Picture this: a software team has spent three years building a product that works. Users love it. Revenue is growing. And then, almost predictably, someone in a planning meeting says the words every product manager dreads: “I think we need to rewrite this from scratch.” It happens at startups, at enterprises, at companies you admire. And if you’ve been around software long enough, you’ve probably either said those words yourself or watched someone else say them with complete sincerity.
Boring technology wins, and the most successful startups already know this, which makes the compulsion to rewrite even more fascinating. Why do smart engineers, who intellectually know rewrites are risky and expensive, keep reaching for that nuclear option?
The Code Isn’t the Problem. The Context Is.
Here’s the thing most people miss when they talk about rewrites: the original code usually wasn’t bad when it was written. It was a rational response to the information available at the time. The team knew three things needed to work, they made reasonable tradeoffs, and they shipped.
But software exists in a context, and that context shifts constantly. The database that made sense for 1,000 users starts groaning at 1,000,000. The monolithic architecture that let a five-person team move fast becomes a bottleneck when 50 engineers are stepping on each other’s work. The third-party API you built around gets deprecated. The regulatory environment changes. The business model pivots.
The code didn’t get worse. The world around it moved, and the code stayed still.
This is the real driver behind most rewrites. Engineers aren’t chasing novelty (though that’s a factor we’ll get to). They’re responding to a genuine mismatch between what the system was designed to do and what it now needs to do. When that gap gets wide enough, patching starts to feel like fighting physics.
The Accumulation of Invisible Decisions
Every codebase is a museum of past decisions. Some of those decisions were brilliant. Many were made under time pressure, with incomplete information, by people who have long since left the company. A few were just wrong.
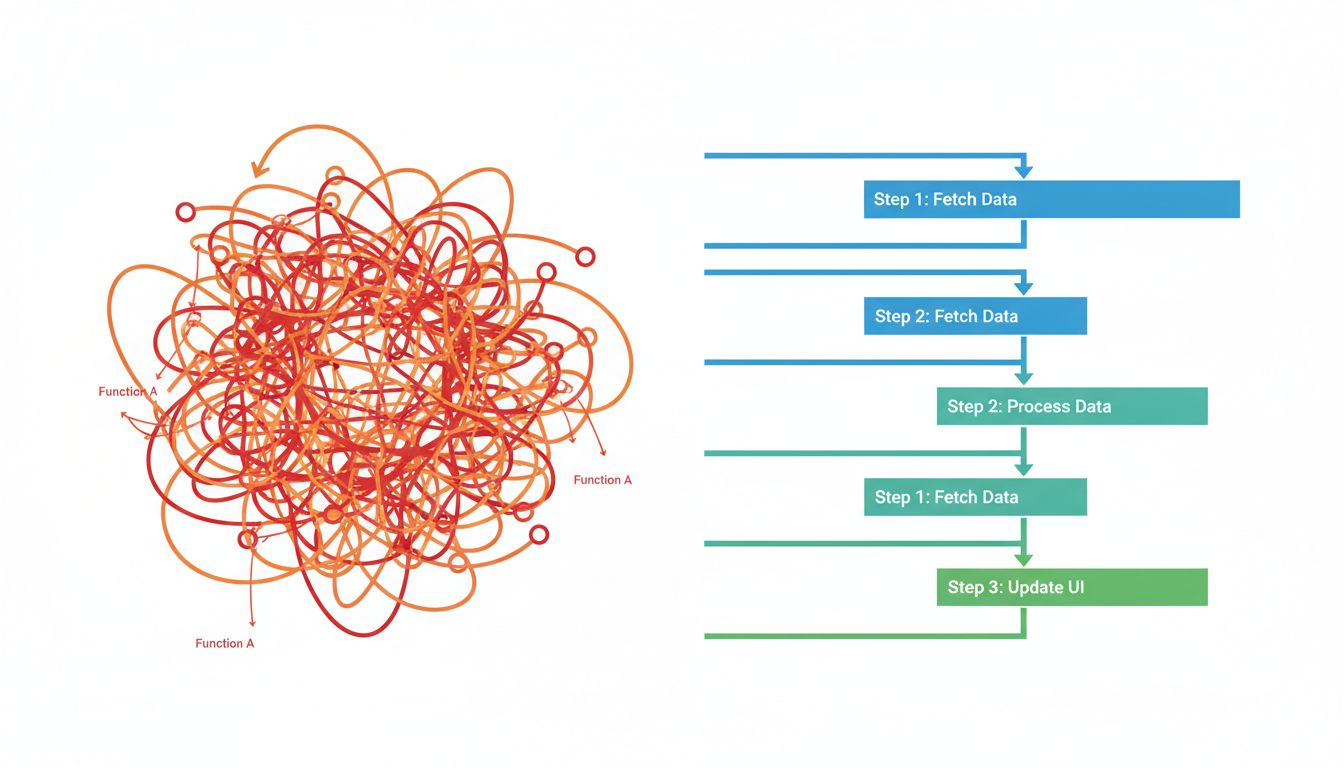
The problem is that these decisions layer on top of each other. A workaround for a bug in 2019 becomes load-bearing infrastructure by 2023. A temporary data structure that “we’ll fix later” becomes the foundation five other systems depend on. Engineers start navigating around landmines rather than building new features.
