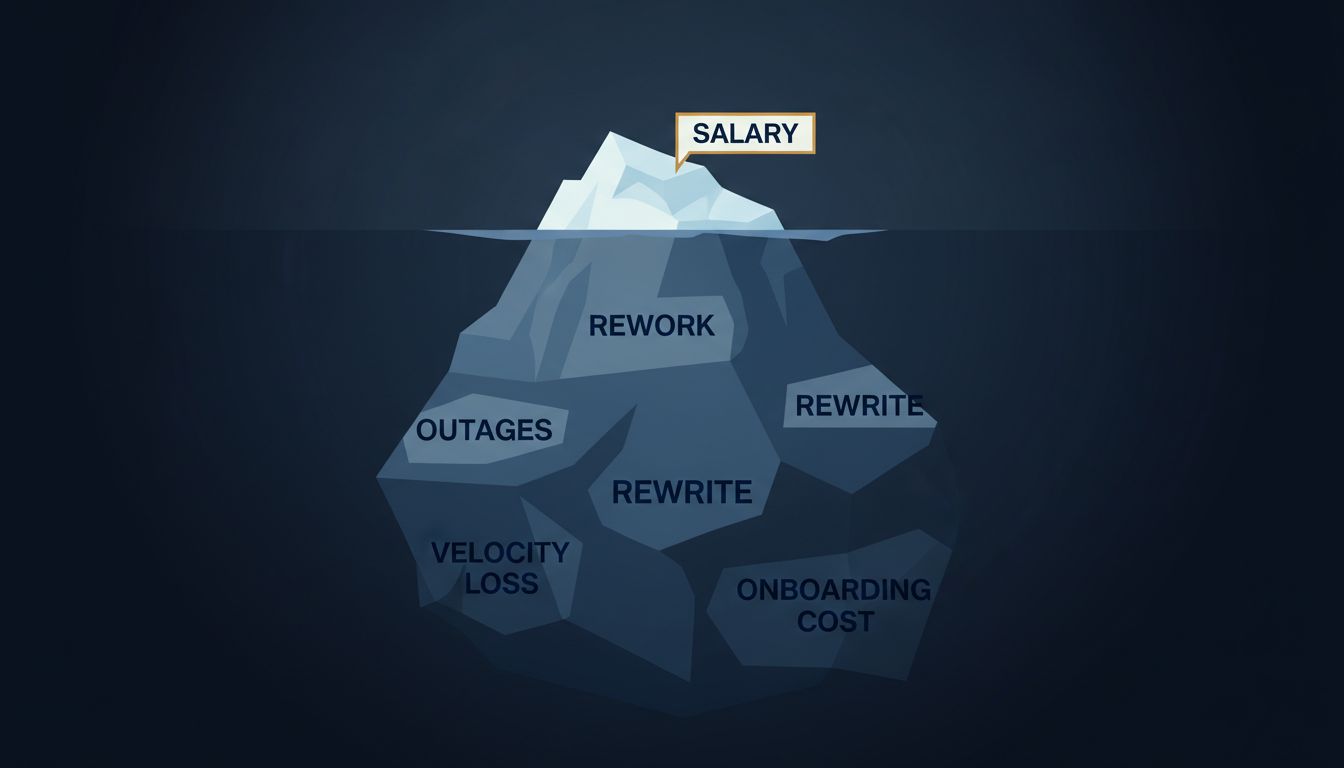
The Salary That Looks Like an Overpayment
When a Series B startup hires a senior distributed systems engineer at $450,000 in total compensation, the finance team tends to notice. That number, for a single individual contributor, typically exceeds what the company pays three mid-level engineers combined. CFOs who came up through traditional industries sometimes push back on it. Some try to negotiate it down.
This is a mistake, and the reason why reveals something important about how value actually gets created in software companies.
The engineer in question probably won’t ship the most code on the team. They may not ship much code at all. What they do instead is recognize, before anyone else does, that a proposed architecture will hit a hard ceiling at 10,000 concurrent users when the business plan assumes 500,000. They say so in a design review. The team spends two weeks redesigning the approach instead of six months building the wrong thing and then another six months unwinding it.
That intervention, a single comment in a document or a 45-minute meeting, just saved the company somewhere between $5 million and $15 million in engineering salary, infrastructure costs, and delayed revenue. The engineer’s annual salary paid for itself before Q2.
Why Software Has Negative-Cost Decisions
Most industries have costs that scale roughly with output. A factory making more cars buys more steel. A law firm billing more hours hires more associates. Software is different in a specific and underappreciated way: the cost of a decision in software compounds over time rather than staying fixed.
A poor architectural decision made in January doesn’t cost what it costs in January. It costs January, plus every month of engineering time spent working around the constraint, plus the outages that compound from the fragility, plus the customer churn those outages cause. The original decision might have taken 30 minutes to make. Reversing it, fully, can take a year.
This asymmetry is what makes prevention so economically dominant over remediation in software. And it’s what makes the senior engineer who mostly prevents things worth more, on paper, than several engineers who mostly build things.
The underlying math isn’t complicated. Software industry surveys consistently show that the cost to fix a bug or architectural flaw grows by roughly an order of magnitude at each stage of development: it’s cheapest in design, more expensive after it’s written, far more expensive after it’s deployed, and most expensive when customers have built workflows on top of it. The exact multipliers vary by source and context, but the directional finding is consistent enough that most engineering leaders accept it as a working principle.

