AI & Software
What Actually Happens When You Deploy a Model to Production
Shipping a machine learning model isn't like shipping software. The failure modes are different, subtler, and far more expensive to debug.
Inside the algorithms, tools, and systems powering the AI revolution and modern software.
Shipping a machine learning model isn't like shipping software. The failure modes are different, subtler, and far more expensive to debug.
Prompt engineering feels like a permanent new skill. It isn't. Here's why that's actually the point, and what comes after it.
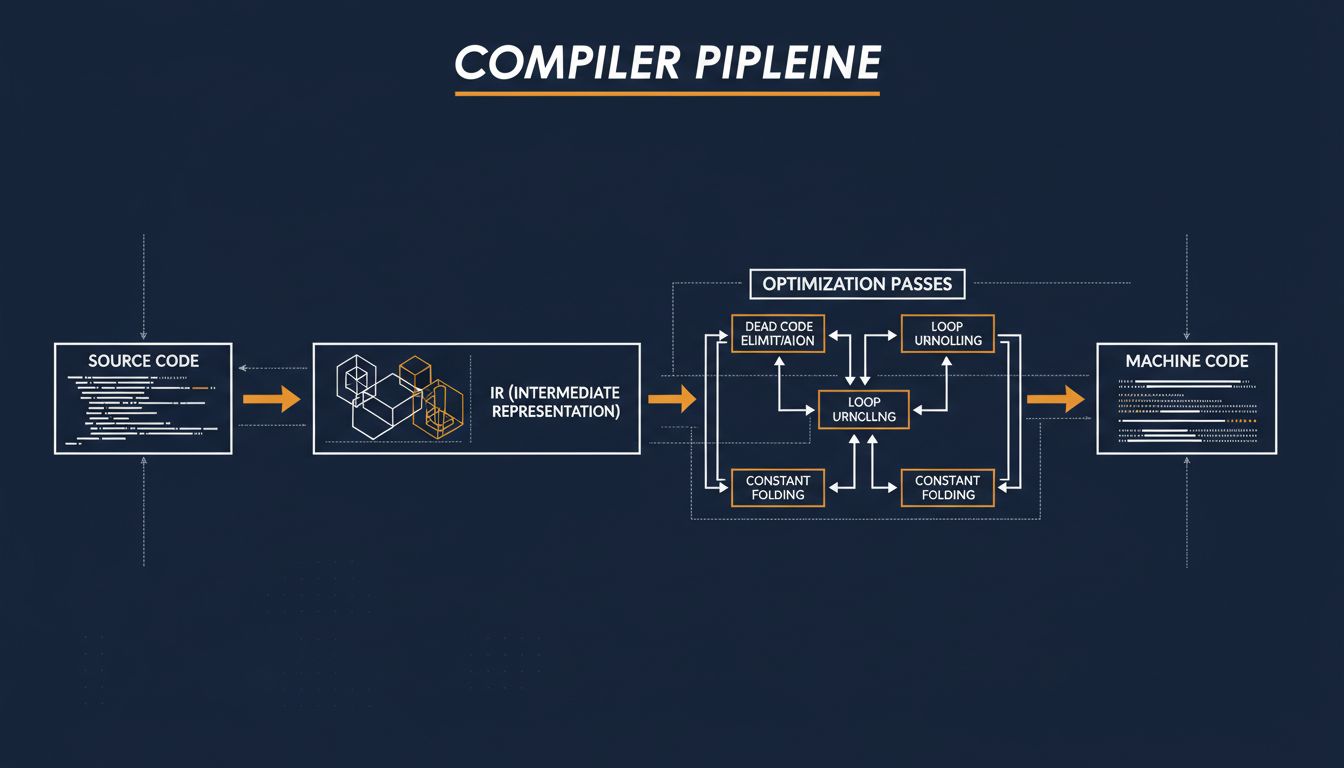
Every technique AI boosters claim is revolutionary, your compiler has been doing since the Reagan administration. Here's what that actually means.

Deleting your account doesn't delete your data from the model. Here's what actually happens, and what it means for you.

Your carefully engineered prompts are dependencies on a moving target. Treat them like any other brittle infrastructure.
Variable names are free at runtime but expensive in practice. Here's why naming is one of the highest-leverage decisions in software.

Better autocomplete doesn't make you a better writer. It makes you a faster one, which is a completely different thing.
Embeddings aren't just a preprocessing step. They're quietly making decisions throughout your AI system, and most teams don't realize it until something breaks.
LLMs encounter novel inputs constantly. Here's the mechanical reality of what happens when a model meets context that falls outside its training distribution.
Every bug that only surfaces in production is a failure of imagination in your test suite. Here's how to read what they're actually saying.

Adding more detail to your AI prompts feels like it should help. Sometimes it does the opposite. Here's why, and what to do instead.

Some bugs disappear the moment you look for them. Understanding why is more useful than any debugging trick.

LLMs don't read your code the way you do. Understanding the gap changes how you use them effectively.

The hottest job title in AI is a repackaging of something engineers have done for decades. That doesn't make it useless — it makes it misunderstood.

Most ML pipelines treat preprocessing as housekeeping. It's actually where you make your most consequential modeling decisions, usually without realizing it.
You're not writing instructions. You're probing a black box with language and inferring the rules from what comes back.

Local testing catches the bugs you anticipated. Production exposes the ones you didn't know to look for. Here's why that gap is structural, not accidental.

A prompt that works perfectly today can silently break after a model update. Here's what happened to one team who found out the hard way, and how to build prompts that survive.
Join thousands of readers who get our weekly breakdown of the most important stories in technology.
Free forever. Unsubscribe anytime.