Your CPU Completes Roughly a Billion Operations Before a Single Byte Reaches Your Network Card
The microsecond is a deceptive unit of time. It feels negligible, something that happens below the threshold of human experience, but a modern processor running at 3 GHz completes around 3,000 clock cycles in a single microsecond. In the span between your mouse button releasing and your email beginning its journey across the internet, a staggering amount of coordinated work happens inside your machine. Understanding that work changes how you think about software performance, operating system design, and the quiet genius of abstractions that most developers take entirely for granted.
The Interrupt That Starts Everything
Nothing in computing happens without a trigger, and for the send button click, that trigger is a hardware interrupt. When your finger releases the mouse button, the USB controller or trackpad firmware detects the state change and sends an interrupt signal to the CPU. The processor stops whatever it was doing, saves its current register state to the stack (a process called context saving), and jumps to the interrupt service routine registered for that device.
This interrupt mechanism is older than most programming paradigms in active use. The alternative, polling, where the CPU repeatedly checks whether input has arrived, wastes cycles and was largely abandoned for user input decades ago. Interrupts let the CPU do real work until something actually needs attention. The elegance is that the hardware and operating system agree in advance about where the interrupt handler lives in memory. When the signal fires, there is no search, no negotiation. The CPU just goes.
The interrupt service routine does as little as possible. It acknowledges the interrupt, queues a software event, and returns control. The heavy lifting gets deferred.
The Kernel Takes Over
The queued event surfaces to the operating system’s input handling subsystem, which determines what the click means in context. At this layer, the kernel is translating raw hardware coordinates into something meaningful: a click event with position, button state, and timestamp, dispatched to whichever process owns the window under the cursor.
This is where privilege levels become relevant. Modern CPUs implement hardware-enforced rings of privilege, and the kernel runs in ring 0 while your browser or email client runs in ring 3. Crossing that boundary requires a system call, a formal handoff where the application requests kernel services, the CPU mode switches, and control temporarily leaves user space. Each crossing is not free. On x86 processors, a system call involves saving registers, switching stacks, and validating the request. Multiply that by thousands of events per second in a busy application and the overhead accumulates.
The click event, once dispatched through the kernel’s input layer, arrives at your application via whatever windowing system is in play. On Linux this typically means X11 or Wayland. On macOS it goes through Quartz and AppKit. On Windows it travels through the Win32 message queue. Each of these systems has its own buffering and dispatching logic, which is why input latency varies across platforms even on identical hardware.
The Application Responds
Your email client’s event loop picks up the click. Most GUI applications are built around an event loop, a tight cycle that dequeues events and dispatches them to registered handlers. The click hits the send button’s handler, which calls into whatever application logic governs sending.
