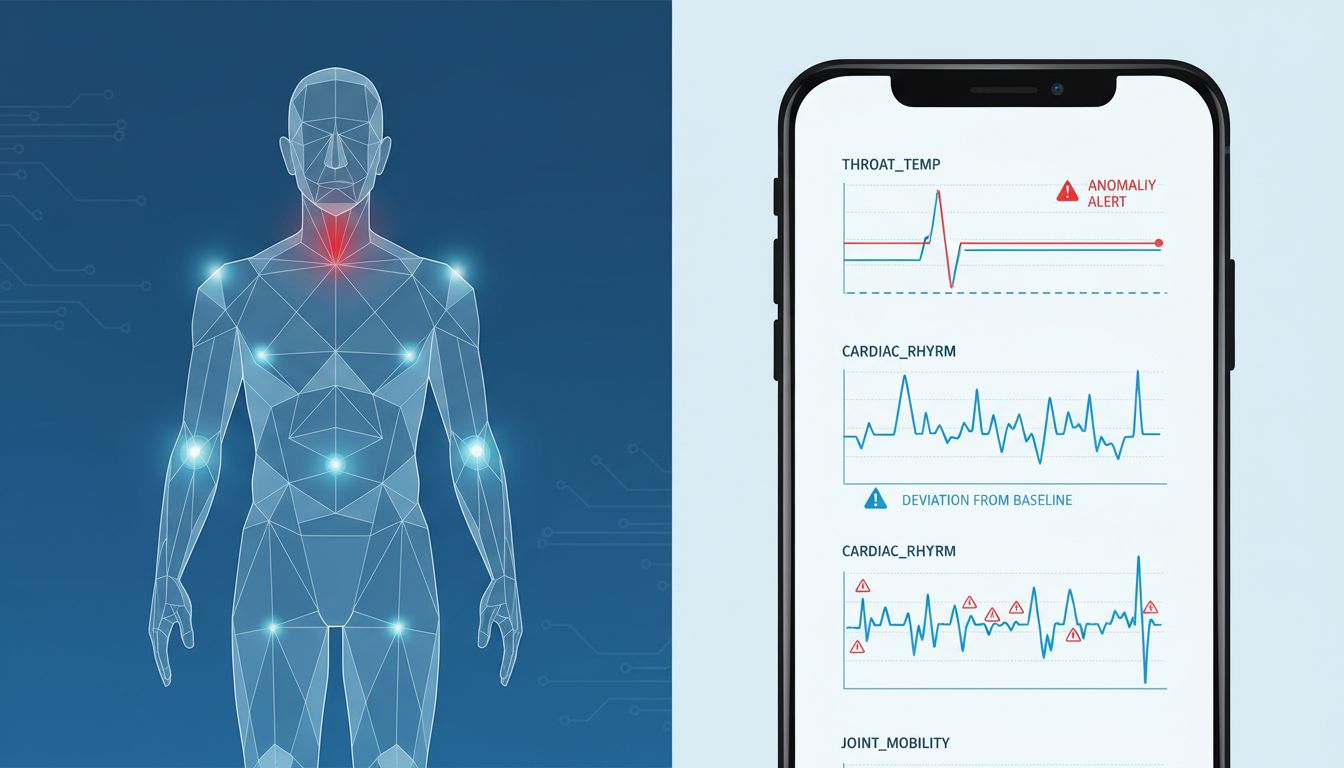
Your phone noticed something this morning before you did. Your typing speed dropped two percent. You unlocked the screen four fewer times than your seven-day average. Your voice, captured during a hands-free call, carried a subtle increase in nasal resonance. Individually, these signals mean nothing. Together, they form a clinical picture that increasingly sophisticated health algorithms are learning to read with unsettling accuracy.
This is not science fiction, and it is not a distant feature on some product roadmap. Passive health monitoring, built on the sensor arrays already embedded in the devices most people carry everywhere, is quietly becoming one of the most consequential applications of machine learning in consumer technology. The implications for medicine are profound. The implications for data privacy are more complicated. And the business logic behind it all is, as with most things in tech, more layered than it first appears.
The Sensor Farm in Your Pocket
A modern flagship smartphone contains between 14 and 18 distinct sensors. Most people know about the GPS, the camera, and the accelerometer. Fewer think about the barometer, the ambient light sensor, the proximity sensor, or the microphone array that stays partially active even when you are not on a call. Each of these instruments generates a continuous stream of data. Health researchers have spent the last decade learning to extract meaning from that stream.
Stanford’s Biodesign program and researchers at the University of Michigan have published studies showing that changes in gait (detectable via accelerometer and gyroscope) can precede flu-like symptoms by 24 to 48 hours. The reasoning is straightforward: inflammatory cytokines, the molecular signals your immune system releases when mounting a defense, affect muscle coordination and energy levels before they produce fever or congestion. Your body knows something is wrong. Your phone, if it is paying attention, can see the physical consequences of that knowledge before your conscious mind catches up.
