
Most people who use LLMs regularly have a mental model that goes something like this: you type words, the model reads words, the model responds. It’s intuitive, and it’s wrong in ways that matter.
The text you submit is the beginning of a transformation pipeline, not the end. By the time anything resembling “your prompt” reaches the part of the system doing the actual work, it has been restructured, expanded, possibly compressed, tokenized into a numeric sequence, and positioned inside a context window that already contains content you never wrote. Understanding that pipeline explains a significant chunk of otherwise mysterious model behavior.
Tokenization Breaks Words in Unexpected Ways
The first transformation happens before anything else: your text gets converted to tokens. Tokens are not words. They are chunks of characters that a model’s vocabulary maps to integers, and the boundaries between them are determined by the training corpus, not by linguistic logic.
The GPT-4 tokenizer (based on tiktoken, which you can inspect directly) splits “unhappiness” into two tokens but “running” into one. “ChatGPT” is three tokens. A single space before a word often becomes part of that word’s token rather than a separate unit. The word “Joe” and ” Joe” (with a leading space) are typically different tokens with different numerical representations.
This matters because the model reasons over token sequences, not word sequences. Arithmetic errors, misspellings that confuse the model, and character-counting failures (“how many r’s in strawberry?”) aren’t signs of stupidity. They’re artifacts of a system that never directly sees individual characters. When you ask a model to count letters, it’s being asked to reverse-engineer something it never had access to in the first place.
The System Prompt Is a Prior Tenant
When you interact with any deployed LLM product, your message almost never enters a blank context. There’s a system prompt installed before you type anything. It might define the assistant’s persona, restrict topics, specify output format, or inject context about your account or session.
The exact contents are almost always hidden from users. OpenAI’s ChatGPT, Anthropic’s Claude.ai, Google’s Gemini interface, and every API-wrapped product from startups all prepend instructions you can’t see. Some of these system prompts are long. Researchers have extracted system prompts from various products through prompt injection and jailbreak techniques, and many run to hundreds or thousands of tokens.
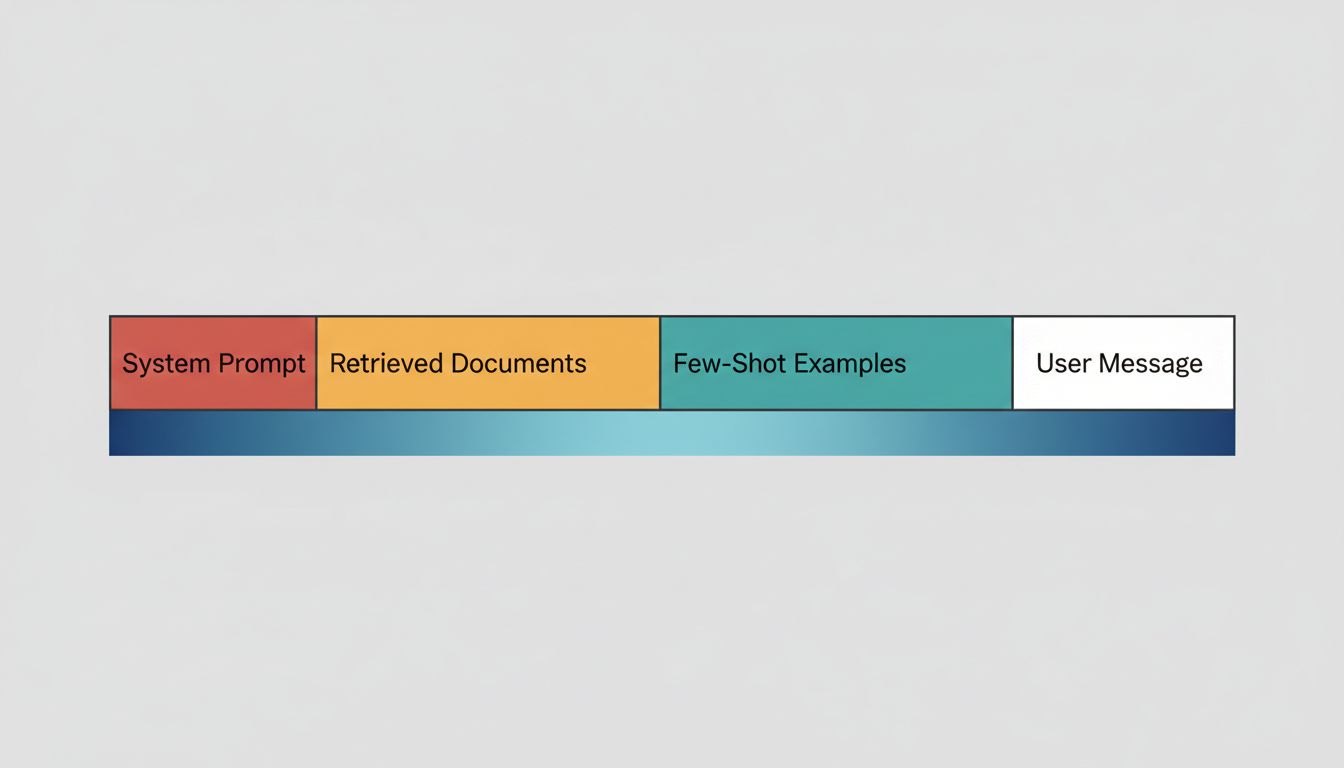
Your “first” message in a conversation is actually the third or fourth structural element in the context window, after at least a system turn and potentially example conversations planted to shape behavior. When a model seems to refuse something unexpectedly, or responds in a slightly odd register, an invisible system prompt is often the explanation.
