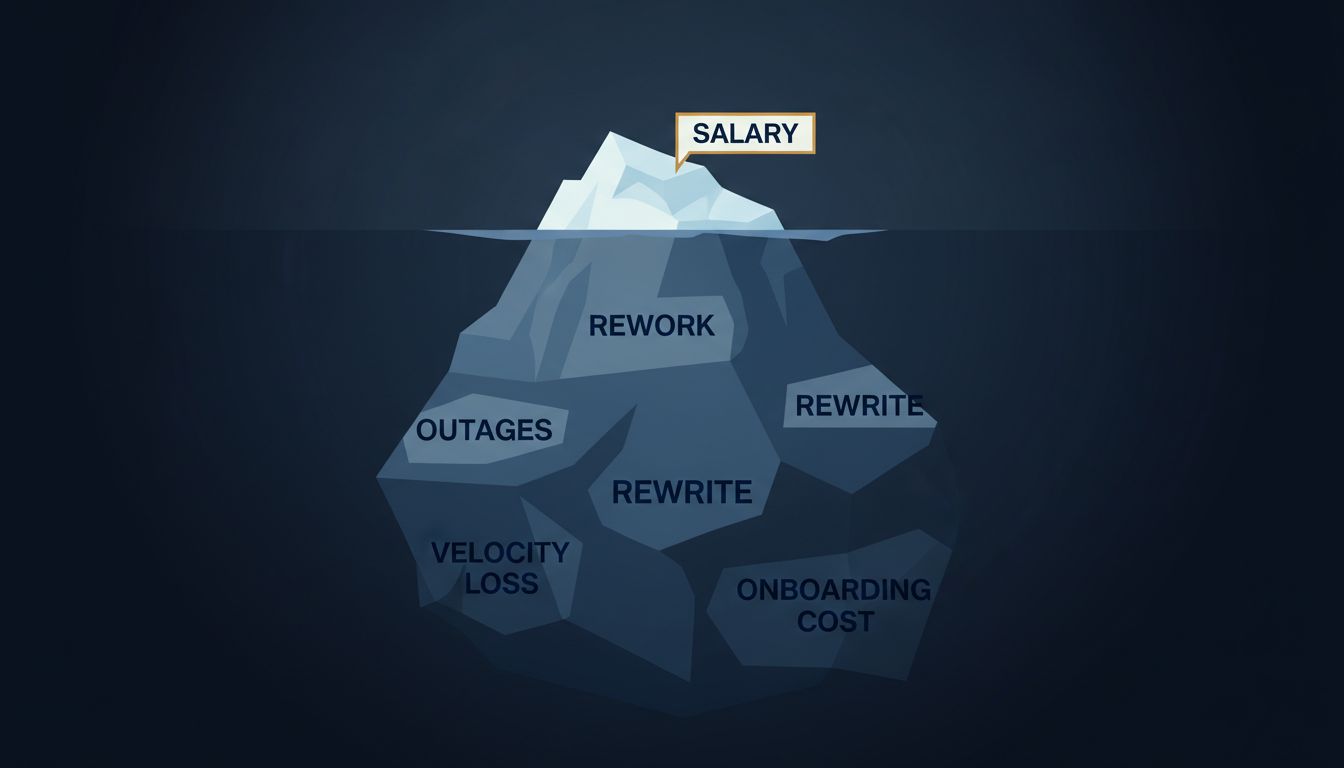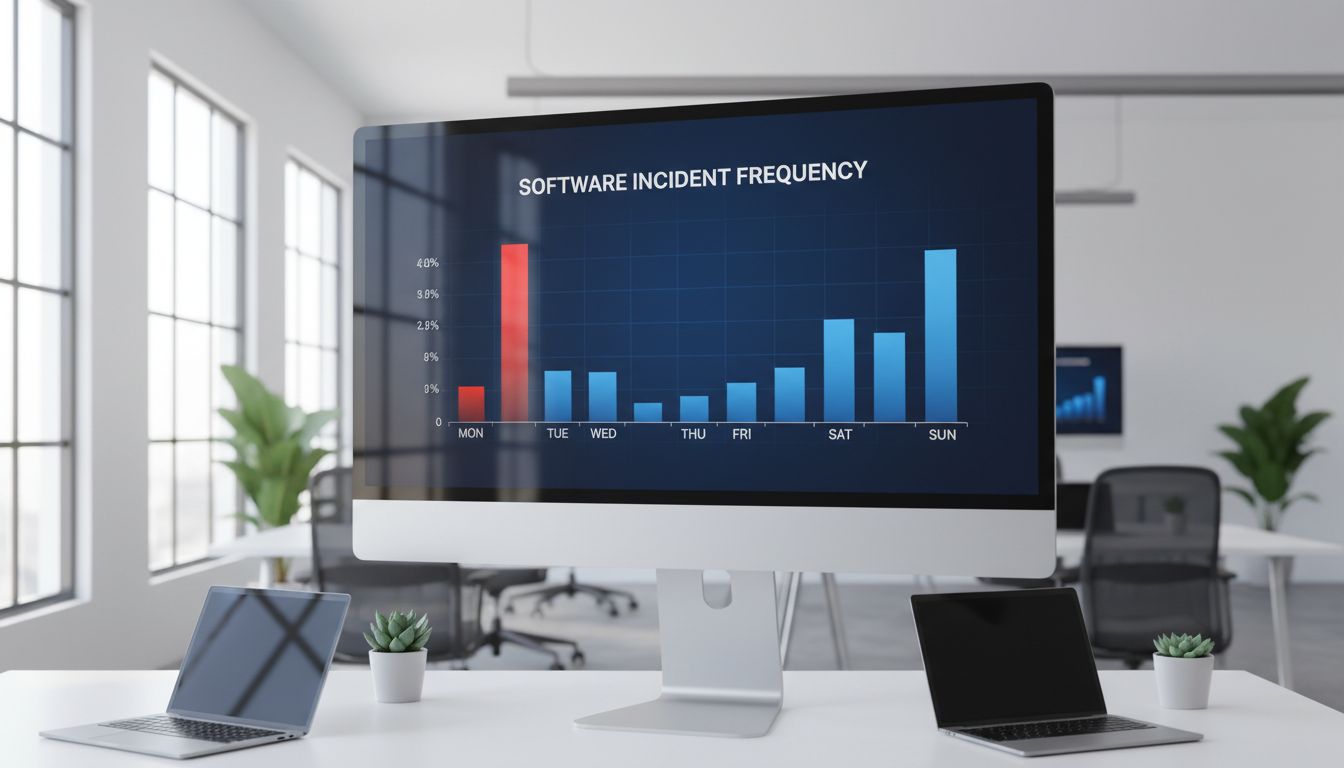
There is a pattern hiding in every major incident report database, in the post-mortems of Fortune 500 engineering teams, and in the on-call logs of companies running everything from banking infrastructure to video streaming. Software breaks more often on Monday than on any other day of the week. Not by a small margin. Studies of incident frequency across large-scale distributed systems consistently show Monday failure rates running 20 to 40 percent higher than the weekly average. The question worth asking is not whether this is true. It is why, and what that answer reveals about how the technology industry actually works.
The Deployment Window Problem
The most immediate cause is timing. Engineering teams at most companies operate on a weekly deployment cycle, and the dominant pattern across the industry places the largest batch of code releases on Thursday or Friday. The reasoning seems sound at the time: ship by end of week, let the weekend act as a buffer, have engineers available to monitor before they disconnect for the weekend.
The logic inverts almost immediately. What actually happens is that code ships Friday afternoon, engineers spend the weekend mentally offline, and by Sunday night the new deployment has been quietly accumulating edge cases in production. Monday morning arrives, user traffic spikes as the business day begins, and suddenly that quiet accumulation becomes a loud, visible failure.
