The Illusion of Redundancy
Every distributed system is designed around a theory of failure. The database has a replica. The load balancer has a standby. The message queue has redundant brokers. Engineers draw diagrams, identify single points of failure, and eliminate them one by one. When they’re done, the system looks resilient.
The problem is that resilience against independent failures is not the same as resilience against correlated failures. Most systems are carefully designed for the former and completely unprepared for the latter. The N+1 redundancy that protects you when one node dies does almost nothing when two nodes fail for the same underlying reason at the same time.
This isn’t a hypothetical concern. It’s the category that explains the majority of serious production outages at companies sophisticated enough to have already solved the obvious reliability problems.
Why Two Failures Are Exponentially Worse Than One
Consider a standard three-node database cluster. You’ve configured it to require quorum: two nodes must agree before a write succeeds, and any two nodes can serve reads. One node can fail and the cluster keeps running. Your runbooks are organized around this scenario. Your on-call engineers have practiced it.
Now imagine two nodes fail simultaneously. You’ve gone from a functioning degraded cluster to a total outage. The same configuration that handled one failure gracefully cannot handle two. And the cause of the second failure is often the first one: a failover floods the surviving nodes with traffic; a node restarts and hammers the others with replication catchup; the automated recovery procedure that was supposed to fix things creates a thundering herd that takes down the nodes that were still healthy.
This is correlated failure, and it’s everywhere. AWS us-east-1 has had multiple major incidents where the mechanism for handling a partial failure became the source of a wider failure. The 2011 Amazon EC2 outage started with a network configuration change that triggered a series of cascading re-mirrorings. Nodes trying to recover overwhelmed the storage layer, which caused more nodes to lose their mirrors, which triggered more recovery attempts. The redundancy became the attack surface.
The mathematics here are unforgiving. If each node fails independently with probability p, two specific nodes fail together with probability p². For small p, that’s negligible. But failures in distributed systems are almost never independent. They share hardware, networks, power, configuration management, deployment pipelines, and the same on-call engineer making decisions at 3 a.m. The actual probability of correlated failure is orders of magnitude higher than the independent model predicts.
The Failure Modes Engineers Don’t Test
The failure modes that get tested are the ones that are easy to test: kill a process, pull a network cable, fill a disk. These are important, but they’re also the failures that experienced distributed systems engineers have already internalized. The genuinely dangerous failures are harder to simulate and so they get skipped.
Partial failures are particularly nasty. A node that is slow instead of dead is worse than a dead node in many architectures. A dead node gets removed from the pool. A slow node keeps receiving traffic, and those requests pile up waiting for timeouts, consuming connection pool slots and thread resources on the callers. One slow database replica can cascade into application servers exhausting their connection pools, which presents to monitoring as an application problem rather than a database problem. By the time you’ve traced it back, you’re in the middle of a second failure.
Configuration drift is another underappreciated risk. In a cluster of nominally identical nodes, subtle differences accumulate over time: different kernel versions, different JVM flags, slightly different memory limits. When a stress event hits, the nodes that were slightly weaker fail first, and if they fail in a way that increases load on survivors, those survivors may be running configurations that make them less resilient to load spikes than you assumed.
The bug that only surfaces under concurrent failure conditions is its own category. These are the bugs that can’t be reproduced in isolation because they require two things to be simultaneously true: a specific state in one component and a specific failure in another. Race conditions in failover logic. Split-brain scenarios that your consensus algorithm was supposed to prevent but doesn’t when the network is both partitioned and slow. Code paths that were written assuming certain invariants hold, invariants that only break when a dependency is in a degraded state.
How to Build Systems That Actually Survive
The first step is honest threat modeling that assumes correlation. When you ask “what if node A fails,” also ask “what tends to fail when node A fails, and what does the failure of node A make more likely to fail.” This is different from fault tree analysis in a useful way: you’re looking for mechanisms of contagion, not just combinations of independent events.
Circuit breakers help, but only if they’re calibrated correctly and tested under realistic failure conditions. A circuit breaker that opens too slowly lets the cascade proceed. One that opens too quickly fragments your system unnecessarily. The only way to know which it is in your specific system is to actually inject correlated failures and watch what happens. Tools like Chaos Monkey were built for this, but most teams use them to simulate single-node failures rather than the correlated multi-component failures that cause the worst outages.
Backpressure is non-negotiable. Systems that accept unlimited load under failure conditions will reliably fail. Every service boundary should have a mechanism to reject work when it can’t be handled safely, and rejection should be fast and cheap compared to the cost of accepting and then failing to handle work. Shedding load gracefully is a feature, not a failure.