At this point the CPU is running user-space code. It validates the message, perhaps runs some light sanitization, constructs a data structure representing the outgoing email, and calls into the networking library. For a modern email client using SMTP over TLS, this might mean calling into OpenSSL or a similar library to encrypt the message content. That encryption step is computationally meaningful. AES-NI instructions on modern Intel and AMD processors accelerate symmetric encryption in hardware, which is part of why TLS overhead is far smaller than it was in 2005 when the feature didn’t exist. Even so, key scheduling and initialization involve real work.
The message, now encrypted and formatted according to the protocol, gets written to a socket. Writing to a socket is itself a system call. The application hands bytes to the kernel and trusts it to handle transmission.
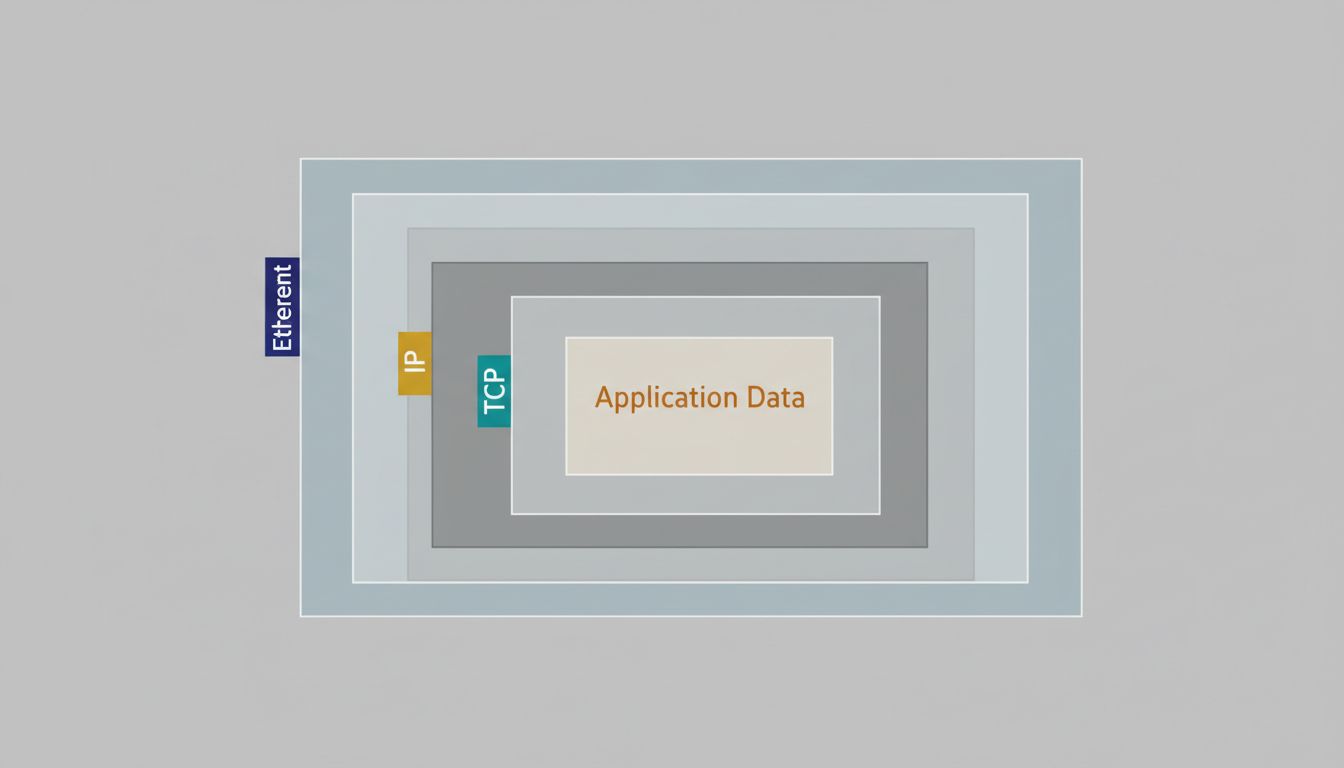
The Network Stack Builds the Packet
The kernel’s TCP/IP stack takes the application data and begins building the actual packet that will leave the machine. This is where the layered abstraction of networking becomes viscerally real.
The TCP layer wraps the data in a segment with source and destination ports, a sequence number (critical for reassembly and reliability), a checksum, and flags. TCP is connection-oriented, so this send is happening within an established connection that was set up earlier with a three-way handshake. The sequence number tracks where this data sits in the overall stream, allowing the receiving end to request retransmission if something is lost.
The IP layer adds another header. Source IP, destination IP, time-to-live, protocol identifier. If the destination is on a different network (it almost certainly is), the kernel consults its routing table to determine the next hop. That lookup is typically a longest-prefix match in a trie-like data structure, and on a laptop with a few routes it completes in nanoseconds.
The Ethernet layer adds the final header for the local network segment: source MAC address, destination MAC address (or the router’s MAC, looked up via ARP), and an Ethernet type field. A frame check sequence gets appended at the end for error detection.
All of this header construction is memory copy operations, checksum calculations, and pointer arithmetic. The kernel is building a contiguous buffer that maps directly to what the hardware will transmit.
The Driver and the NIC
The fully constructed packet reaches the network driver, which is a kernel module that speaks the hardware’s language. The driver writes descriptor information to a ring buffer in memory shared with the network interface card. This ring buffer is the handoff point between software and hardware. The driver writes a descriptor pointing to the packet data, updates a register on the NIC to indicate new work is available, and the NIC’s onboard DMA controller reads the packet directly from system memory without further CPU involvement.
DMA (direct memory access) is the architectural feature that makes modern networking fast. The CPU does not need to copy bytes to the NIC one at a time. It just tells the card where the data lives, and the card fetches it over the PCIe bus independently. This is the same principle that makes GPU rendering fast, and it reflects a broader truth in hardware design: the CPU is most valuable when it can delegate I/O to purpose-built controllers and stay focused on computation.
The NIC converts the digital frame into a physical signal appropriate for the medium. For gigabit Ethernet, that means PAM-based signaling over twisted-pair copper. For Wi-Fi, it involves modulation, channel selection, and the CSMA/CA collision-avoidance protocol that coordinates shared wireless spectrum. The radio itself is yet another processor, running firmware, handling retransmission at the wireless layer, and managing power states independently of your operating system.