This is not a fringe pattern. Google’s Site Reliability Engineering documentation, Atlassian’s incident research, and PagerDuty’s annual State of Digital Operations reports all point toward the same concentration of incidents in early-week windows. The code was always going to fail. Monday is simply when enough people show up to notice.
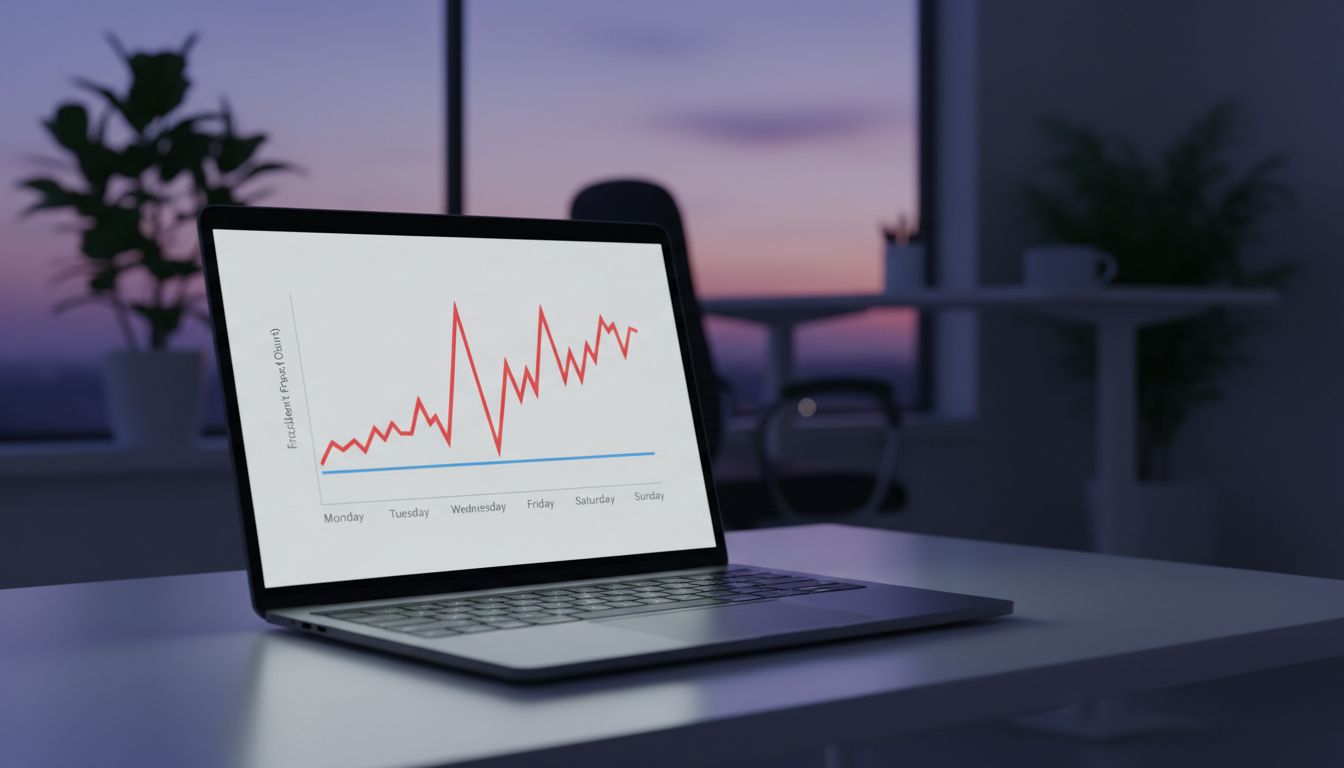
The Human Infrastructure Underneath
But deployment timing is only the surface explanation. The deeper cause is what happens to human attention over a weekly cycle, and how modern engineering organizations have built their workflows around rhythms that systematically concentrate risk.
