
AI & Software
Attention Solved One NLP Problem and Created Three More
The attention mechanism fixed sequence modeling but left data hunger, compute costs, and context limits mostly unsolved. The bottleneck just moved.
Inside the algorithms, tools, and systems powering the AI revolution and modern software.
The attention mechanism fixed sequence modeling but left data hunger, compute costs, and context limits mostly unsolved. The bottleneck just moved.

The oldest, ugliest code in your stack is often load-bearing in ways no one fully understands. That's not a coincidence.

Most prompt advice is pattern-matching without understanding. Once you see how attention actually works, the patterns stop being magic and start making sense.

A fintech team's recurring production incident revealed something uncomfortable: their test suite wasn't broken. It was testing the wrong reality entirely.

Every abstraction you write is a bet that you've understood the problem well enough to compress it. The best ones compress it out of existence.

Most people think of prompting as talking to a system. It's not. Your text gets transformed in ways that fundamentally shape what comes back.

Most software bugs are never reported. They're silently absorbed by users who just stop doing the thing that broke. That silence is costing you more than you think.
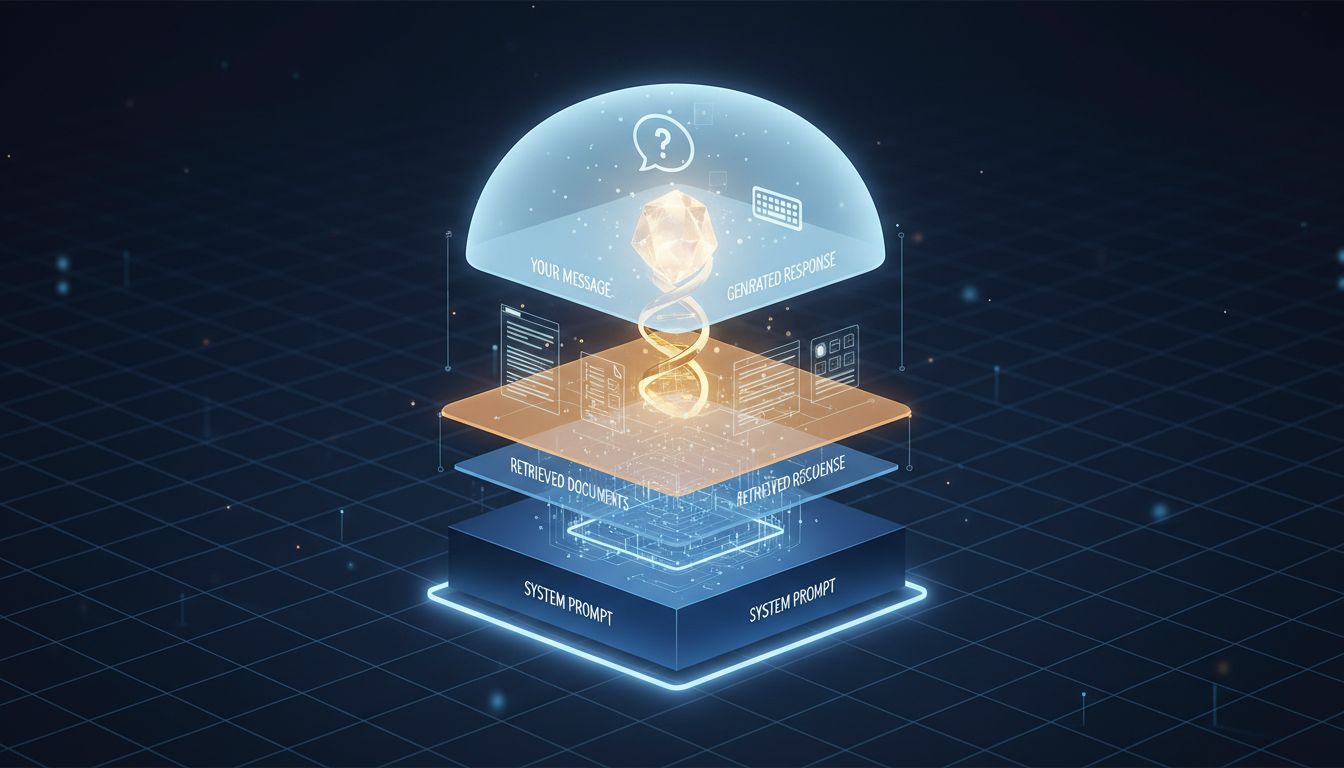
When you send a message to an AI model, it gets transformed before the model ever sees it. Here's what actually happens in that gap.
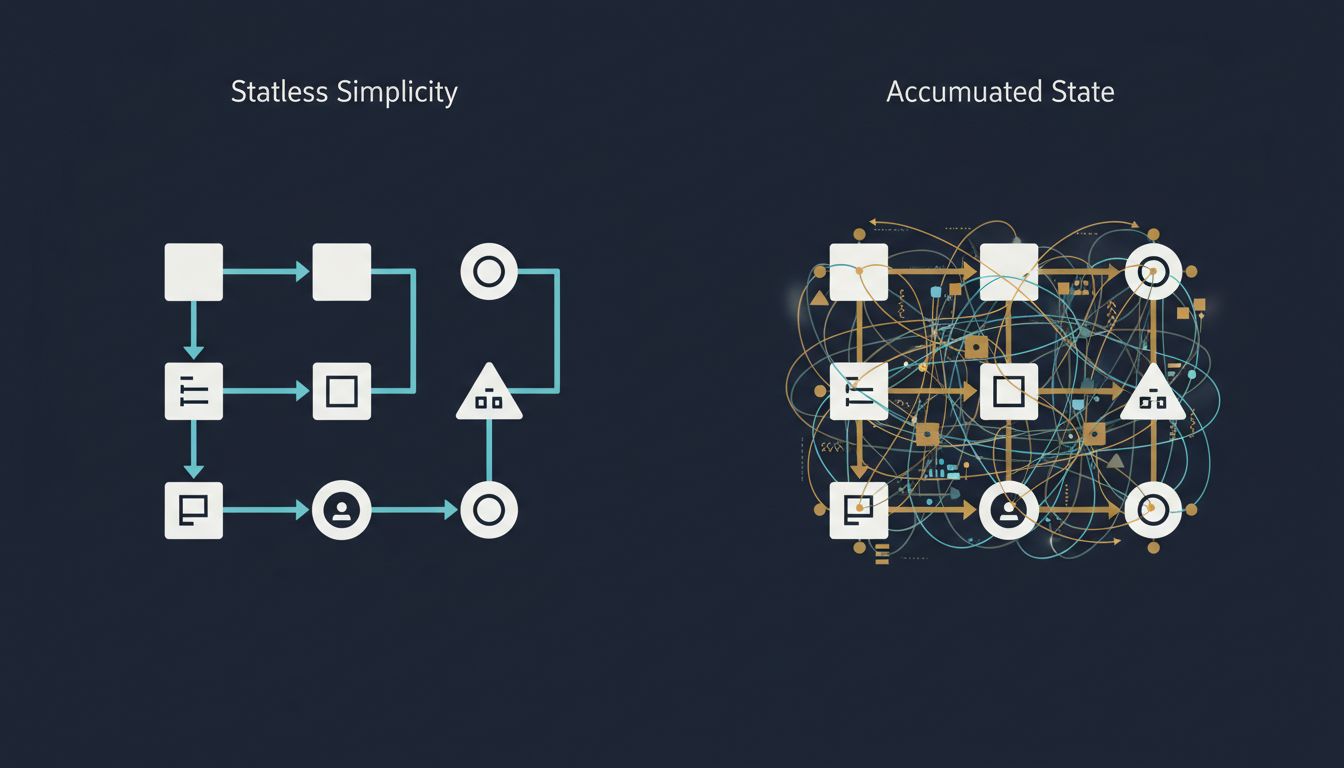
Every developer knows stateless systems are easier to reason about. Yet every system drifts toward stateful complexity. Here's why that happens, and what it costs you.

