The simple version
When a system generates too many alerts, people start ignoring all of them, including the ones that matter. This was true for radar operators in 1970 and it is true for your Slack workspace today.
The study you have probably never heard of
In the early 1970s, researchers studying air traffic control systems noticed something alarming. Controllers were missing critical alerts. Not because the alerts were unclear or poorly designed, but because there were too many of them. The radar systems of that era would flag anything that deviated from expected patterns, which meant controllers were routinely processing dozens of warnings per hour, the vast majority of which turned out to be non-events.
What emerged from this work was a concept that human factors researchers would later formalize as “alert fatigue.” The mechanism is straightforward: when a person receives a high volume of alerts that consistently turn out to be false positives or low-priority noise, the brain recalibrates. It stops treating the alert signal as meaningful. The perceptual threshold for what counts as “worth responding to” quietly rises, and eventually, real warnings get filtered out along with the junk.
This is not a willpower problem. It is how attention works. The brain is a prediction machine that learns to suppress inputs it has learned to associate with wasted effort.
The same failure mode, replicated everywhere
The alert fatigue pattern was studied extensively in medical contexts through the 1990s and 2000s, particularly in hospital ICUs where patient monitoring systems would trigger alarms at extraordinary rates. Research in clinical settings found that somewhere between 72% and 99% of alarms in intensive care units were false positives or clinically insignificant, depending on the unit and the study. Staff adapted by learning to mostly ignore them. This contributed to documented cases of real emergencies being missed.
The pattern generalizes because the underlying mechanism is universal. Your brain does not care whether the false positives are coming from a cardiac monitor or a project management tool. Volume plus low signal quality equals learned suppression.
Now map that onto a typical knowledge worker’s environment. A Slack workspace with twenty channels. GitHub notifications for repositories you only loosely contribute to. Email threads where you are cc’d as a courtesy. Calendar reminders set optimistically months ago. A monitoring dashboard where half the alerts have been in a “warning” state so long that nobody remembers why. Each of these systems was probably justified when it was set up. Together, they create exactly the conditions that broke air traffic controllers.
The cognitive cost that happens before you even look
Here is the part that trips people up. The cost of a notification is not just the time it takes to read and dismiss it. There is a pre-attentive cost that occurs the moment the alert registers in your peripheral awareness, before you have consciously decided to engage with it.
Researchers studying interruption and task-switching have found that even an alert you choose to ignore generates a small attentional response. Your visual system detects it, your working memory briefly encodes it, and your cognitive load ticks up slightly. Multiply that by a hundred interruptions across a workday and you are carrying meaningful overhead that never shows up on any productivity metric.
The secondary effect is worse. Once you have habituated to ignoring alerts, you lose the benefit of the ones that genuinely matter. You have optimized yourself for the average case (noise) at the expense of the edge case (the thing you actually needed to know). This is exactly the failure mode the air traffic controllers experienced, and it is exactly as dangerous in proportion to what is at stake in your work.
If you want to understand what happens in those first milliseconds before you consciously process an alert, the cognitive sequence is worth understanding in detail.
