The server sitting in a data center right now, handling your workload, is almost certainly faster than the tier you’re paying for. The cloud provider knows this. They built it that way on purpose.
This is the defining economics of modern cloud infrastructure, and it deserves to be stated plainly: when Amazon, Google, and Microsoft sell you compute at different price points, they are frequently selling you the same physical hardware with different software governors applied. The performance gap between a basic instance and a premium one often has nothing to do with different components. It has everything to do with deliberate restriction.
The Chip That Ships in Three Flavors
Intel pioneered the clearest version of this in consumer hardware. For years, the company manufactured a single silicon die and sold it as multiple product lines, with lower-end chips having cores, cache, and clock speeds disabled in firmware. The economics were straightforward: a production line optimized for one chip design runs more efficiently than multiple parallel lines. Chips that tested imperfectly could be downgraded and sold at a lower margin rather than discarded. The “product tiers” were a fiction imposed on top of a manufacturing reality.
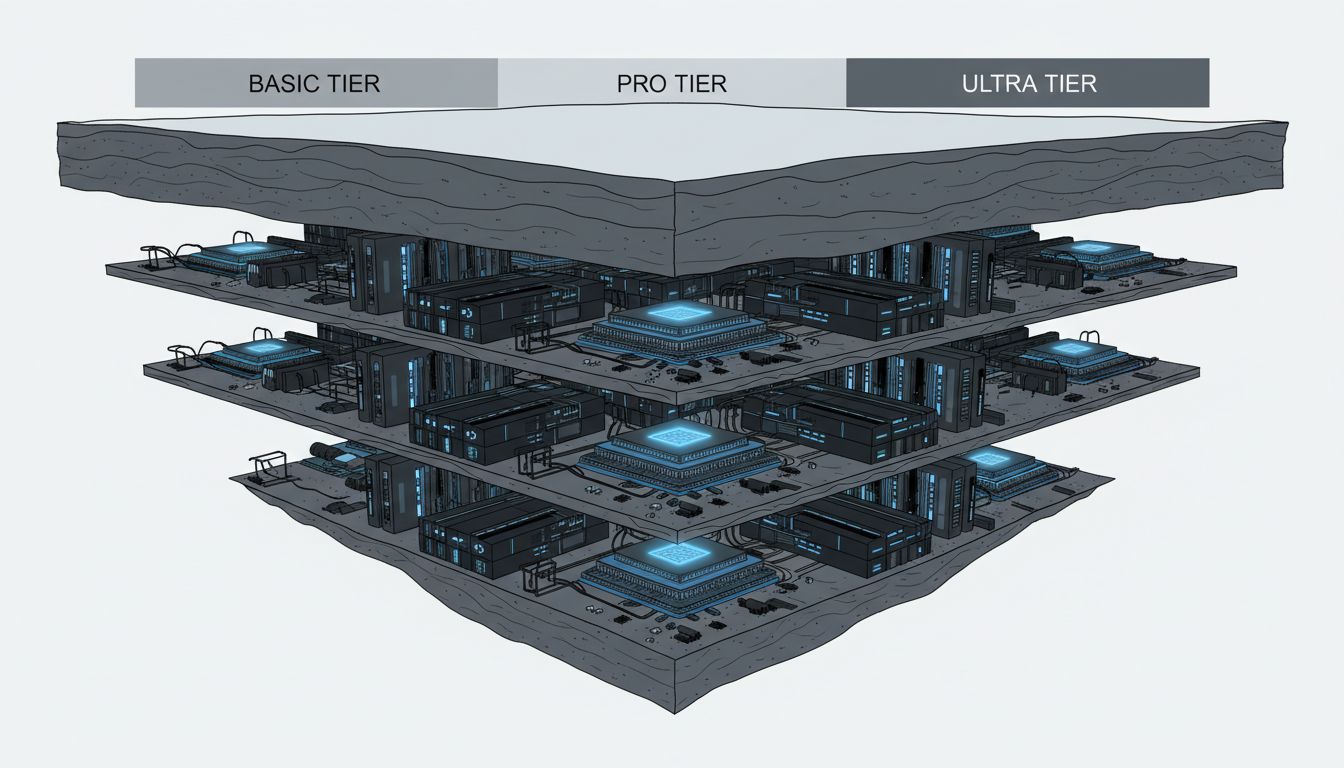
Cloud providers have replicated this logic at massive scale. AWS instance families, Google Cloud machine types, and Azure VM series all involve physical servers that could, in principle, run at higher specifications than any given tier permits. Network throughput caps, CPU credit systems on burstable instances (the T-series on AWS is the most explicit example), and I/O throttles are implemented in the hypervisor layer. The underlying hardware is not the constraint. The pricing model is.
