In 2001, shortly after 9/11, the FBI decided it needed to modernize its case management system. The existing setup was so antiquated that agents were literally sharing information by walking paper files down hallways. The solution was a project called Virtual Case File, budgeted at around $170 million and scoped to take three years.
By 2005, the FBI had spent $170 million and had nothing deployable. They scrapped the whole thing. They then started a replacement project called Sentinel, which was estimated to cost $451 million and finish by 2009. It finished in 2012, cost over $600 million, and the working version was ultimately delivered by a team of 20 developers in 12 months after the original contractor had burned through years and hundreds of millions without a usable product.
This is not primarily a story about government inefficiency, even though that’s the comfortable narrative. It’s a story about a specific and almost universal failure mode in software estimation, one that plays out at startups, at enterprise companies, and at agencies everywhere.
The Setup
When Lockheed Martin won the Sentinel contract, they did what every large software contractor does: they estimated from the outside in. They looked at the desired end state, broke it into components, assigned time to each component, added a buffer, and handed over a number. The FBI accepted that number because it was specific and because specificity feels like confidence.
The number was wrong before the ink dried. Not because Lockheed Martin’s engineers were incompetent, but because the estimation methodology doesn’t account for the thing that actually consumes most of the time in complex software projects.
That thing is discovered complexity.
What Actually Happened
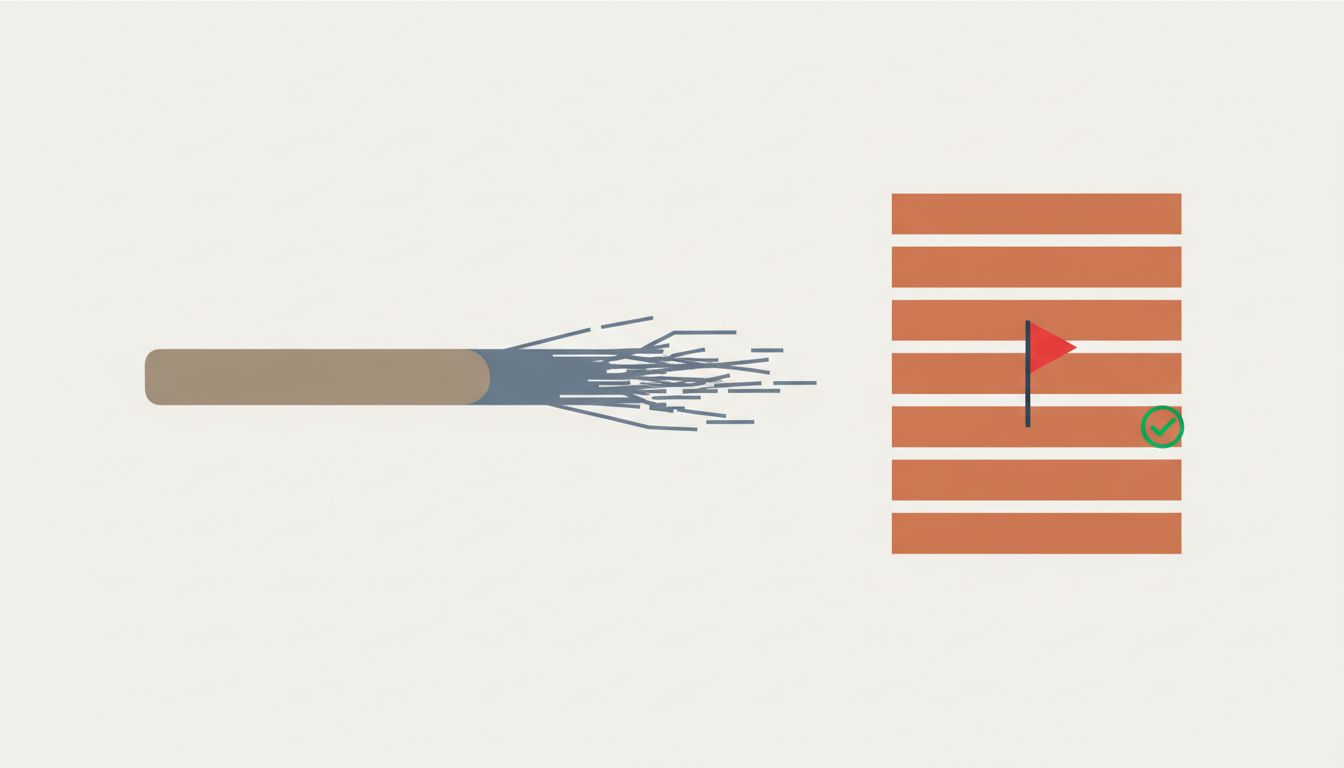
The FBI’s legacy systems weren’t just old. They were old and undocumented and interconnected in ways nobody fully understood, because the people who built the original connections had retired or left. Every time Sentinel’s developers tried to integrate with an existing system, they found something unexpected. A data format that wasn’t what the documentation said. A dependency on a system that was itself dependent on another system that was supposed to be decommissioned. Business logic baked into stored procedures that nobody remembered writing.
