
Prompt Engineers Are Optimizing for the Wrong Thing
If you spend time in prompt engineering communities, you’ll notice a pattern. People share prompts the way anglers share lures: here’s the exact wording that got GPT-4 to write better code, here’s the magic phrase that stops hallucinations, here’s how to make it sound less like a robot. The pursuit is specific, sincere, and mostly pointed in the wrong direction.
The dominant mental model in prompt engineering treats the problem as one of output quality. Write a better prompt, get a better response. Iterate until the response is good enough. This makes intuitive sense, and it produces real improvements, which is probably why it persists. But optimizing for output quality is like optimizing a function call for speed without considering how often it runs or whether it should exist at all.
The thing worth optimizing for is reliability at scale, and most prompt engineering practice makes this harder, not easier.
What ‘Better Output’ Actually Means in Practice
When you refine a prompt to get a better response, you’re solving a sample-size-one problem. You run the prompt, you evaluate the output, you tweak the prompt, you run it again. Eventually you have something that produces a response you like.
The trap is that LLM outputs are non-deterministic. Even at temperature zero, subtle differences in context, model version, and tokenization can shift outputs. A prompt that reliably produces excellent results in your testing session can degrade when you deploy it, when the underlying model is updated, or when real users supply inputs you didn’t anticipate.
This isn’t theoretical. Anyone who has built production systems on top of LLMs has encountered the prompt that worked great in demos and fell apart in production. The output you saw during testing was not a reliable sample of the distribution of outputs you’d get over thousands of real requests.
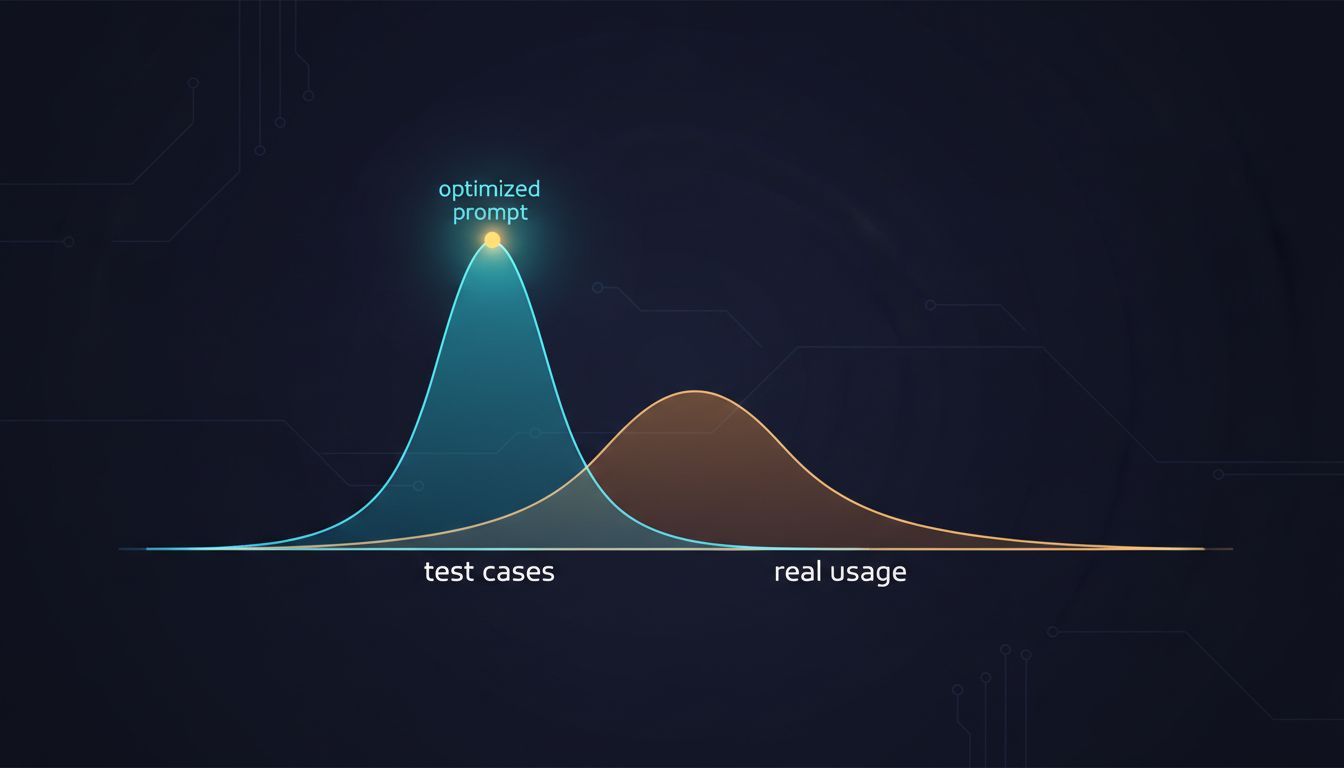
Optimizing for a single good output is optimizing for a local maximum that may not generalize.