The Work That Doesn’t Show Up in Sprint Velocity
Here’s the measurement problem. Almost every metric used to evaluate engineering output captures production, not prevention. Story points completed. Pull requests merged. Features shipped. Lines of code (a metric so misleading it’s almost satirical, but still used).
None of these capture the project that didn’t get built. The migration that didn’t become necessary. The security audit that revealed a vulnerability before it became a breach.
This creates a real organizational problem. The engineer whose primary value is judgment and prevention will look, in most metric systems, like a low performer. They may even look that way to their own manager. The engineers shipping constantly will appear more productive, even when some of what they’re shipping is creating future liability.
Knowledge-work productivity measurement has always struggled with this, as we’ve explored in other contexts. But the gap is especially wide in software because the delayed costs are so large and so invisible until they’re not.
Some companies have tried to make prevention visible. Google’s Site Reliability Engineering model attempts this by tracking reliability as an explicit metric and giving engineers ownership of it. When an SRE flags an architecture problem that would have caused a future outage, that flag has some organizational recognition. But most companies aren’t Google, and most don’t have measurement systems sophisticated enough to capture prevented outcomes.
What These Engineers Actually Do All Day
The framing of “doing almost nothing” deserves scrutiny, because it’s both accurate and misleading.
Senior engineers operating at this level aren’t passive. They read a lot: architecture proposals, postmortem documents, incident reports, academic papers on distributed systems, changelog notes from the databases and queues the company depends on. They maintain an unusually detailed mental model of how all the pieces of the system interact under stress. When something is proposed that they know will behave badly, they can say why, specifically, with reference to the mechanism that will fail.
This knowledge is extraordinarily expensive to accumulate and nearly impossible to transfer quickly. It’s also the reason the salary is what it is. You aren’t paying for the hours they sit at a keyboard. You’re paying for the decade of context they carry in their head.
The “almost nothing” quality comes from how infrequently this expertise is needed relative to how much the company pays to have it available. It’s closer to insurance than it is to labor. You pay the premium every month. You hope you don’t need it. When you do need it, you’re glad you were paying.
This framing also explains why these engineers are so hard to retain. They often feel underutilized, because the visible surface area of their work is small even when their impact is large. They rarely get credit for the thing that didn’t go wrong. Over time, this can produce a specific kind of dissatisfaction: competence that feels invisible to the organization that benefits from it.
The Misallocation Most Companies Are Making
Given this, the rational move is clear: identify the decisions with the largest potential downside, and make sure the best judgment in the company is involved in those decisions before they get made.
Most companies do the opposite. Their most senior engineers are pulled into escalation chains after something has already broken. They review code after it’s been written rather than architecture before it’s been designed. They’re in the critical path for shipping, which means they’re optimized for throughput rather than error prevention.
This is partly a cultural artifact. Engineering teams that grew up in startup environments learned to ship fast and fix problems later, because in the early stages, survival depends on speed. The habits that kept a 10-person company alive can become actively harmful at 200 people, when the system is large enough that a bad architectural decision can take two years to fully undo.
The other part is the measurement problem described above. When everything is optimized for velocity, slowing down to have the right conversation before building something is perceived as friction. Engineers who introduce that friction get labeled as difficult or overly cautious, even when they’re right.
The best-run engineering organizations have figured out how to separate these functions. They treat architecture review as a distinct activity from sprint work, with a formal path for raising concerns before significant investment gets made. The companies that haven’t built this tend to cycle through the same expensive mistakes every few years, with slightly different technical details each time.
Why Hiring Fewer of These Engineers Doesn’t Save Money
When tech companies cut costs, senior individual contributors are often among the first to go. They have high salaries, low visibility into sprint metrics, and their value is by nature hard to articulate in a budget review.
This is a reasonable-looking decision that often turns out to be very expensive. What tends to happen in the year or two after these cuts is a pattern of architectural decisions that accumulate technical debt at a faster rate, because nobody with the relevant experience was in the room when the decisions were made. The cost doesn’t appear immediately. It appears 18 months later when a re-architecture project is added to the roadmap with a price tag multiple times the savings from the original cut.
The broader point is that talent concentration in software economics doesn’t work the way it does in most industries. Studies of programming output have consistently found extraordinary variance in individual productivity, with the most skilled performers producing code with far fewer defects at far greater speed than the median. But “productivity” in the narrow sense still misses the prevention value. The true spread in individual economic contribution, when you include what gets prevented, is likely even wider than the studies suggest.
This is why the $450K engineer is usually not overpaid. The question is never whether the number is large. The question is what the counterfactual looks like.
What This Means
The economic logic of senior engineering talent comes down to one insight: in software, the cost of decisions is front-loaded in time and back-loaded in money. The further a bad decision travels before it gets caught, the more it costs to undo.
The most valuable engineers are the ones who shorten that distance, who catch the wrong decision at the proposal stage rather than the deployment stage or, worse, the customer stage. Their value isn’t captured in any standard productivity metric because their most important work is invisible: it’s the code that never got written.
Companies that understand this structure their hiring and their processes accordingly. They pay for judgment at the front end of decisions rather than labor at the back end. They treat the design review as a first-class engineering activity rather than an obstacle to shipping. And they recognize that the engineer who says “wait, this won’t work” in a meeting is often doing more valuable work than the engineer who makes sure the sprint board stays green.
The $450K number isn’t the point. The point is what the company would have spent without them.