What the air traffic control fix looked like
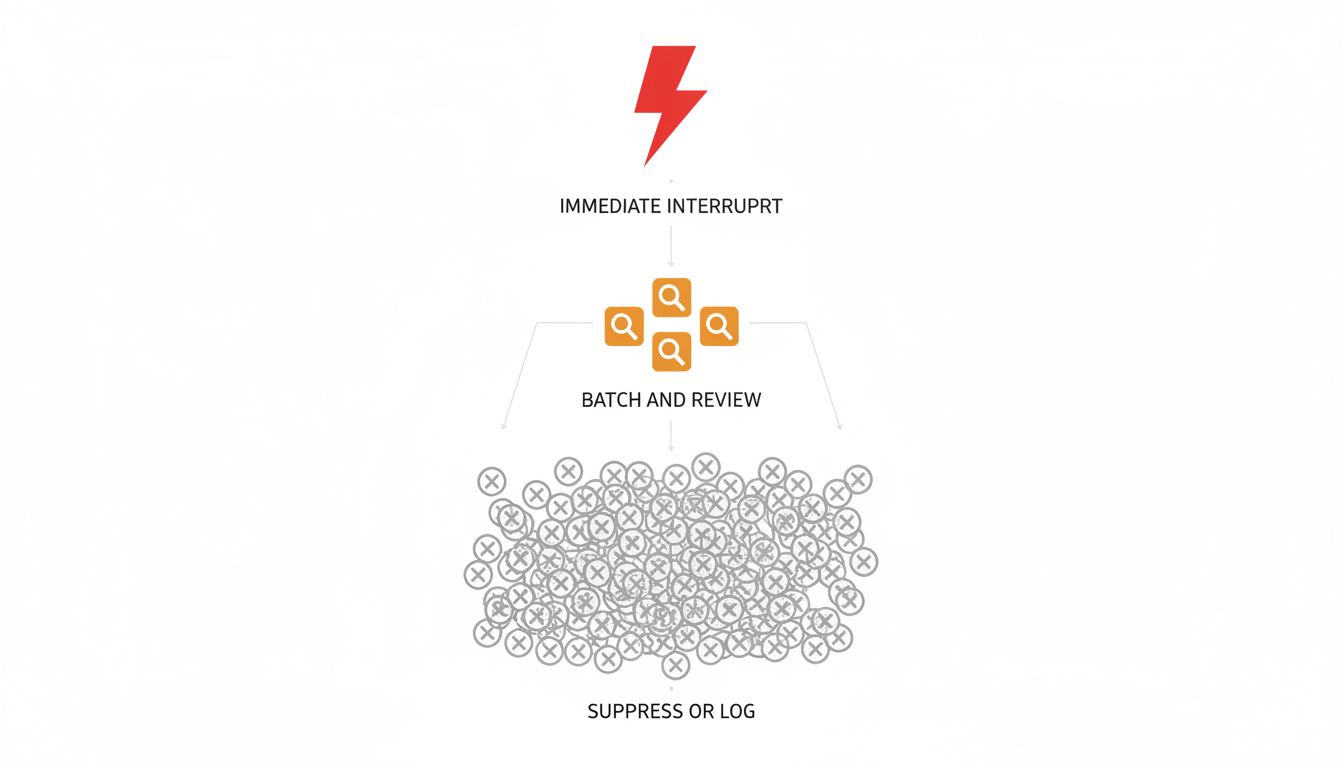
The solution in ATC systems was not to make alerts louder or more insistent. That was tried and it made things worse. The fix was ruthless prioritization at the system level. Alerts were tiered by consequence severity, and only the highest tier triggered an immediate interruption. Lower tiers were batched, summarized, or suppressed unless conditions escalated.
The principle is simple enough to state: an alert system that cries wolf regularly is worse than no alert system at all, because it actively degrades the human’s ability to respond to real events.
Applied to your notification setup, this suggests a few concrete things worth doing.
First, audit by source rather than by individual notification. If a particular channel, tool, or person generates ten alerts per week and you act on fewer than two of them, the channel is misconfigured, not the notification. Fix it at the source.
Second, recognize that “just check it later” is not a solution. Batching is only effective if you actually batch. A notification that interrupts you once now is better than one that sits in your peripheral vision for an hour generating low-level cognitive noise.
Third, treat your alert threshold as a system property you maintain, not a personal habit you cultivate. The air traffic controllers who did best were operating systems that had been deliberately calibrated. The ones who struggled were operating systems that had been allowed to accumulate alerts over time without anyone revisiting the original configuration assumptions.
The thing most advice gets wrong
Most productivity writing about notifications treats this as a discipline problem. Turn off notifications, it says. Be intentional. This misses the structural point.
The air traffic control research is useful precisely because it removes individual willpower from the equation. The controllers who failed were not undisciplined. They were operating in an environment that was structurally guaranteed to produce failure. No amount of personal attentiveness compensates for a system that is generating false positives at a high rate.
Your notification environment is a system. It has configuration decisions baked into it, many of them made by other people or by your past self under different assumptions. The question worth asking is not “how do I get better at handling my notifications” but “what would a well-designed alert system for my actual job look like, and how far is my current setup from that.”
The answer is probably: further than you think, and fixable at the system level rather than the personal discipline level.