Picture this: a 12-person startup is paying a brilliant, slightly chaotic engineer $140,000 a year. She ships features solo, holds the entire codebase in her head, and once fixed a production bug from her phone while on a hiking trail. Two years later, that same startup has 200 employees. They just hired a new senior engineer for $210,000. He needs three meetings to make a decision, writes documentation nobody reads, and hasn’t touched a line of code in production without a pull request review chain that takes four days. And here’s the thing: the company made the right call hiring him.
This is one of those things that looks insane from the outside but is completely logical once you understand what actually changes when a tech company scales. It’s not that big companies are dumb. It’s that the job fundamentally changes, and most people never update their mental model of what “good programmer” means once the org chart gets complicated.
Senior developers who write code for disasters that haven’t happened yet are already thinking this way. The question is whether your company can afford to hire them before it actually needs them.
The Startup Programmer Is a Different Species
In the early days, the best programmer is the one who can do the most with the least. Speed matters more than process. Shipping matters more than documentation. One person who can hold the whole system in their head is worth five people who need to coordinate before doing anything.
That archetype, brilliant, fast, slightly feral, is genuinely perfect for companies under 50 people. They can make unilateral decisions because the blast radius of a bad call is small. They can skip documentation because they ARE the documentation. They can ship buggy code on a Friday afternoon because they’ll be around Saturday morning to fix it.
But something breaks down around the 80-to-120 employee mark. Every company I’ve watched go through this phase hits the same wall. The cowboy engineer who was your secret weapon becomes a liability, not because they got worse, but because the system around them changed.
Why Coordination Costs Change Everything
Here’s the economics nobody talks about at the Series B all-hands meeting.
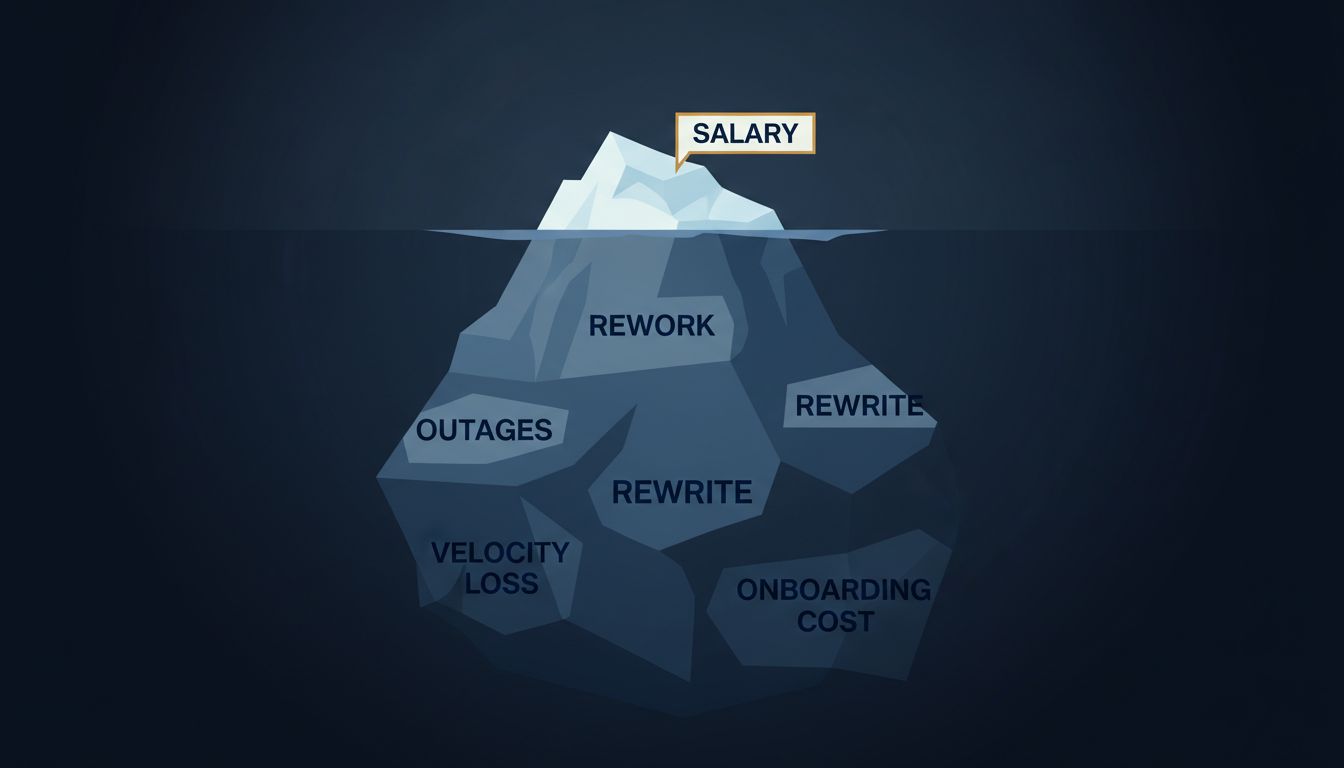
When you have 10 engineers, communication paths between them total 45. When you have 50 engineers, that number jumps to 1,225. At 100 engineers, you’re looking at nearly 5,000 potential communication paths. The math here is brutal: n*(n-1)/2, and it scales quadratically.