When you ask an LLM to summarize a document, it isn't reading and condensing. It's doing something stranger and more limited than that.

We obsess over algorithmic complexity and cache efficiency while ignoring the most powerful optimization available: not executing the work at all.
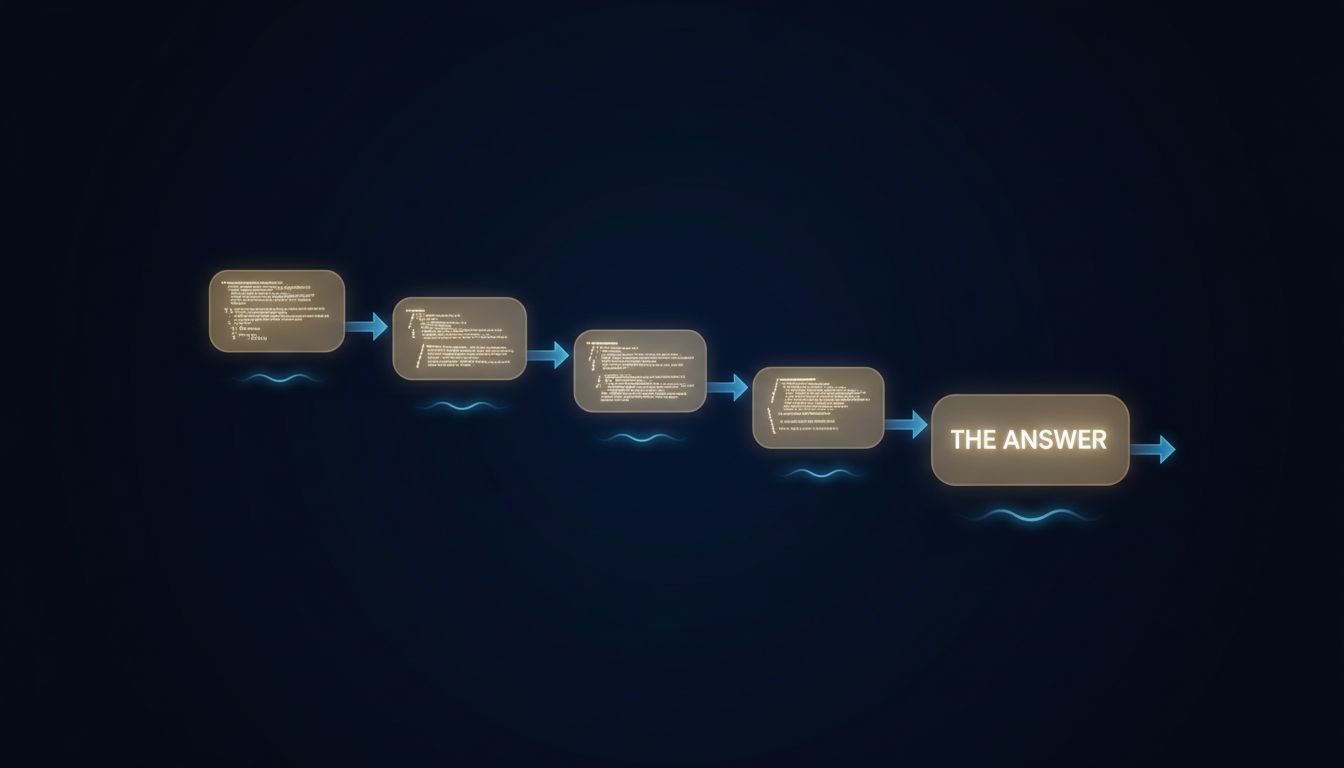
A look at what actually happens inside 'chain-of-thought' prompting, and why the answer matters for how you use these tools.
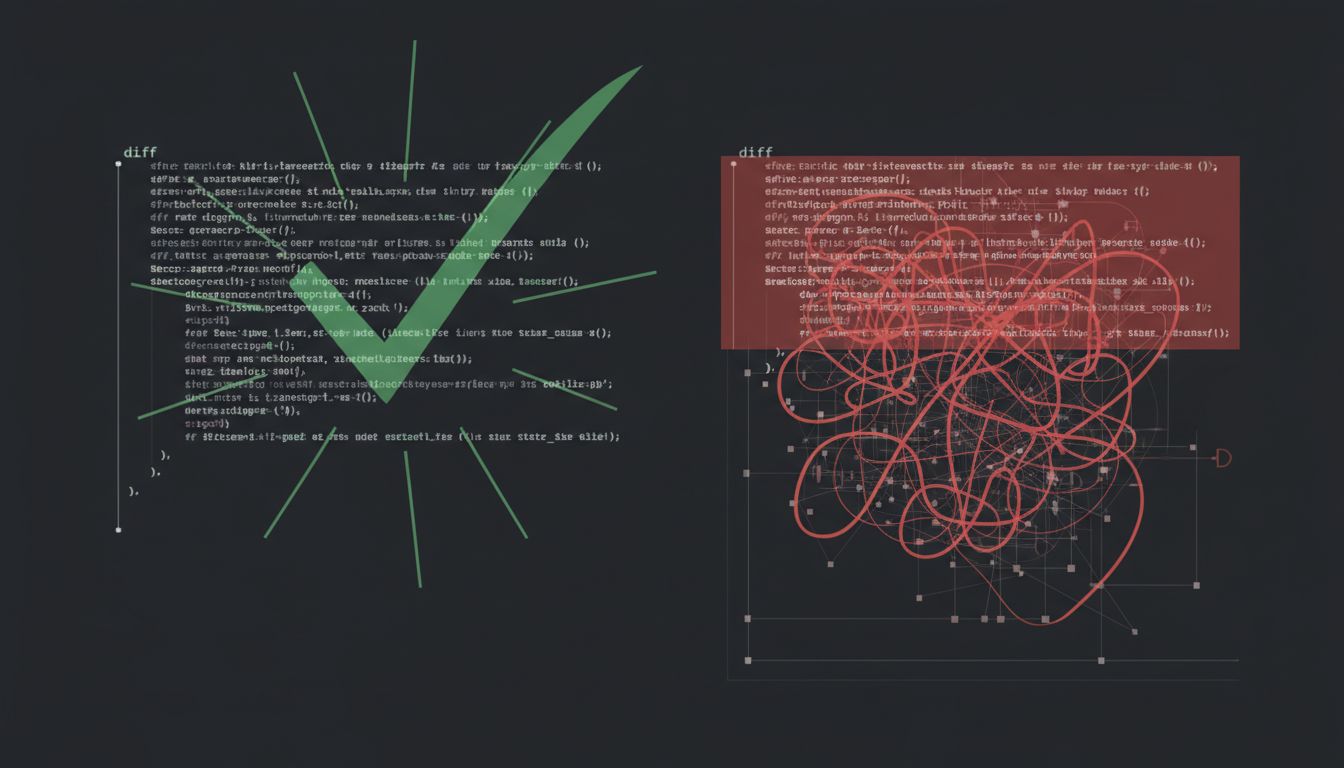
AI coding assistants generate plausible, passing code. That's exactly why they're dangerous. The fix and the solution are not the same thing.

The person who knows how to talk to your AI model may matter more than the person who built it. Here's why that shift is already happening.

Bugs that vanish under observation aren't mysterious. They're symptoms of systems that depend on timing, state, or environment in ways you haven't accounted for.

A 100,000-token context window sounds like perfect memory. It isn't. Here's what's actually happening inside that attention mechanism.

Adding features is celebrated. Removing them is where real engineering judgment lives, and most teams are terrible at it.
Git and its cousins do store your work, but that's the least interesting thing they do. Here's what version control is actually for.
Join thousands of readers who get our weekly breakdown of the most important stories in technology.
Free forever. Unsubscribe anytime.