When millions of users flood a platform simultaneously, the instinct is to push every server to its absolute limit. More speed, more capacity, more throughput. That instinct is wrong, and the companies that figured this out are running some of the most reliable infrastructure in the world. The counterintuitive truth is that throttling your fastest servers during peak demand is not a failure of engineering. It is the engineering.
This logic mirrors a broader pattern in tech where deliberate constraints produce better outcomes than unchecked speed. The business case for intentional slowdowns is rooted in thermodynamics, queuing theory, and cold financial math.
The Physics of Overloaded Systems
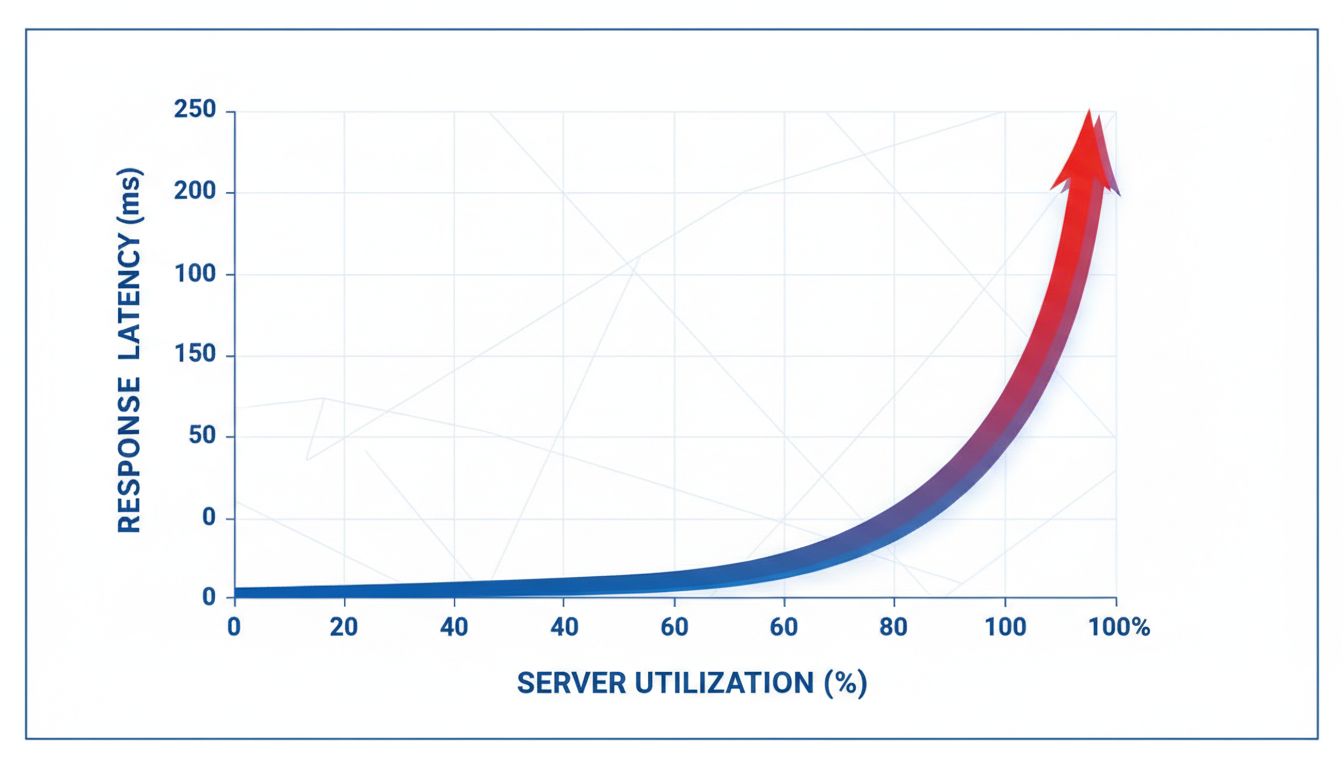
A server running at 100 percent capacity does not deliver twice the output of one running at 50 percent. It delivers chaos. This is a well-documented phenomenon in systems engineering called the “utilization cliff.” Response times do not degrade linearly as load increases. They collapse exponentially. A server at 70 percent utilization might handle requests in 50 milliseconds. Push it to 95 percent and that same request can take 800 milliseconds or more, with failures cascading across dependent systems.