This is why the “10x programmer” who thrives in small teams becomes expensive at scale, and not just in salary. Their unwillingness to write clear, useful code comments means every new engineer they onboard costs two extra weeks of ramp-up time. Their preference for moving fast means the codebase accumulates debt that eventually requires a full quarter of remediation work. Their lone-wolf approach means institutional knowledge lives in one person’s head, which is one resignation letter away from catastrophe.
The slower, more expensive, more process-oriented engineer actually reduces total system cost once the org hits a certain size. They write code that other people can read. They create processes that work without them in the room. They make the whole machine cheaper to operate, even if their individual output looks worse by any single-contributor metric.
The Interview Process Breaks Down at Scale Too
Here’s where it gets really painful. Most tech companies don’t update their hiring criteria when they scale. They keep interviewing for the scrappy startup programmer long after they needed to switch to hiring for the coordinated team player.
The result is a mismatch that costs them twice. They pay premium salaries to attract engineers who are genuinely excellent at a job that no longer exists inside their organization. Then they spend management cycles dealing with the friction those engineers create because they don’t fit the coordination-heavy environment.
The companies that get this right, and there aren’t many, actually run different interview processes at different company stages. They’re not testing for raw coding ability above a certain threshold. They’re testing for written communication, for the ability to explain decisions to non-technical stakeholders, for how someone handles being wrong in a group setting. These are the skills that matter at 200 employees. They’re almost irrelevant at 20.
This connects to a broader pattern in how successful tech CEOs make strategic decisions: the higher the stakes and the larger the org, the more the premium goes to judgment and communication over raw execution speed.
What “Better” Actually Means Changes With Headcount
The uncomfortable truth is that “better programmer” is not a fixed category. It’s context-dependent in a way that the industry refuses to acknowledge, partly because the mythology of the genius hacker is too good a story to give up.
At 10 employees, better means faster, smarter, more technically brilliant.
At 50 employees, better starts to include reliable, communicative, and consistent.
At 150 employees, better often means someone who makes the people around them more productive, even if their own individual output is lower than the hotshot you could have hired for the same price.
The companies that scale gracefully figure this out before they have to. The ones that don’t figure it out the hard way, usually after losing six months to a technical debt crisis or watching their best “small company” engineers burn out and quit because they hate working in a bureaucracy they helped create.
The Fix Is Simpler Than You Think
If you’re running an engineering org and you’re anywhere near that 100-employee inflection point, the single most useful thing you can do is honestly audit what you’re actually rewarding.
Are you giving raises and promotions to the engineer who shipped the most features last quarter, or to the one who made the rest of the team 20% more effective? Are you penalizing slowness in code reviews, or are you penalizing sloppiness in how decisions get communicated? Are you treating documentation as a nice-to-have or as a core engineering deliverable?
The companies that scale engineering well aren’t paying more for worse programmers in any absolute sense. They’re paying appropriately for a different and genuinely harder job, the job of writing code that survives contact with a large, distributed team of other humans.
That job is harder than writing brilliant code alone. It just doesn’t look as impressive in a demo.