The Metric You’re Probably Not Measuring
Here’s a practical question: when you evaluate whether a prompt is good, what are you actually measuring?
Most people measure output quality on a handful of test cases they constructed themselves. These test cases are biased toward inputs you can imagine, which is a subset of inputs you’ll actually receive. The prompt that scores well on your handcrafted tests is optimized for your imagination of the problem, not the problem itself.
The alternative is to define what good enough means across the full distribution of realistic inputs, then measure your prompt’s pass rate against that definition. This requires three things most prompt engineering workflows skip: a representative test set drawn from real or realistic usage, a clear and automatable definition of success, and enough volume to detect meaningful differences between prompt versions.
This is, essentially, how you should think about software testing applied to prompts. A prompt that passes your curated test suite but fails on real traffic is a prompt you don’t understand yet.
Building that infrastructure is tedious. It’s less satisfying than finding the clever phrasing that makes the model do something impressive. That’s exactly why most teams don’t do it.
The Fragility Problem Nobody Talks About
Prompts are brittle in ways that feel arbitrary until you understand why. The mechanics of how LLMs process instructions mean that small changes in wording can produce large changes in behavior, not because the semantic content changed but because the token-level representation did.
This creates a practical problem: the more precisely tuned your prompt, the more tightly coupled it is to a specific model’s idiosyncrasies. When OpenAI or Anthropic or Google updates their models (and they do, regularly, sometimes without announcement), your carefully tuned prompt may start producing worse results. You’ve optimized for a moving target.
Teams that invest heavily in prompt-level optimization often find themselves in a continuous maintenance loop, re-tuning prompts after model updates the same way they’d patch software after a dependency change. This is real engineering overhead that rarely shows up in discussions about the value of prompt engineering.
The more sustainable approach is to invest in prompts that are robust to variation rather than prompts that are optimal for current conditions. These are different objectives, and they require different thinking. A robust prompt might produce slightly lower peak quality than a highly tuned one, but it degrades gracefully when conditions change.
Where the Real Leverage Is
If output quality on individual queries is the wrong thing to optimize for, what’s right? There are three areas that consistently matter more.
Task decomposition. LLMs perform better on smaller, clearer tasks than on large, ambiguous ones. The biggest gains in output quality usually don’t come from rewording a prompt; they come from breaking a hard task into subtasks that are each well-defined. A prompt asking a model to read a contract, identify risks, classify them by type, and estimate severity will produce worse results than four prompts, each handling one of those steps. The engineering work is in the decomposition, not the phrasing.
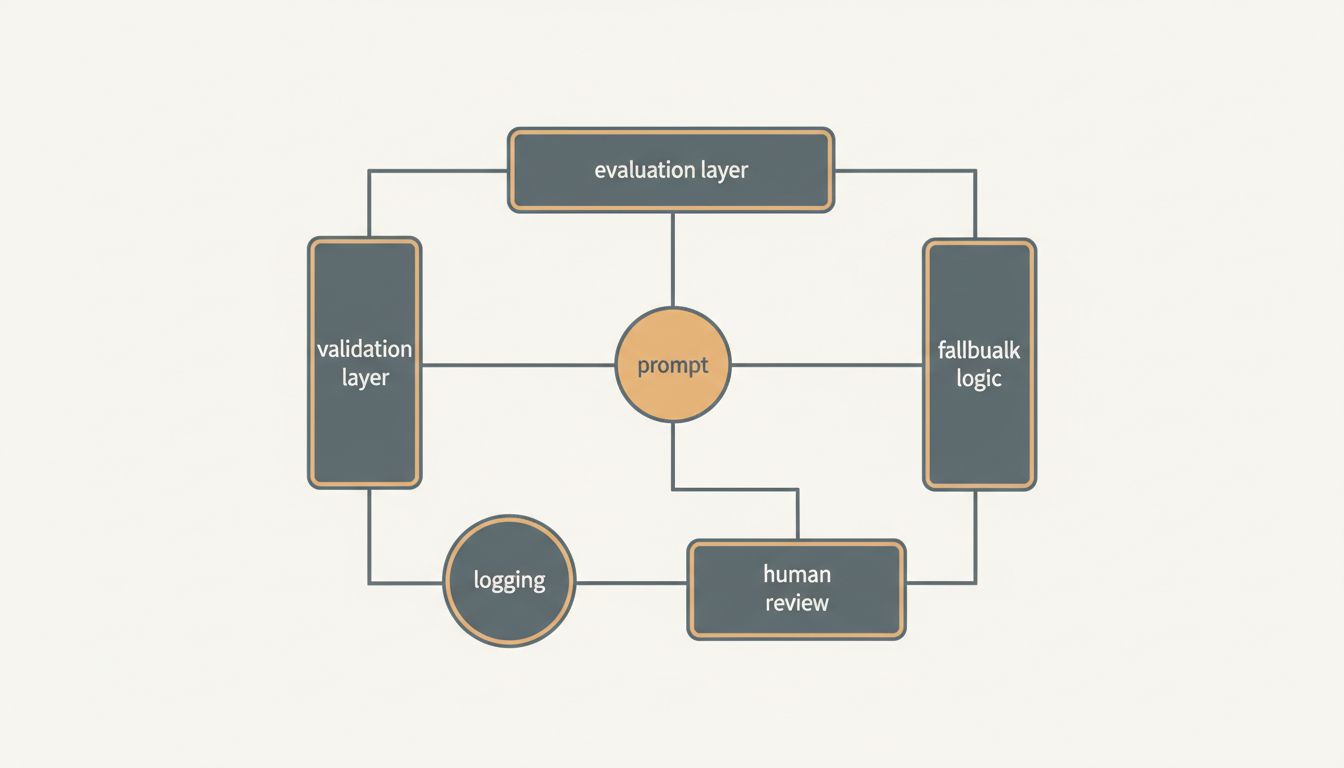
Failure mode identification. Every prompt has characteristic failure modes: the categories of input where it reliably produces wrong, incomplete, or dangerous outputs. Most prompt engineering treats failures as random noise to be minimized through better phrasing. They’re not random. If you run a prompt across enough varied inputs, you’ll see patterns. Identifying those patterns lets you build targeted guardrails, alternative handling, or fallback logic, which is more durable than hoping better phrasing eliminates the failures.