Consider what Friday afternoon looks like inside a software company. Engineers are mentally closing loops, rushing to hit weekly goals, and facing the gravitational pull of the weekend. Code reviews get shorter. Staging environment tests get abbreviated. The careful, slow thinking that good software review requires is the first casualty of a 4:30 PM Friday deadline.
There is a reason that the most productive technical thinkers often reach for analog tools when they need to slow down and think carefully. The neuroscience of deliberate, friction-rich thinking suggests that our best critical analysis happens when we resist the pull toward speed. The Friday deployment rush is the opposite of that environment.
Monday then compounds the problem from the other direction. Engineers returning from the weekend face the full weight of accumulated alerts, backlogged messages, and context-switching demands before they have fully re-engaged with complex system knowledge. The cognitive re-entry cost of understanding a distributed system is not trivial. It can take hours to rebuild the mental model of a production environment you were not thinking about for two days. That is precisely the window when an incident requiring deep system knowledge tends to arrive.
The On-Call Economics Nobody Talks About
There is a third layer to this, and it sits firmly in the domain of economics rather than engineering. On-call rotations at most companies are structured to minimize cost and inconvenience to the organization, which in practice means that weekend coverage is thin, experienced engineers are rarely on primary rotation on Sunday nights, and escalation paths are slower.
This creates a perverse incentive structure. The people most capable of catching a brewing problem before it becomes a full incident are the least likely to be watching on Sunday evening when the new deployment starts accumulating failures. By Monday morning, a situation that might have been a five-minute fix at 10 PM Sunday becomes a two-hour incident at 9 AM Monday, with cascading effects on users, support teams, and business metrics.

This is the same dynamic that governs how companies approach risk in other strategic contexts. Tech companies frequently build systems that serve internal needs better than external ones, and the gap between what they build for themselves versus what they deploy for users reveals where the real incentives lie. On-call infrastructure is a version of this: internal tooling for incident management is often excellent, while the structural decision-making around when to ship and who watches the systems remains stuck in patterns optimized for organizational convenience rather than system reliability.
What the Monday Pattern Actually Costs
The economic cost of this pattern is significant and largely invisible in standard accounting. A major incident on a Monday morning does not just affect engineering hours. It affects sales calls that get interrupted, customer success escalations that consume account management bandwidth, and the compounding trust erosion that happens when enterprise customers experience repeated early-week outages.
Gartner’s estimates of enterprise IT downtime costs have historically ranged from $5,600 to over $9,000 per minute for large organizations. Even for mid-sized software companies, a two-hour Monday incident represents a cost that dwarfs the salary expense of whatever was saved by thinning weekend on-call coverage.
The math rarely gets done explicitly, which is why the pattern persists. Companies optimize for the visible cost (on-call pay, weekend staffing) while the invisible cost (incident damage, customer churn risk, engineer burnout from Monday fire drills) gets absorbed into general operating noise.
How Companies That Solve This Actually Do It
The engineering organizations that break the Monday crash pattern do not primarily solve it with better monitoring tools or smarter alerting. They solve it by changing the human rhythms that generate the risk in the first place.
The most effective interventions cluster around three changes. First, moving significant deployments away from Thursday and Friday, establishing Tuesday and Wednesday as primary release windows so that the monitoring period falls within normal working hours with full team capacity. Second, enforcing what some teams call a deployment freeze window, typically from Thursday afternoon through Monday morning, for anything touching core infrastructure. Third, restructuring on-call rotations so that the most experienced engineers hold primary coverage during the highest-risk periods rather than the most junior members.
None of this is technically complex. All of it requires organizational will to override the short-term convenience of shipping before the weekend. The companies that do it consistently report not just fewer Monday incidents but higher overall system reliability, because the discipline required to hold a deployment freeze is the same discipline that produces better code review and more careful testing throughout the week.
The Monday crash problem is, in the end, a measurement problem disguised as a technical one. The systems are doing exactly what human incentives have trained them to do. Change the incentives, and the crashes move with them.