

The Simple Version
Fine-tuning changes how a model behaves and responds, not what it knows. If you want a model to have new factual knowledge, fine-tuning is the wrong tool.
Why This Matters More Than It Sounds
Every week, a team somewhere fine-tunes a base model, feeds it a pile of proprietary documents, and then feels confused when the model confidently states things that contradict those documents, or worse, ignores them entirely and hallucinates something adjacent. The assumption was: we trained it on our data, so now it knows our data. That assumption is wrong, and the gap between assumption and reality causes real production problems.
Understanding why requires knowing a little about what fine-tuning actually touches.
What Fine-Tuning Actually Modifies
A large language model is, at its core, a massive collection of numerical weights. Billions of them. These weights encode patterns extracted from training data: not facts as discrete stored records, but statistical relationships between tokens (the chunks of text the model operates on). When you ask GPT-style models about the capital of France, it doesn’t look up “Paris” in a table. It generates “Paris” because that token reliably follows certain context patterns, learned across enormous amounts of text.
Pre-training is where those weights get set. It’s an enormous, expensive process run on hundreds of billions of tokens of text, and it’s where the model builds its underlying world model, its vocabulary of concepts, its reasoning scaffolding.
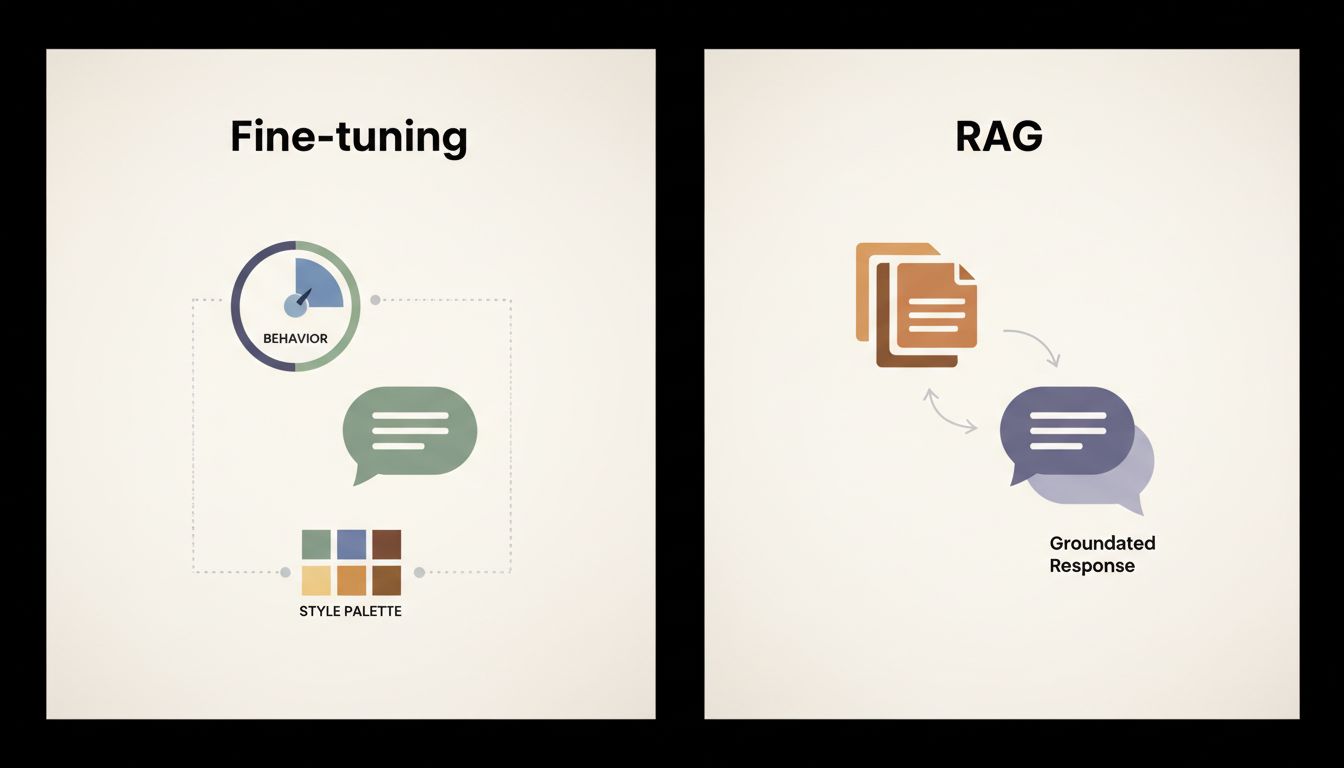
Fine-tuning comes after. You take a pre-trained model and continue training it, but on a smaller, curated dataset, usually formatted as input-output pairs. This updates the weights, but subtly. The model doesn’t forget its pre-training (a phenomenon called catastrophic forgetting can happen if you push too hard, but that’s a separate problem). Instead, the fine-tuning adjusts the model’s output distribution. It shifts the model toward particular styles, formats, registers, and response patterns.