Google’s Site Reliability Engineering documentation, which the company made public, explicitly warns against crossing the 70 percent utilization threshold in production systems. Netflix, which serves over 200 million subscribers across peak evening hours, applies traffic shaping that intentionally routes some requests through slower processing paths to prevent any single cluster from spiking above safe thresholds. The result is a slightly slower average response, but near-zero catastrophic failures.
The math works like this: one second of additional latency applied proactively to 10 percent of requests is far less costly than a full outage lasting three minutes for all users. Amazon’s own research has estimated that every 100 milliseconds of latency costs roughly one percent of sales. A full outage multiplies that damage by orders of magnitude.
Traffic Shaping as Financial Strategy
Throttling is not just about keeping servers stable. It is about managing infrastructure costs against a demand curve that is never flat. Cloud computing bills are calculated in ways that punish burst consumption. AWS, Azure, and Google Cloud all charge premium rates for compute resources consumed above baseline commitments. A company that allows unconstrained peak usage can face infrastructure bills two to three times higher in a single month than their baseline average.
This connects directly to how smart tech companies think about debt and capital efficiency. The same logic that drives early-stage startups to take on debt strategically applies to infrastructure planning. Spending aggressively on burst capacity creates a liability on the balance sheet, while rate-limiting smooths that curve and keeps costs predictable.
Spotify, for example, uses a technique called adaptive bitrate streaming that reduces audio quality incrementally during high-demand windows. Users rarely notice a shift from 320 kbps to 256 kbps. But across hundreds of millions of simultaneous streams, that reduction in data throughput translates directly into lower bandwidth costs and reduced server load, often cutting peak infrastructure expenses by 15 to 25 percent.
The Queue Is the Product
One of the less obvious consequences of deliberate throttling is what it does to the user experience of waiting. Engineers who think seriously about system resilience understand that a well-managed queue feels different to users than a system that simply fails. A loading spinner that moves is tolerable. A frozen screen with no feedback is not.
This is why the best infrastructure teams do not just throttle, they throttle with transparency. Ticketmaster’s queue system, despite its other well-documented problems, pioneered a model where users are told explicitly that they are waiting, shown a position number, and given an estimated time. That transparency, built on top of intentional request throttling, dramatically reduces abandonment rates compared to systems that simply fail silently under load.
Senior engineers who build these systems think about failure in advance rather than reacting to it after the fact. As explored in how senior developers write code for disasters that haven’t happened yet, the discipline of anticipating load conditions is what separates infrastructure that lasts from infrastructure that occasionally works.
Why Full Speed Is a Trap
There is a cultural pressure in tech to celebrate raw performance. Benchmark scores, response times, and throughput numbers are status symbols within engineering teams. This creates an organizational bias toward letting systems run fast, even when running fast is the wrong choice.
The trap is that maximum speed during peak load creates hidden costs that never appear on the server metrics dashboard. They appear later, in customer support tickets, in churn data, in the engineering hours spent post-mortem on failures that were entirely predictable. A system that never crashes but occasionally runs at 80 percent of peak speed is worth more in practice than a system optimized for top speed that fails twice a month.
Cloudflare has published internal data showing that their rate-limiting and traffic shaping systems, which intentionally delay or redistribute some percentage of requests, have reduced major incident frequency by over 60 percent compared to their earlier architecture. The trade-off is invisible to users. The operational savings are very visible to their finance team.
The Counterintuitive Competitive Advantage
Deliberate slowdowns, when implemented well, become a competitive advantage rather than a limitation. Reliability compounds over time. Users who experience consistent, predictable performance, even if it is not always the absolute fastest possible, develop trust that translates into retention. Users who experience occasional fast performance punctuated by crashes develop the opposite.
This pattern shows up repeatedly across tech economics. The companies deliberately hiding their most powerful retention tools understand that reliability is a retention tool as powerful as any feature. Infrastructure stability is just that tool operating at the foundational layer.
The companies doing this best treat their infrastructure the way experienced athletes treat effort in endurance events. Going all-out from the start guarantees a collapse before the finish line. Measured pacing, with reserves held back deliberately, produces better final outcomes. The fastest server in the data center, running at full throttle during your biggest traffic day, is not your greatest asset. It is your greatest risk.