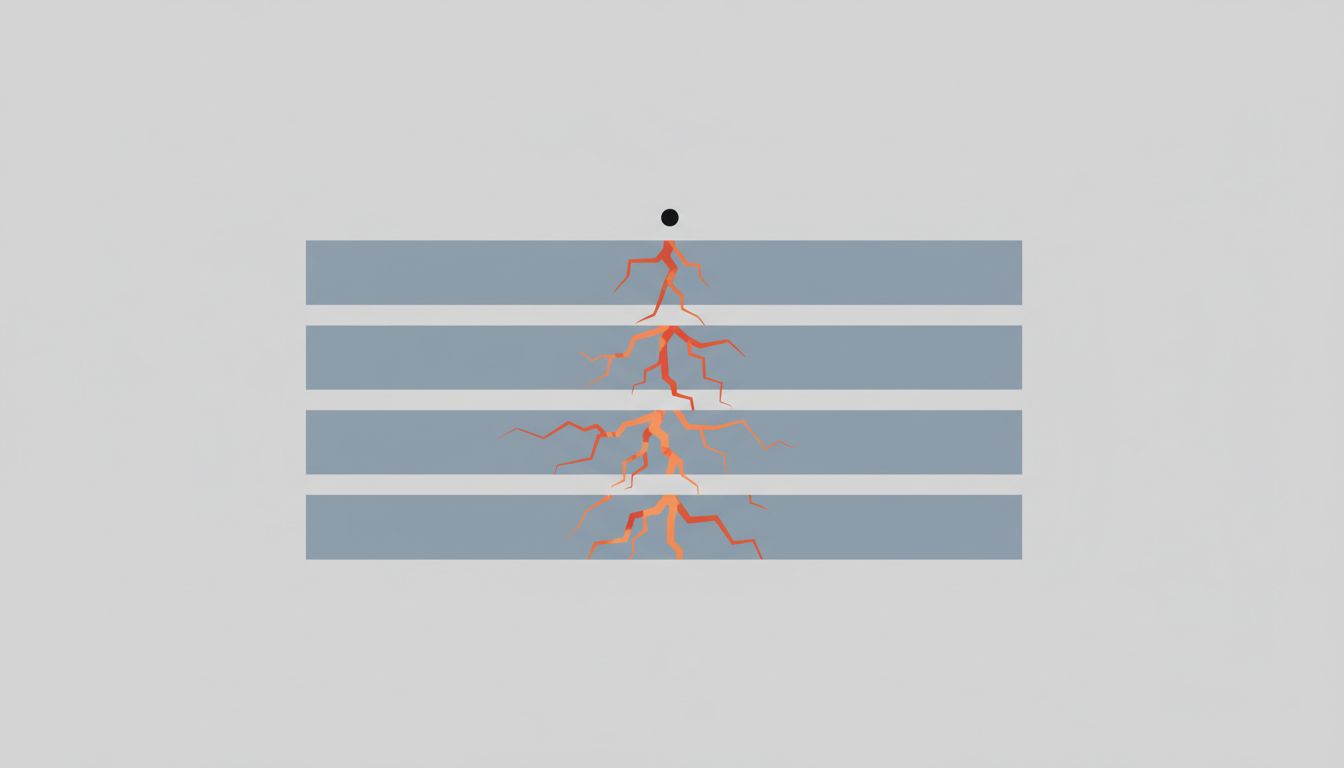
The simple version: Software systems fail not from dramatic architectural flaws but from small, overlooked edge cases in data, and the damage spreads far before anyone notices.
Why Small Inputs Cause Large Failures
Most catastrophic software failures share a structural pattern: a system built for the expected case encounters something slightly outside that expectation, and the handling of that mismatch cascades. The input itself is usually tiny. The assumption it breaks is usually old and load-bearing.
Null bytes, timezone ambiguity, and leap seconds all belong to this category. They are not obscure theoretical problems. They have each caused real production outages, data corruption, and financial loss at large organizations. Understanding why requires looking at how software actually processes data, not how engineers assume it does.
