The Setup
Somewhere around 2023, a mid-sized fintech company (one of several whose internal postmortems have circulated in engineering forums without full attribution) made a reasonable bet. They had a payments reconciliation service, a backlog of feature work, and a newly licensed Copilot seat for every engineer on the team. Within a month, their sprint velocity, measured in story points closed, had roughly doubled.
The reconciliation service handled the unglamorous work of matching outgoing payment records against bank statement entries. Small discrepancies, typically rounding errors and timing differences, needed to be bucketed, flagged, or written off according to a set of business rules that had accreted over years. The kind of code that works fine until it doesn’t, and when it doesn’t, finance teams notice.
An engineer used an AI coding assistant to implement a new matching heuristic. The generated code looked good. It passed code review. The unit tests passed. The integration tests passed. It shipped.
Six weeks later, a $0.01 rounding difference in one matching path was silently writing off discrepancies it should have been escalating. The bug had been in production the entire time, accumulating small errors that, in aggregate, were not small at all.
What Actually Happened
To understand why this keeps happening, you need to understand what an AI coding assistant actually is and isn’t doing when it generates code.
Models like GitHub Copilot, Claude, or GPT-4 are trained on enormous corpora of text, including a large fraction of publicly available code. They learn statistical relationships: given this context, these tokens tend to follow. When you describe a matching heuristic and ask for an implementation, the model generates code that looks like the kind of code that appears after similar descriptions in its training data.
That’s a genuinely useful capability. It’s also a fundamentally different thing from understanding what your reconciliation service is supposed to do.
The model has no access to your production data. It doesn’t know the edge cases your business rules were written to handle. It doesn’t know that a previous engineer left a comment three files away explaining why a particular rounding behavior was intentional. It cannot run the code. It cannot observe whether the output of a function matches the expected business outcome, only whether the code is syntactically plausible and structurally similar to patterns it has seen before.
This is the core problem. Code generation and code verification are completely different tasks, and current AI assistants are only doing one of them.
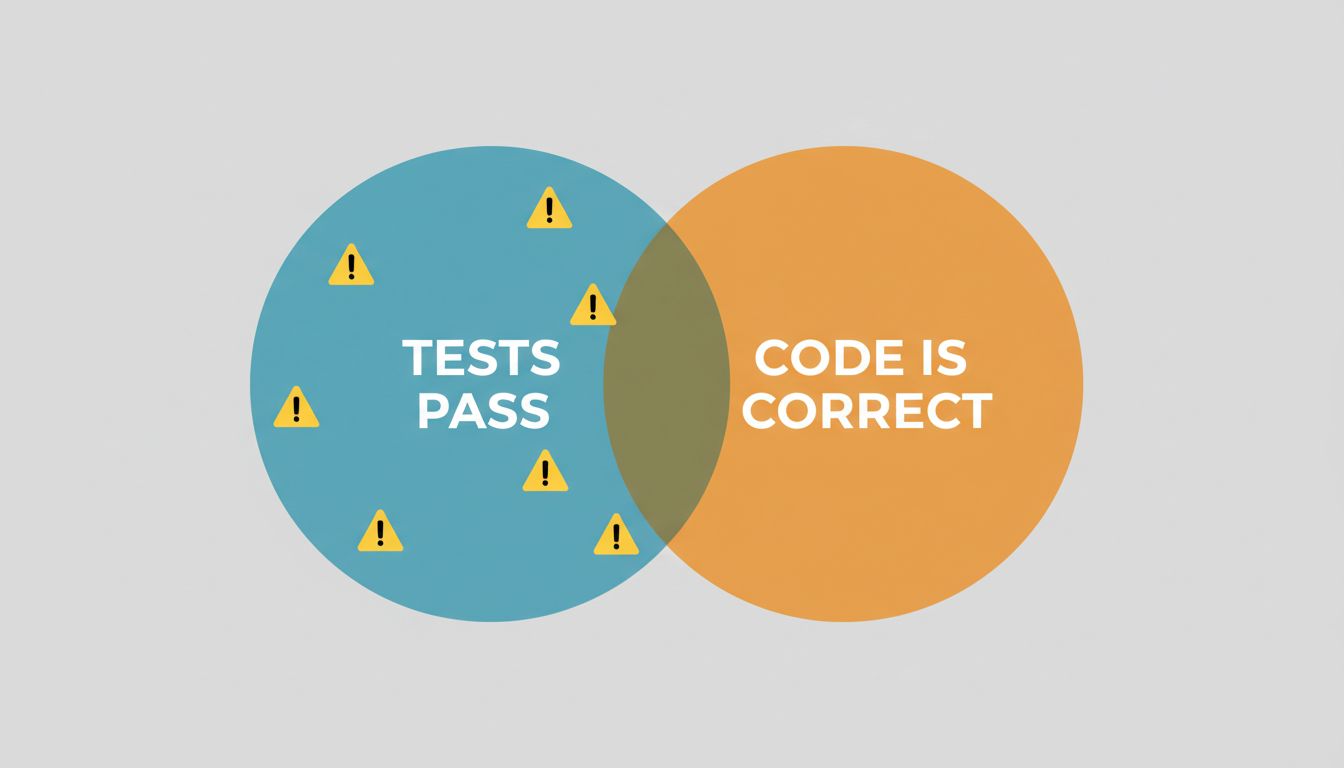
The unit tests passing is a particularly seductive false signal here. A unit test verifies that a function, given specific inputs, returns specific outputs. It says nothing about whether those specific inputs and outputs were the right ones to test. If the AI generates both the implementation and the tests (a common workflow, and a tempting one), you now have code and tests that are mutually consistent but potentially both wrong in the same direction. They agree with each other, not with reality.