Output validation. The output of an LLM call is untrusted input from your system’s perspective. Treating it that way, with parsing, validation, and graceful handling of malformed or out-of-spec responses, is worth far more than incremental improvements in how often the model produces well-formed output in the first place. A system that validates outputs and handles failures is more reliable than one that tries to prompt its way to perfection.
The Professional Distortion
There’s a social dimension to this worth acknowledging. “Prompt engineering” as a job title or professional identity creates incentives to value prompt-level craft above other approaches. If your expertise is in writing prompts, you’re naturally going to frame problems as prompt problems and solutions as prompt solutions.
This isn’t cynical, it’s just how expertise shapes perception. A developer who knows SQL tends to reach for database solutions. A prompt engineer tends to reach for prompt solutions. The issue is that many of the hard problems in building LLM-based systems are not prompt problems. They’re architecture problems, evaluation problems, reliability problems, and product problems.
The teams building the most dependable LLM-powered products tend to treat prompts as one component in a larger system rather than the primary surface of optimization. They write prompts that are clear and direct, and they spend the rest of their energy on the surrounding infrastructure: the evals, the logging, the validation, the fallbacks, the human review loops for high-stakes outputs.
What Good Prompt Practice Actually Looks Like
None of this means prompt wording doesn’t matter. It does. A vague prompt produces worse results than a clear one. Providing relevant context helps. Specifying output format reduces parsing errors. These are real and worth doing.
The useful framework is to think of prompt quality as a hygiene factor rather than a differentiator. Getting prompts to a reasonable baseline quality is worth the effort. Spending hours on marginal improvements beyond that baseline, without corresponding investment in evaluation and reliability infrastructure, is where the returns collapse.
Concretely: write prompts that are specific about the task, clear about the output format, and explicit about what the model should do when it’s uncertain. Then build evals. Then measure pass rates on realistic inputs. Then identify failure modes and handle them in code. Then think about whether the architecture is right.
That ordering matters. Most teams do it roughly in reverse, which is why they find themselves polishing prompts that sit on a foundation that isn’t solid.
What This Means for Your Work
If you’re building anything serious with LLMs, here’s the practical reframe.
Your prompt is an interface, not a product. It needs to be clear and correct, but its quality ceiling is determined by your evaluation and reliability infrastructure, not by the cleverness of its wording. A great prompt running without evals is guesswork. A decent prompt with solid evals is engineering.
Define what success looks like before you start optimizing. “Better outputs” is not a definition. “Responses that correctly identify the key clause in a contract 90% of the time across this set of 200 sample contracts” is a definition you can work with.
Budget time for failure mode analysis. Run your prompt on messy, edge-case, adversarial inputs. The failures you find are more valuable than the successes you’re already getting.
Treat model updates as a recurring risk. Your prompt may degrade without warning. The mitigation is not to write prompts that are somehow immune to this; it’s to have evals that detect degradation quickly when it happens.
The goal isn’t a perfect prompt. It’s a system that behaves reliably under real conditions and tells you clearly when it doesn’t.