This is why fine-tuning is genuinely excellent at teaching a model to respond like a customer support agent, to always output valid JSON, to match a specific editorial voice, or to refuse certain categories of questions. These are behavioral properties. They travel well through fine-tuning.
Facts, on the other hand, are encoded in the weights in a distributed, entangled way during pre-training. Trying to inject a new fact via fine-tuning is like trying to change the meaning of a word by rearranging a paragraph that uses it. You might nudge behavior, but you’re not inserting a clean, retrievable record.
The Practical Failure Mode
Here’s a concrete scenario. You have internal documentation about your product, including version numbers, pricing tiers, and specific feature behaviors. You fine-tune a model on this documentation, expecting it to serve as an intelligent help desk. Two months later, a user asks about a pricing tier that was updated last month. The model, confidently, gives the old answer. Sometimes it gives a blended answer. Sometimes it invents a tier that never existed.
This isn’t a bug in the fine-tuning process. It’s the process working as designed. You adjusted the model’s personality to discuss your product domain fluently. You didn’t write accurate, retrievable facts into it.
The architectural solution to this is retrieval-augmented generation (RAG). RAG keeps facts outside the model entirely, in a vector database or document store, and retrieves relevant chunks at inference time (the moment a query is made). The model then reasons over those retrieved facts rather than trying to recall them from weights. RAG is genuinely better at grounding factual claims in specific, updatable sources. If your pricing changes, you update the document store. No retraining required.
Fine-tuning and RAG solve different problems, and many production systems use both: RAG for accurate, up-to-date factual grounding, fine-tuning for consistent tone, format, and behavioral guardrails.
What Fine-Tuning Is Actually Good For
Once you stop trying to use fine-tuning as a fact-injection mechanism, its real strengths become clear.
Format adherence is one of the strongest use cases. If you need a model to always return structured output, say a JSON object with specific keys, fine-tuning on examples of that format is highly effective. The model learns the pattern deeply enough that it becomes a default, not just a prompt-level suggestion.
Tone and voice are another. This is why many companies fine-tune models to match brand voice or communication style. Your mental model of the LLM is probably doing something similar: you’re imagining a model that reasons and retrieves, when it’s actually a very sophisticated pattern-completer that you can steer toward particular patterns.
Task specialization matters too. A model fine-tuned heavily on medical intake summaries will structure clinical information more reliably than a general-purpose model given a prompt. It’s not that the fine-tuned model knows more medicine. It’s that it has internalized the shape of how that domain’s information gets expressed.
Fine-tuning also helps with refusals and safety boundaries. Teaching a model to consistently decline certain request types, or to always ask for clarification before taking action, is behavioral, and it sticks through fine-tuning in ways that prompting alone sometimes doesn’t.
The Useful Mental Model
Think of a pre-trained base model as a very well-read generalist who has absorbed an enormous amount of human knowledge. Fine-tuning is professional training: you’re turning that generalist into someone who talks like a doctor, structures things like an accountant, or responds with the patience and boundaries of a support specialist. Their underlying knowledge doesn’t fundamentally change. Their professional habits do.
RAG is giving that person a filing cabinet they can check before answering. The combination is more capable than either alone, but only if you understand what each one is contributing.
The teams that get the most out of fine-tuning are the ones who stop trying to use it as a memory system and start using it as a behavior system. The model’s personality is genuinely trainable. Its recall of injected facts is not reliably so. Working with that distinction, rather than against it, is where most of the practical leverage actually lives.