What the Abstraction Costs and Why It’s Worth It
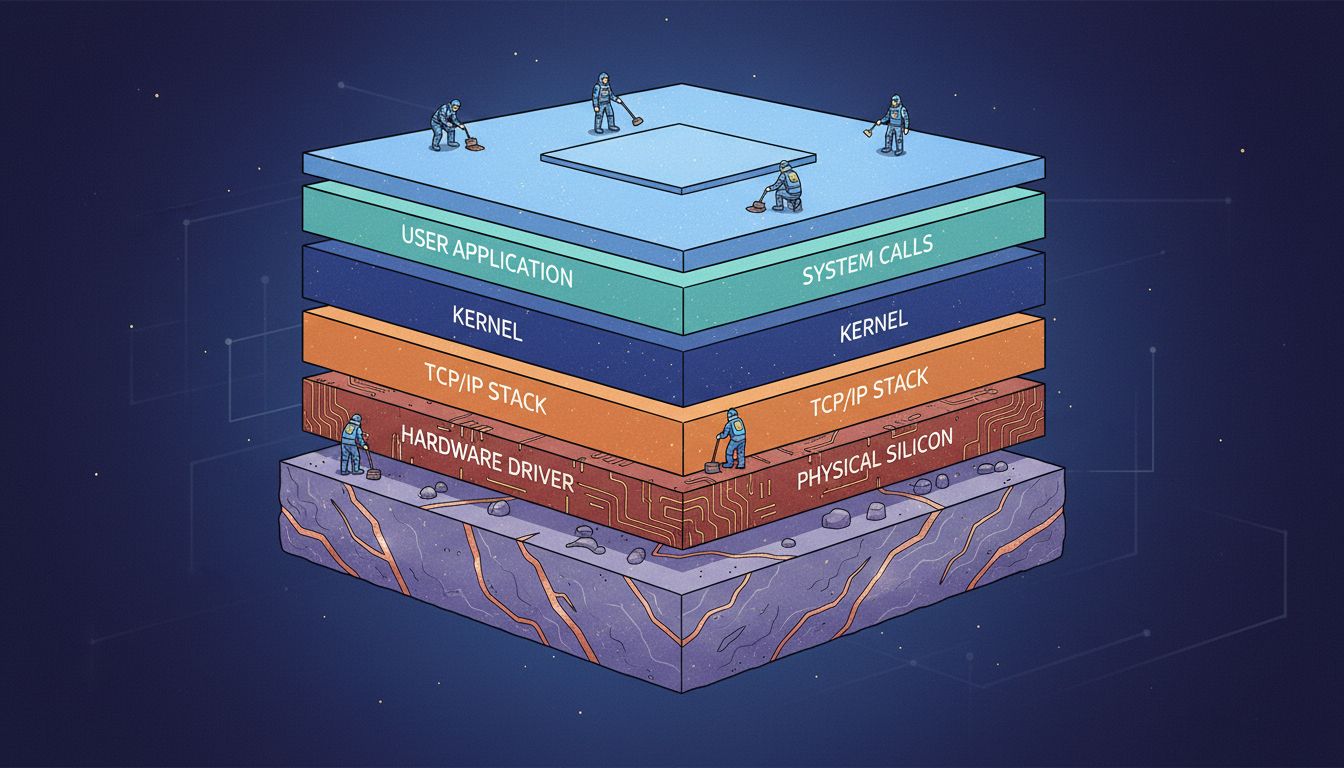
The full path from click to transmitted frame touches the keyboard controller, USB stack, interrupt subsystem, windowing system, event loop, application logic, cryptographic library, TCP layer, IP layer, Ethernet layer, network driver, DMA controller, and physical transceiver. At minimum, it crosses the user/kernel boundary several times. It touches memory that has been managed by an allocator, possibly triggering cache misses that cost hundreds of cycles each.
And yet, from a human perspective, it is instant.
The reason this works is that every layer in the stack was designed with one goal in mind: minimize how much the layer above it needs to know. Your application doesn’t need to know what kind of NIC is installed. The NIC driver doesn’t need to know whether you’re sending email or transferring a file. TCP doesn’t need to know whether the underlying network is Ethernet or Wi-Fi. This decoupling, enforced by careful interface design over decades, is what makes it possible for a programmer to call socket.send() and have it work on effectively any machine ever made.
The cost of that abstraction is overhead. The benefit is that the overhead is paid once, by the people who build the layers, and the programmers on top get to think about their actual problem. This is the foundational bargain of systems software, and it has proven to be one of the best trades in the history of engineering.
The engineers who built Linux’s TCP/IP stack, BSD’s networking code, and the POSIX socket interface were not optimizing for any single application. They were building infrastructure that would carry traffic for applications that hadn’t been imagined yet. That kind of design, building toward unknown future load rather than known present demand, is rarer than it looks and more valuable than it sounds.
What This Means
For most developers, the layers below the socket API are invisible by design. That invisibility is appropriate, most of the time. But when performance matters, knowing where the costs live changes what you optimize. Context switches are expensive, so minimizing unnecessary system calls matters. Memory copies are expensive, so zero-copy networking interfaces like Linux’s sendfile() exist precisely to eliminate them. Cache pressure is real, so large packets and coalesced writes outperform small ones in high-throughput scenarios.
The machinery inside a modern computer is not brute-force fast. It is precisely engineered to make the common case fast and the rare case merely slow. Every time you click Send and it feels instant, you are experiencing the accumulated design decisions of several generations of hardware and software engineers, most of whom you will never know by name.