This phenomenon has a name: technical debt. But that framing undersells it. Debt implies you know exactly what you owe and to whom. Technical debt is more like sediment. It builds up quietly, slows everything down, and by the time you notice how thick it’s gotten, excavating it carefully feels harder than just starting fresh.
There’s also a psychological dimension here. When you inherit a system you didn’t build, you don’t have the mental model that the original authors had. You can read the code, but you can’t always read the reasoning. Software updates keep breaking things that worked fine, and that’s often by design, but sometimes the breakage comes from engineers who simply don’t know which stones they shouldn’t move.
The New Tool Problem (And Why It’s Legitimate)
Let’s be honest about something: engineers are genuinely excited by new tools and paradigms. That enthusiasm gets mocked, sometimes fairly, as resume-driven development or technology tourism. But there’s a legitimate version of this impulse that deserves more respect.
Programming languages and frameworks don’t just change style. They change what’s possible. Moving from a callback-heavy JavaScript codebase to a modern async/await pattern isn’t cosmetic. It makes the code dramatically easier to reason about, which means fewer bugs and faster iteration. Shifting from a manually managed server infrastructure to containerized deployments isn’t chasing trends. It’s accessing capabilities that genuinely didn’t exist before.
The question isn’t whether new tools are better. Often they are. The question is whether the improvement is worth the cost and risk of migration. That’s a hard calculation, and engineering teams get it wrong in both directions. Some teams rewrite too eagerly and pay a brutal price in lost velocity and introduced bugs. Others cling to aging systems until the accumulated drag makes them genuinely uncompetitive.
The companies that navigate this well tend to treat rewrites like surgery rather than renovation. They isolate components, replace them incrementally, and maintain a working system throughout. The big-bang rewrite, where you shut down new feature development and rebuild everything at once, has a famously poor track record.
What the Engineering Team Is Really Telling You
If you’re a founder, product manager, or executive and your engineering team is asking for a rewrite, it’s worth pausing before either approving or rejecting it. In many cases, the request is a signal about something deeper.
Sometimes it means the system genuinely can’t support the next phase of growth without fundamental changes. Sometimes it means the team feels like they can’t be proud of what they’re working on, which is a retention and motivation issue as much as a technical one. And sometimes it means the team hasn’t been given enough time and resources to address technical debt incrementally, so it has built up to the point where a rewrite feels like the only relief valve.
Tech companies hire overqualified engineers on purpose, and one consequence is that engineers with experience building systems at scale will feel the friction of a poorly architected codebase acutely. That friction is real, and dismissing the rewrite conversation without understanding what’s driving it is a mistake.