Differential Pricing Requires Artificial Differentiation
The reason companies do this is not malice. It is the oldest problem in economics: how do you charge different customers different prices for what is fundamentally the same thing?
Price discrimination, in the formal economic sense, requires that customers cannot easily move between tiers. If everyone could access the fastest possible instance at the base price, providers would lose the revenue from customers who genuinely need high performance and will pay for it. By installing a software governor on a fast machine, a provider creates a believable reason for the tier gap. The enterprise customer who needs consistent network throughput has to pay for the tier that removes the cap, even if the physical hardware underneath both tiers is identical.
This is not unique to cloud computing. Airlines seat the same passengers in the same aircraft at prices that vary by a factor of ten. The premium cabin is not a different plane. But the cloud version is more interesting because the product being throttled is, in a meaningful sense, artificial. You can upgrade an airplane seat in ways that are physically real. A software-imposed CPU cap is a fiction that the vendor can remove with a configuration change.
The practice connects to a broader pattern in how tech companies build features they never actually launch: sometimes the point of a technical capability is to define what sits above and below it on a pricing sheet.
The Burstable Instance Is the Admission
The most honest acknowledgment of deliberate throttling is the burstable compute instance, and AWS, Google, and Azure all offer versions of it. The premise is explicit: you get a baseline level of CPU performance, with the ability to “burst” to full capacity when you accumulate enough credits. The mechanism is a direct admission that the underlying hardware can run faster. The provider is choosing not to let it.
For many workloads, this is actually a reasonable trade. A lightly loaded application server does not need full CPU access continuously, and paying for it continuously would be wasteful. The customer buys the throttled version and gets what they need most of the time. The problem arises when that same customer hits a sustained load spike, finds their credits exhausted, and watches their application crawl on hardware that is physically capable of running it at full speed. The hardware did not change. The permission did.
The Counterargument
The strongest defense of this practice is that it actually lowers prices for most customers. If cloud providers had to sell compute at a single undifferentiated price, that price would be higher than what most small workloads require. Tiered pricing, even when it is based on artificial restriction, allows providers to spread fixed costs across a wider customer base. The startup paying for a small burstable instance is subsidized, in a sense, by the enterprise paying full price for the unrestricted tier.
This argument is real and not trivial. But it does not justify opacity. The problem is not that throttling exists. The problem is that most buyers do not know they are purchasing a restricted version of hardware that could serve them better. A customer who understands they are buying a capped instance can make an informed decision. A customer who thinks they are buying genuinely different hardware cannot.
What Informed Buyers Should Do
The practical implication is that cloud pricing should be read as a permission structure, not a hardware specification. When you see a performance limit in a tier description, you are not reading about a physical constraint. You are reading about what the vendor has decided to allow at that price. That reframes the negotiation: large contracts often include instance types and throughput guarantees that are not available on the public pricing page, because “enterprise pricing” is partly the vendor agreeing to loosen the governor.
Sophisticated engineering teams already operate this way. They benchmark across instance types, identify where the artificial floors are, and make tier decisions based on actual measured performance rather than marketing descriptions. Everyone else is paying for restrictions they did not know existed.
The servers are fast. You just have to pay to find out how fast.