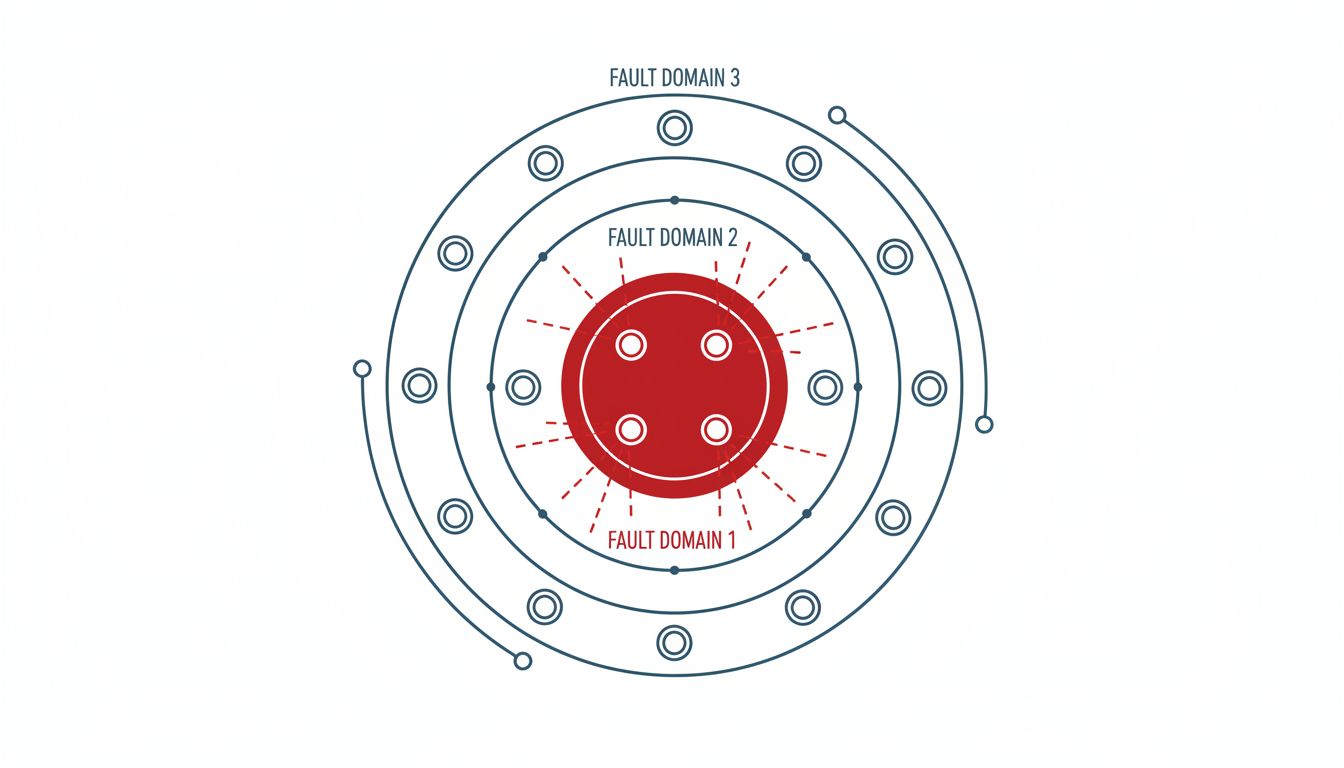
Separation of failure domains matters more than raw redundancy count. Three nodes in the same rack, on the same power circuit, provisioned from the same deployment pipeline, with the same configuration management agent are not three independent failure units. The topology of your redundancy has to match the topology of realistic failure scenarios, which means thinking seriously about blast radius before you hit an incident that demonstrates it for you.
Finally, write runbooks for the scenario where your recovery procedure is making things worse. The instinct under failure is to do more, restart more things, try more approaches. Sometimes the right move is to stop automated recovery from creating a third and fourth failure. Engineers need explicit permission and clear criteria to say “stop, let it stabilize” rather than continuing to intervene.
The Part Nobody Likes Hearing
At sufficient scale, correlated multi-component failure is not a risk you eliminate. It’s a risk you manage and plan around. The goal of resilience engineering isn’t a system that cannot fail in interesting ways. It’s a system that fails in ways you’ve anticipated, where the failure is bounded, where recovery is practiced, and where two things breaking at once doesn’t turn into six things breaking in sequence.
The organizations that handle this well have a habit of treating their past outages as curriculum. Every post-mortem that ends with “we need to improve our monitoring” without asking “why did the first failure make the second one more likely” is leaving the most important lesson unlearned. The incident you had last quarter is telling you something about the incident you’re going to have next quarter, if you’re willing to listen to it.