Null Bytes and the Assumption of Clean Strings
A null byte is the character with the value zero. In C and C-derived languages, it marks the end of a string. In almost everything built on top of those languages, including databases, web servers, and file systems, that convention persists even when the surrounding code has long since moved to higher-level languages.
The problem emerges when software that expects clean text encounters a null byte in the middle of a string. Some systems truncate the string at that point, silently dropping everything after it. Others crash. A third category, which is the most dangerous, treat the null byte as a valid character in one layer of the stack and as a terminator in another.
This inconsistency has been weaponized for decades. Security researchers have used null byte injection to bypass file extension checks: a web application might validate that an uploaded file ends in .jpg, but the underlying file system call sees the null byte mid-filename and writes a different file entirely. The validation passed. The file system did something else. The gap between those two behaviors is where the exploit lives.
In data pipelines, null bytes cause quieter damage. A field that should contain a product name arrives with an embedded null. The pipeline writes it to a database column that technically accepts the byte. Downstream, a reporting tool pulls the data and chokes on it. The error appears three steps removed from the source, which is exactly why it takes days to trace.
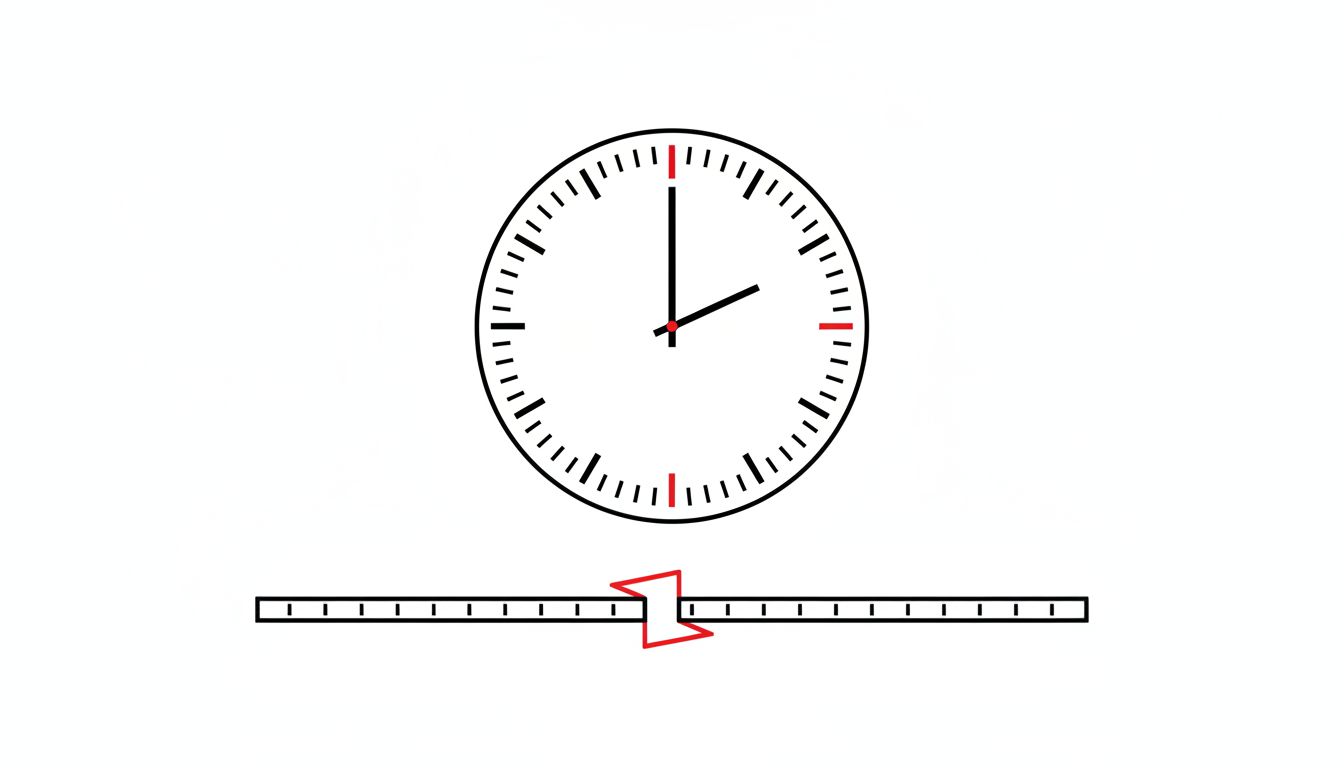
Timezones and the Illusion of Unambiguous Time
Timezone bugs are the most underestimated category here, partly because they feel like a solved problem. They are not.