This is structurally similar to silent bugs are the ones that actually ruin you: the failure mode isn’t a crash or an exception. It’s behavior that runs quietly and incorrectly for an extended period.
Why Velocity Metrics Make This Worse
The fintech team’s sprint velocity doubling was real. They were closing more tickets. The AI was genuinely helping them write more code faster. The problem is that writing code and shipping working software are related but distinct activities, and the metrics they were tracking only measured the first one.
This creates a particular organizational pressure. If your team looks more productive than ever by the numbers, it’s hard to slow down and ask whether the productivity measurement is capturing the right thing. Story points closed is a proxy for delivered value, and it’s a proxy that was always somewhat shaky. Adding AI code generation to the workflow makes it shaky in a new and specific way: it can dramatically increase output at the typing-code layer while doing nothing for, or even subtly degrading, correctness at the working-software layer.
The engineers weren’t being careless. They were doing code review. But code review on AI-generated code has its own trap: the code often looks clean and idiomatic because it was generated from patterns in clean, idiomatic open-source code. It reads well. The reviewer’s brain says “this looks right” without necessarily having verified that it is right for this specific context.
What We Can Learn
The lesson isn’t “don’t use AI coding assistants.” That’s the wrong takeaway. The lesson is about where in the development workflow these tools actually help and where they introduce new risk.
AI assistants are good at: generating boilerplate, translating a well-specified requirement into a first draft of code, writing tests for logic you’ve already verified is correct, explaining unfamiliar code, and catching obvious syntactic and stylistic issues.
They are poor at: understanding your system’s specific invariants, knowing which edge cases matter in your business domain, verifying that generated code is semantically correct for your use case, and reasoning about the downstream effects of code on data that lives outside the conversation window.
The practical implication is that the verification layer needs to get stronger as generation gets faster, not stay constant. If your team is writing code twice as fast, your property-based tests (tests that verify behavior across a range of generated inputs, not just the specific cases you thought to write), your integration test coverage, and your production monitoring all need to keep pace. They probably aren’t.
For domains with correctness requirements that can’t be eyeballed, a few specific practices help. First, write the tests before using AI to implement the function. The tests should come from your understanding of the business rules, not from the model’s inference about what the function ought to do. Second, treat AI-generated code that touches financial calculations, security-sensitive paths, or data integrity constraints as requiring a higher review bar than other code. Not because the model is uniquely bad at these things, but because the cost of a quiet error in these areas is unusually high. Third, instrument your production systems to catch semantic errors, not just exceptions. A function that returns the wrong number without throwing is invisible to error rate dashboards.
The deeper point is about what verification actually means. For a long time, “the tests pass” was a reasonable shorthand for “this probably works.” It was always an approximation, but a workable one when the same engineer who understood the requirements also wrote the implementation. When generation is decoupled from understanding, that shorthand breaks down. The tests passing tells you the code is internally consistent. It doesn’t tell you it’s correct.
The fintech team fixed the bug, added property-based tests for the reconciliation matching logic, and kept using their AI coding tools. The velocity number went down slightly. The software got more reliable. That’s roughly the right trade.
The AI that writes your code is a smart autocomplete that has read a lot of code. It doesn’t know what your software is for. Keeping that distinction clear is the engineering team’s job, and it doesn’t get automated away just because the typing does.