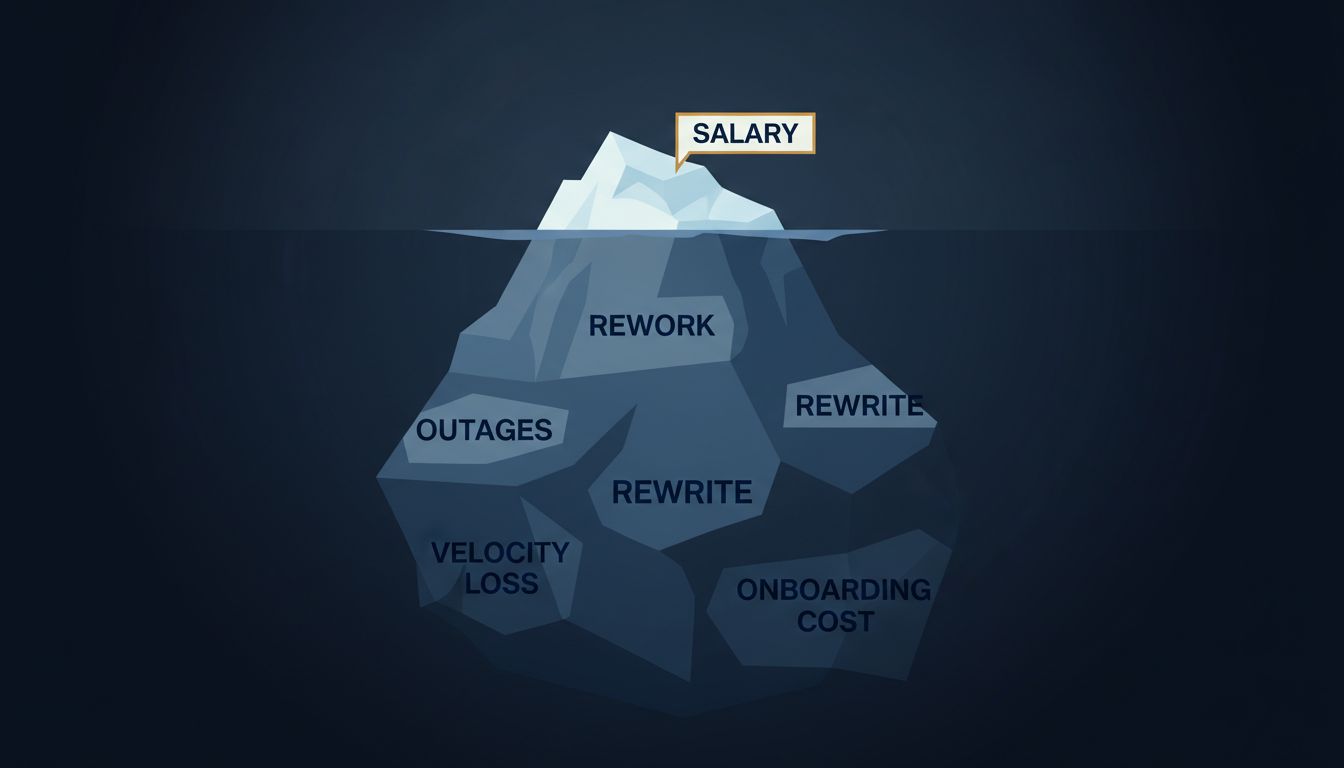
When a developer estimates a feature, they’re modeling a system they don’t yet fully understand. The visible work, writing the code, represents roughly 20 to 30 percent of the actual effort. The submerged portion includes integration points with legacy systems, edge cases that only appear at scale, security requirements that materialize mid-project, and the coordination tax imposed by every additional stakeholder who enters the room.
Fred Brooks identified one dimension of this in 1975 with his observation that adding engineers to a late project makes it later. What he called the “mythical man-month” problem is really a communication complexity problem. A team of two has one communication channel. A team of ten has 45. A team of fifty has 1,225. Each new channel is a new surface area for misunderstanding, rework, and delay.
This scales badly in ways that feel invisible until the project is already in trouble. Growing companies experience this acutely, often discovering that a software team which shipped reliably at 30 people becomes sluggish and expensive past 100, not because the engineers got worse, but because the coordination overhead metastasized.
Why Estimates Are Structurally Optimistic
Software estimates fail at a cognitive level before they fail at a technical one. Developers estimate in a mental state of clarity and focus, imagining uninterrupted hours of deep work. The actual workday looks nothing like that.
Context switching alone accounts for a staggering portion of lost productivity. Research by Gloria Mark at UC Irvine found it takes an average of 23 minutes to fully return to a task after an interruption. In a standard office environment with Slack notifications, stand-ups, code reviews, and impromptu debugging sessions, a developer might experience this recovery cost a dozen times per day. The hours are present on the calendar but the cognitive capacity is gone. Modern productivity tooling has made this structurally worse, not better, engineering constant interruption into the workflow under the guise of collaboration.
There’s also the problem of undocumented institutional knowledge. When an engineer estimates a task, they’re unconsciously assuming they’ll understand the codebase as well tomorrow as they do today. But software systems accumulate invisible debt. A function written three years ago under deadline pressure, with no explanation of why certain values are hardcoded, becomes a trap. The engineer who inherits it doesn’t just have to write new code. They have to reverse-engineer intent. This is precisely why documentation is undervalued until it’s catastrophically absent, and why the actual cost of that “quick fix” from 2021 often shows up in a project estimate in 2025.
The Hidden Tax of Discovered Requirements
The cruelest part of the estimation problem is that requirements don’t arrive complete. They arrive in waves, each revealing the inadequacy of what came before.
A product manager defines a feature. Engineers estimate it based on that definition. Development begins. Stakeholders see the first prototype and realize they didn’t explain what they actually wanted. The spec changes. The estimate doubles. Security reviews the architecture and identifies vulnerabilities. The estimate doubles again. Legal needs a compliance review. The timeline slips another quarter.
None of this is dysfunction. It’s the normal process of a group of humans trying to build something that has never existed before. The dysfunction is in treating it like a manufacturing problem where inputs reliably produce predictable outputs.
Mature engineering organizations have learned to build in buffers, but they’ve also learned something more useful: the shape of uncertainty changes depending on the type of work. Routine work on well-understood systems can be estimated with reasonable accuracy. Novel work on new systems, or work that requires integrating with external dependencies, carries multipliers that no spreadsheet captures adequately. Senior engineers know this instinctively, which is why they code defensively, building for failure modes that haven’t been specified because they understand that discovered requirements always include discovered disasters.
What Actually Works
The most reliable approach to software estimation isn’t a better formula. It’s a different philosophy about what estimation is for.
Estimates are not commitments. They are opening bids in a negotiation about scope. The companies that ship on time have largely internalized this distinction. They scope aggressively, cutting features ruthlessly to protect timeline integrity. They treat a deadline as a fixed constraint and scope as a variable, rather than the reverse. They run small, and they resist the organizational pressure to staff up when a project falls behind, knowing that the coordination costs will consume whatever gains the new headcount was meant to provide.
They also strip out the tools and meetings that fracture attention, recognizing that uninterrupted focus time is the actual unit of software production, not hours logged in a project management system.
The 10x overrun isn’t a mystery. It’s a predictable outcome of treating software as a known quantity when it is, by definition, the construction of something that didn’t previously exist. The engineering is often the easy part. It’s the discovery of what you’re actually building that takes the time.
That won’t appear in any estimate. And that’s precisely the problem.