None of this was in the estimate. It couldn’t be, because you can’t estimate what you don’t know exists. But here’s the critical part: experienced software people knew that undocumented complexity of this kind would exist. They’ve seen it in every large legacy integration project. The problem is that this knowledge is almost never reflected in estimates, because doing so would make the estimate unacceptably large.
This is the hidden reason. Not optimism bias in the psychological sense. Not poor planning. A rational, knowing undercount that everyone in the room implicitly agrees to.
The project manager knows the estimate is low. The contractor knows the estimate is low. The client suspects the estimate is low. Everyone proceeds anyway, because the alternative is a conversation nobody wants to have: “We don’t actually know how long this will take because we don’t know what we’ll find.”
That conversation would be accurate. It would also, in most procurement environments, lose you the contract.
The 20-Developer Version
When the FBI finally brought in a small agile team to rescue Sentinel in 2010, that team did something structurally different. They didn’t estimate the whole project. They estimated the next sprint. They built incrementally, surfacing discovered complexity as they went rather than absorbing it silently into schedule slippage.
The full system was delivered in about a year. The team size was roughly 5% of what Lockheed Martin had deployed.
This is the part of the Sentinel story that doesn’t get enough attention. The rescue wasn’t faster because the developers were better (though small, focused teams do tend to outperform large coordinated ones). It was faster because the process made hidden complexity visible in real time rather than letting it accumulate invisibly inside a waterfall timeline.
When you build in sprints with working software at the end of each one, you can’t hide the fact that a particular integration took three times as long as expected. It shows up immediately. The estimate gets updated. Priorities get renegotiated. The schedule reflects reality rather than lagging six months behind it.
Why This Keeps Happening
The incentive structure around software estimation is almost perfectly designed to produce this outcome. On the contractor side, you estimate low to win the bid and recover margin through change orders once you’re locked in. On the client side, you accept the low estimate because a realistic estimate would require budget approval you can’t get. The project kicks off with a number everyone knows is fiction, and then the fiction gets maintained until it becomes undeniable.
Government projects are the clearest example because the numbers are public, but the same dynamic plays out in private companies constantly. A startup says its v2 will take six months. Twelve months later, v2 ships, and the postmortem blames scope creep or headcount issues rather than the estimation methodology that was broken from day one.
The phrase “scope creep” deserves particular skepticism here. In many cases, what gets called scope creep is actually discovered complexity that was always going to be there. The scope didn’t creep. The estimate failed to account for what was already present but invisible.
There’s a reason the projects that tend to ship on something approaching their original timeline are the ones with the smallest, most contained scope. Not because small projects are easier to manage, but because small projects have less surface area for discovered complexity to hide. A single-purpose tool with no legacy integrations and no entrenched stakeholder requirements is almost the only environment where upfront estimation is reliable.
What We Can Learn
The Sentinel case study points toward a few conclusions that are harder to argue with after you’ve seen the numbers.
First, detailed upfront estimates for large software projects are mostly a ritual that creates the feeling of control without the substance of it. The estimate is wrong, everyone knows it’s probably wrong, and the project proceeds anyway. This doesn’t mean you shouldn’t plan. It means treating the initial estimate as a planning artifact rather than a commitment.
Second, the only reliable way to surface discovered complexity is to build incrementally with real working software at each step. Not prototype software. Not demos. Working software that integrates with actual systems and hits actual data. The complexity you find in sprint three is complexity you would have found eventually regardless. Finding it in sprint three instead of month fourteen changes what you can do about it.
Third, the political problem is real and shouldn’t be dismissed. A team that tells leadership “we’ll know more after the first three months of building” will often lose to a team that presents a confident 18-month roadmap. Fixing estimation culture requires clients and managers to genuinely reward honest uncertainty, which is a much harder problem than fixing the estimation methodology itself.
The FBI spent over half a billion dollars learning something that smaller companies learn all the time and then promptly forget when the next project kicks off and someone needs to put a number on a slide. The number will be wrong. The question is whether you’ve built a process that finds out quickly enough to do something about it.