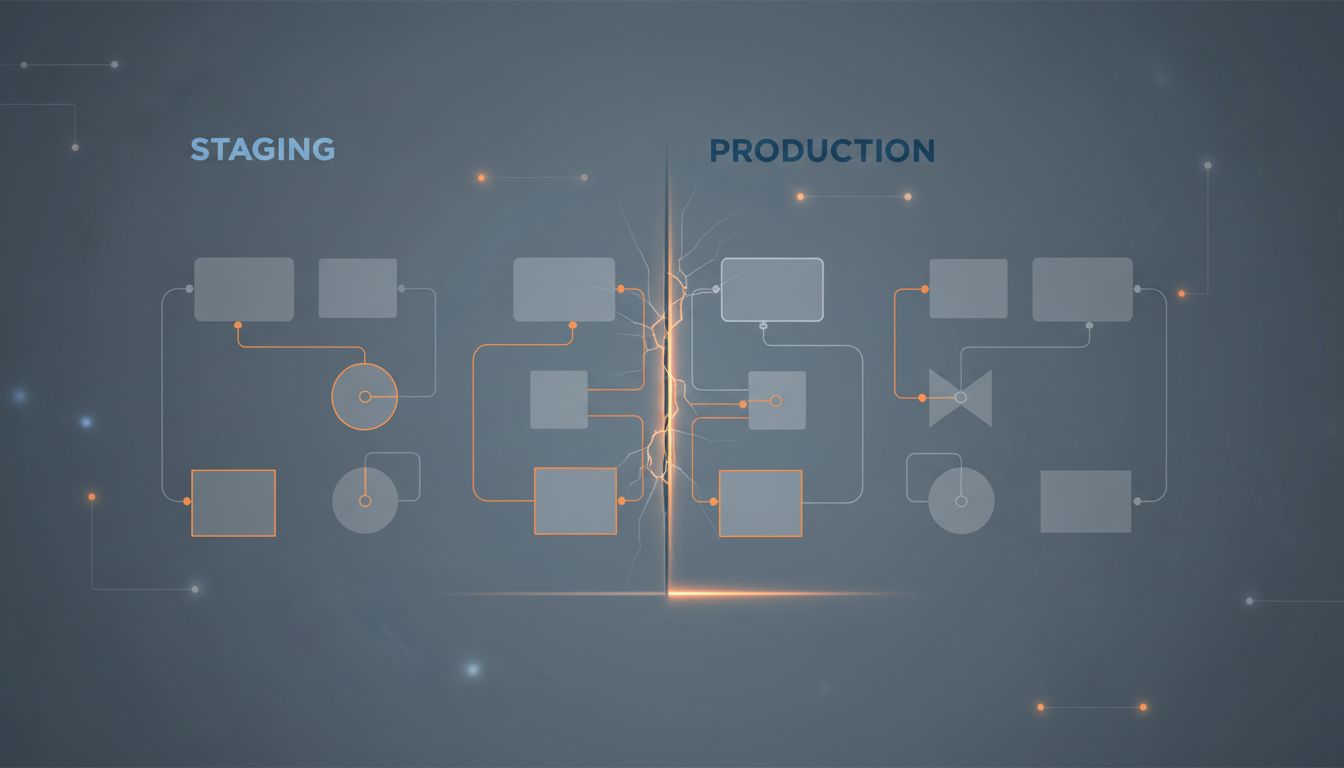
Every engineering organization above a certain size maintains a staging environment. The idea is logical: before you deploy code that real users will touch, you test it somewhere that looks like production but isn’t. Staging catches bugs. Staging prevents outages. Staging is the responsible thing to do.
Staging is also, in most cases, a polite fiction.
Not useless. Not something you should tear down tomorrow. But an environment that gradually drifts from production in ways that are quiet, cumulative, and largely invisible until they matter most. Here is why.
1. Staging Traffic Is Not Production Traffic
Production traffic has texture. It has users who click through forms faster than your tests anticipate, who leave tabs open for three days, who submit the same request twice because the spinner didn’t convince them. It has traffic spikes from an email campaign nobody told infrastructure about, and long-tail query patterns that only emerge at scale.