Context Windows Have a Shape, Not Just a Size
Even if you know your model has a 128,000-token context window, knowing the size doesn’t tell you how attention is distributed across it. Research on transformer attention mechanisms, including work from teams at DeepMind and academic groups studying long-context behavior, consistently finds that models don’t weight all positions equally.
The phenomenon usually called “lost in the middle” refers to the empirical finding that information placed in the middle of a long context is retrieved less reliably than information at the beginning or end. A 2023 paper from Stanford (“Lost in the Middle: How Language Models Use Long Contexts” by Liu et al.) documented this pattern across multiple models and task types. The effect weakens with newer architectures but hasn’t disappeared.
The practical implication is that where you put something in your prompt affects how much influence it has. Instructions buried in the middle of a long prompt carry less weight than instructions at the start or end. If you’re building a RAG pipeline and stuffing retrieved documents into the middle of a context while putting instructions at the edges, you’re working with the architecture. If you’re doing it the other way around, you’re working against it.
Few-Shot Examples Are Instructions in Disguise
One of the more useful prompt engineering patterns is providing examples of the desired output format before asking for the real output. This is few-shot prompting, and it works well, but it’s worth understanding why.
When you give the model examples, you’re not just showing it a format. You’re shifting the probability distribution over its output by giving it a recent, high-relevance reference to pattern-match against. The model isn’t reading your examples the way a human reads a rubric. It’s processing them as part of a continuous token sequence, and the statistical weight of those examples bleeds into the generation that follows.
This means few-shot examples can do things you didn’t intend. If your three examples all use formal language, the model will tend toward formality even if you explicitly asked for casual tone. If your examples all happen to be about the same domain, the model may generalize domain-specific assumptions into outputs about different domains. The examples you include are an implicit prior, not just a formatting guide. What your LLM is actually doing when you say think step by step covers related ground on how structural prompting patterns influence generation at a mechanistic level.
Retrieval Augmentation Adds an Invisible Third Party
In RAG (retrieval-augmented generation) systems, the prompt that reaches the model contains retrieved documents that the user never wrote or reviewed. A user asks a question, a retrieval system pulls what it judges to be relevant chunks from a knowledge base, and those chunks get injected into the context before the model sees the user’s query.
The model then generates a response that may be heavily shaped by whatever the retrieval system surfaced, including outdated documents, low-quality matches, or content that introduces conflicting information. The user sees an answer that references none of this machinery. From their perspective, they asked a question and got an answer. From the model’s perspective, it synthesized across several documents of varying relevance, then produced something that reads like an original response.
This creates an interesting failure mode: the model confidently incorporates retrieved content that’s wrong or outdated because the retrieval step is invisible to it. The model has no way to question whether the documents it was handed are good sources. It processes them as given context, the same way it processes anything else in the context window. Garbage in, confident synthesis out.
Instruction-Following Is a Probability, Not a Guarantee
Models don’t parse instructions the way a computer parses code. There’s no if-statement that says “if the user says reply in French, reply in French.” There’s a system that has learned, across billions of training examples, that certain inputs tend to correlate with certain outputs. Instruction-following works because that correlation is strong, not because there’s a parser enforcing it.
This explains why instructions sometimes fail and why the failure mode is probabilistic rather than binary. Tell a model to always use bullet points and it will mostly use bullet points, with occasional exceptions when something in the context makes prose-completion more probable. Tell it to never mention a competitor and it will usually comply, but edge cases exist.
It also explains why instruction order and phrasing matter more than they intuitively should. “Do not include any caveats” and “Avoid adding unnecessary caveats” are semantically similar but land differently in practice because they activate different learned patterns. This isn’t a bug to be patched. It’s a consequence of building systems that generalize from data rather than execute from rules. Prompt engineers are optimizing for the wrong thing makes the related argument that obsessing over exact wording often misses the more important structural questions.
What This Means
If you’re building with LLMs rather than just using them, this pipeline view is genuinely load-bearing. A few things follow directly:
Tokenization matters for precision tasks. Character-level tasks (counting, exact string matching, spelling) are harder than they look because the model never sees characters. Either handle them outside the model or structure the task to avoid requiring character-level precision.
Your instructions compete with invisible ones. In any deployed product, there’s a system prompt you don’t control. Unexpected behavior is often explained there, not in your prompt. If you’re building on top of an API, you control this layer and should take it seriously.
Position in the context window is a design decision. Critical instructions belong at the beginning or end. Retrieved documents should be positioned to support rather than bury the task definition.
Examples set implicit priors. Be intentional about what your few-shot examples signal beyond their explicit content. Tone, domain assumptions, and format all propagate.
Retrieval pipelines need quality control. The model will incorporate whatever it’s given. Retrieval quality directly determines generation quality, and the model can’t compensate for a bad retrieval step.
The model you’re interacting with is not reading your words. It’s processing a numerical sequence assembled from your words, a system prompt, possibly retrieved context, and prior turns, after a tokenizer has done its own kind of violence to your original text. That’s the thing doing the reasoning. Building a useful mental model of that pipeline is more valuable than any individual prompting trick.