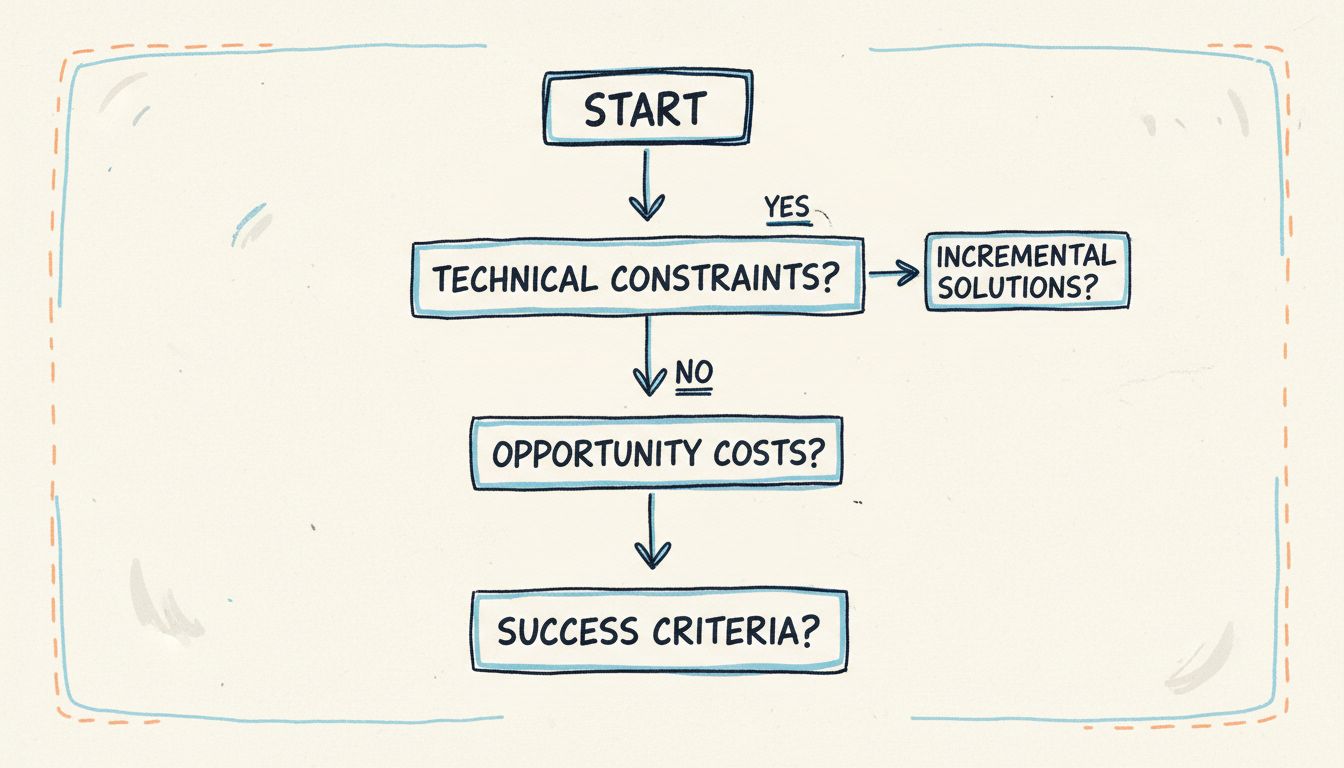
A practical framework for evaluating these requests:
- Identify the actual constraint. Is the problem performance, developer velocity, security, or maintainability? Name it specifically.
- Ask whether the constraint can be addressed incrementally. A targeted refactor of the problematic component is almost always cheaper and less risky than a full rewrite.
- Estimate the opportunity cost. What features or improvements won’t get built while the team is rewriting infrastructure?
- Set measurable success criteria. If you approve a rewrite, define what “done” looks like and how you’ll measure whether it achieved the goal.
The Uncomfortable Truth About Code Lifespan
Here’s what nobody tells junior engineers and what senior engineers have learned to accept: code has a natural lifespan. Not because it rots on its own, but because the world it was written for keeps evolving. A codebase that serves a business well for five to seven years before needing significant structural work isn’t a failure. It’s actually a pretty good outcome.
The teams that handle this well are the ones who treat architectural evolution as a normal, planned part of the development cycle rather than an emergency response to a crisis. They invest in documentation so decisions are understandable to future engineers. They refactor regularly so debt doesn’t compound. They evaluate new tools critically rather than reflexively adopting or rejecting them.
And when a genuine rewrite is warranted, they scope it narrowly, execute it carefully, and resist the temptation to also redesign everything else while they’re in there.
The goal isn’t to write code that lasts forever. It’s to write code that serves you well until you understand the problem well enough to write something better.