The core issue is that a timestamp like “2023-11-05 01:30:00” does not unambiguously describe a moment in time. In the United States, that time occurred twice on that specific date because clocks were set back one hour at 2:00 AM for daylight saving time. Any system that stores or sorts on local time without an explicit offset will process two different events as simultaneous, or assign one of them the wrong order.
This matters most in financial systems and logging infrastructure, where sequence is everything. A trading platform that misorders two transactions by one hour might still balance its books but generate a compliance record that does not reflect reality. An incident response system that logs events in local time might make an alert appear to precede the condition that triggered it.
The real-world consequences have been well-documented. In 2012, a popular scheduling library’s daylight saving handling caused a production system at a major airline to double-book flights for a window of time. The fix was straightforward once identified, but the identification took longer than the repair.
The correct approach, storing all timestamps in UTC and converting to local time only at the display layer, is widely taught and inconsistently practiced. The reason it keeps being violated is that developers working on a feature locally see their timestamps in local time, everything looks correct, and the bug only surfaces when users in different timezones interact with the same data.
Leap Seconds and the Clocks That Disagreed
Leap seconds are adjustments made to Coordinated Universal Time to account for the Earth’s slightly irregular rotation. Since 1972, 27 leap seconds have been added. Each one inserts an extra second into the day, producing a minute that runs from :00 to :60 instead of :00 to :59.
Most consumer software never encounters this. Most infrastructure software should handle it correctly and does not.
The most documented leap second event in tech history occurred on June 30, 2012. When the leap second was inserted, Linux kernels running the HRTIMER_SOFTIRQ function entered a high-CPU spin loop. Systems running Java applications saw the Java Virtual Machine freeze or consume 100% CPU because of how Java internally reconciles time. Reddit, Mozilla, LinkedIn, and Qantas were among the affected organizations. The problem was not that the leap second occurred. The problem was that these systems had never been tested against a 61-second minute, and the assumption of 60-second minutes was baked in at multiple levels.
This is a useful illustration of the broader pattern. The bug you can’t reproduce is usually the most important one, and leap seconds are nearly impossible to reproduce in a standard test environment because the conditions require an actual leap second event, which happens roughly once every year or two and cannot be easily simulated.
The International Earth Rotation and Reference Systems Service announced in 2022 that leap seconds will be discontinued after 2035, which removes the problem for future systems but does nothing for the installed base of software that will run past that date with the old assumption intact.
The Common Thread
Null bytes, timezone ambiguity, and leap seconds all fail the same way: they are exceptions to an assumption that was never written down. The assumption was embedded in code as a natural byproduct of how the developer thought about the problem. The exception exists in the real world but not in the test suite.
The reason these bugs are disproportionately damaging compared to their apparent size is not complexity but trust. A null byte in a string field does not look like a failure. A timestamp that is technically valid but contextually wrong does not look like a failure. The system accepts the input, processes it, and produces output. The failure is in what that output means, which is only apparent later, in a different system, to a person who has to work backwards to find the source.
This is the same reason that replication lag causes data loss in distributed systems: the failure is temporally and spatially separated from its cause, which makes attribution hard and response slow.
The practical defense is not heroic engineering. It is discipline in the boring parts: validate inputs at system boundaries, store time in UTC with explicit offsets, test edge cases in time handling explicitly, and treat any data field that crosses a system boundary as potentially hostile. Most of these failures were anticipated by someone who wrote a warning in a library’s documentation that nobody read. The documentation was correct. The production outage proved it.