Sleep tracking adds another dimension. A phone placed on a nightstand or a wearable synced to a health app can monitor respiratory rate, restlessness, and heart rate variability. All three metrics shift measurably in the 12 to 36 hours before symptom onset in common upper respiratory infections. Fitbit (now Google) published internal research showing that its devices could detect influenza with roughly 73 percent accuracy before users reported feeling unwell, using only passive sensor data.
The Machine Learning Layer
Raw sensor data is noise. What transforms it into signal is the machine learning infrastructure running against your personal baseline. This is the key insight that separates modern health monitoring from the blunt instruments of the past. A single elevated heart rate reading is meaningless. A heart rate that is elevated relative to your personal seven-day average, combined with reduced step count, altered typing cadence, and a two-degree shift in skin temperature as measured by your wearable, begins to tell a story.
Personalization is what makes these models work. Apple’s Health app and Google Fit both build rolling behavioral baselines for individual users. Deviations from those baselines, not absolute thresholds, trigger the interesting predictions. This is computationally expensive work, and a meaningful portion of it now happens on-device, using the neural processing units built into chips like Apple’s A-series and Google’s Tensor. Processing health data locally addresses some privacy concerns while also reducing latency. Your phone does not need to send your biometrics to a server to notice that you are moving differently today.
Why Apple and Google Want to Own This Space
The competitive logic here is not subtle. Health data is among the most valuable personal data that exists, and it is among the most defensible moats a platform company can build. Once your health baseline lives inside an ecosystem, switching costs become enormous. You would not abandon years of sleep data, menstrual cycle tracking, and cardiac baselines simply because a competitor released a better camera.
This explains moves that might otherwise seem philanthropic. Apple’s ResearchKit and CareKit frameworks, released as open-source tools for medical researchers, were not acts of altruism. They seeded the ecosystem with health applications that generate data, establish user habits, and deepen platform lock-in. The real reason so much software appears free is that the value being extracted is not always visible at the moment of transaction. Health apps fit this pattern perfectly.
Google’s position is structurally different but equally strategic. With Fitbit’s acquisition, Google obtained not just hardware but over a decade of longitudinal health data from tens of millions of users. That dataset is training data. It is the substrate on which more accurate predictive models are built. The company willing to invest most heavily in this infrastructure, and to absorb the engineering costs of doing it right, will own a capability that competitors cannot easily replicate. The math behind that kind of long-term investment looks familiar to anyone who has studied how tech giants allocate engineering resources.
The Privacy Paradox
The same capabilities that make predictive health monitoring remarkable also make it alarming. A system accurate enough to detect pre-symptomatic illness is, by definition, a system with intimate knowledge of your physical state at all times. That data is valuable to insurers, employers, pharmaceutical companies, and governments, none of whom necessarily have your interests as their primary concern.
Current regulatory frameworks were not designed for this environment. HIPAA in the United States covers data held by healthcare providers and insurers. It does not clearly govern health data collected by consumer app developers or platform companies. The gap is substantial. Researchers at Duke’s Sanford School of Public Policy analyzed the privacy policies of the top 20 health and fitness apps and found that 72 percent reserved the right to share data with third parties in ways users would likely find surprising.
The technical capability is running well ahead of the ethical and legal infrastructure. That is not unusual in technology, but the stakes in health are higher than they are in, say, social media recommendation engines. A mistargeted advertisement is annoying. A health prediction shared with a life insurer is something else entirely.
What Comes Next
The trajectory is clear even if the destination is not. Sensors will become more sensitive. Models will become more accurate. The gap between what your phone knows and what you know about your own health will continue to narrow, and then, in some scenarios, reverse entirely.
Clinical trials are already underway testing whether continuous passive monitoring can detect early Parkinson’s disease (via gait and tremor analysis), cardiac arrhythmias (via photoplethysmography sensors in wearables), and the early metabolic shifts that precede Type 2 diabetes. The FDA has cleared several wearable-based diagnostic tools, and the regulatory pathway for software-based diagnostics, while still evolving, is becoming better defined.
For the startups building in this space, the challenges are significant and the failure rate is high. Building accurate predictive health models requires data that takes years to collect, regulatory navigation that requires specialized expertise, and the kind of sustained investment that most early-stage companies cannot maintain long enough to see results. The survivors will likely be the companies that attach themselves to existing platform ecosystems or the ones that find narrow, defensible clinical niches where the data requirements are manageable.
Your smartphone is becoming a diagnostic instrument. The transformation is already underway, embedded in apps you downloaded for other reasons, running on sensors you forgot were there, building a model of your health that grows more accurate with every day you carry the device. Whether that is reassuring or unsettling depends entirely on who has access to the model, and what they intend to do with it.