Staging has synthetic load, if it has load at all. The happy-path integration tests. The smoke tests. Maybe a replay of yesterday’s production traffic if your team is unusually disciplined. What staging cannot have is the stochastic weirdness of actual users behaving in ways that defy documentation.
This matters most at the boundaries. Rate limiters behave differently when the cache is warm and globally consistent versus when it’s been running for ten minutes on a freshly provisioned environment. Database query planners make different decisions when they have real query statistics versus the thin sample you get in staging. The bugs that staging was designed to catch are precisely the bugs that depend on conditions staging cannot replicate.
2. The Data Problem Is Structural
Staging needs data to test against. You cannot use real production data, or at least you shouldn’t, because production data contains actual customer information and the legal exposure that comes with it. So you use anonymized data, generated data, or a snapshot that is weeks or months old.
Each of these choices introduces divergence. Anonymized data has different cardinality. Generated data has none of the referential irregularities that accumulate in real databases over years of schema migrations, backups, and edge-case writes. Old snapshots miss newly created indexes, new table structures, and the long tail of data that was written after the last dump was taken.
The result is that your staging database is a simplification of your production database. Which means any test that exercises the database is, to some degree, testing a different system.
3. Config Drift Is Silent and Relentless
Environment variables, feature flags, third-party credentials, infrastructure configs: all of these have a production version and a staging version, and the two versions start drifting the moment you create them. The person who updated the production Stripe webhook key after a rotation may not have updated staging. The team that tuned a database connection pool in production last quarter wrote it down in a Notion doc but didn’t backfill it. The new S3 bucket policy that blocks public access exists in production and not in staging, so the bug you’re looking for never appears.
This is not a failure of process, or not only that. It is an emergent property of maintaining two environments that are supposed to be identical but are changed by different people at different times for different reasons. Divergence is the default state. Synchronization requires active work.
4. The Timeline Is Backwards
Here is the uncomfortable arithmetic. The bugs that staging actually catches tend to be obvious integration failures: a new service can’t reach its dependency, a contract between two APIs was broken, a migration left a table in an unexpected state. These are real bugs and catching them is genuinely valuable.
But the bugs that cause production incidents are usually subtler. A race condition that only appears under concurrent load. A memory leak that takes twelve hours to manifest. A timeout misconfiguration that only triggers when the downstream service is slow in a specific way that staging’s stub doesn’t replicate. These bugs pass through staging not because your staging is bad, but because staging is structurally incapable of finding them.
The implication is that staging creates a kind of confidence that is partially misplaced. Code that passes staging has passed a real but limited set of checks. The organization that has internalized this ships faster and invests more heavily in production observability. The organization that hasn’t treats staging success as a near-guarantee of deployment safety, which is how surprises happen.
5. The Alternative Is Not No Testing
None of this is an argument for shipping untested code. It is an argument for being honest about what testing environments can and cannot do, and investing accordingly.
The teams that handle this best tend to share a few practices. They use feature flags to deploy code to production before activating it, which means they test in production traffic while controlling blast radius. They invest heavily in observability, because if staging can’t catch everything, you need to detect and respond to production issues quickly. They run chaos engineering and synthetic monitoring in production, not just in staging. They treat staging as what it actually is: a sanity check that catches gross integration failures, not a certification that code is production-ready.
The philosophical shift is from “staging proves the code works” to “staging proves the code isn’t obviously broken.” That’s a real distinction. Code that isn’t obviously broken still needs careful deployment, good monitoring, and the organizational willingness to roll back fast when production tells you something staging couldn’t.
6. The Organizational Cost Is Real Too
Maintaining a staging environment is not free. It requires compute, storage, operational attention, and the ongoing work of keeping it close enough to production to be useful. Teams debug staging-specific failures that have no bearing on anything in production. On-call rotations get paged about staging when someone forgets that staging pages are routed to the same channel. Junior engineers spend time chasing problems that exist only because staging data is old or config is stale.
The organizations that have wrestled with this most seriously, large continuous-deployment shops that push code to production dozens of times per day, have often simplified or eliminated traditional staging entirely. They rely on automated tests, canary deployments, and production observability. That combination is harder to build and requires genuine organizational maturity. But it’s also more honest about where software actually breaks.
Staging feels like safety. In many cases, it is the feeling of safety, which is a different thing. Knowing the difference is most of the work.