
The Setup
In 2004, Amazon was scaling rapidly and running into a familiar problem: engineers were shipping features faster than the underlying systems could reliably support them. Outages were frequent. Coordination costs between teams were climbing. Jeff Bezos sent what became known internally as the “API mandate” memo, demanding that all teams expose their data and functionality through service interfaces and communicate only through those interfaces. No exceptions.
To enforce it, Amazon hired a new kind of engineer, someone whose primary job was not to ship features but to prevent other engineers from building the wrong things in the wrong ways. These were not managers. They were not PMs. They were deeply technical people whose output was largely invisible: design reviews, architecture guidance, standards documents, and the occasional well-placed “no.”
Amazon’s internal services eventually became AWS. The cumulative effect of that invisible work is a business that generated over $90 billion in revenue in 2023.
This is not a coincidence.
What Happened
The economic logic here is underappreciated, partly because most engineering organizations measure output the wrong way. Commits merged. Pull requests closed. Tickets resolved. These metrics are easy to count and deeply misleading.
Consider what happens when a senior engineer reviews a proposed architecture and spots a fundamental flaw before any code gets written. If that flaw would have required six engineers three months to undo later, the reviewer just created the equivalent of 18 engineer-months of capacity by spending two hours in a design session. That contribution never appears on any dashboard.
This is the core tension in how tech companies value engineering labor. Output is visible. Prevention is not.
The engineers who provide the highest preventive value tend to share a few traits. They have broad enough experience to recognize patterns that junior engineers don’t yet know are dangerous. They have enough credibility to be heard when they raise concerns. And critically, they have enough patience to do slow, careful work in an environment that constantly rewards speed.
The problem is that most performance review systems are structurally incapable of capturing this. When Google introduced its engineering ladder formalization in the mid-2000s, one of the explicit criteria for Staff and Principal engineers was “organizational impact” rather than individual output. The company was trying to solve exactly this problem: how do you reward people whose value compounds indirectly?
Many companies copied the ladder structure without understanding why it existed. They kept the titles but evaluated the people against shipping velocity anyway.
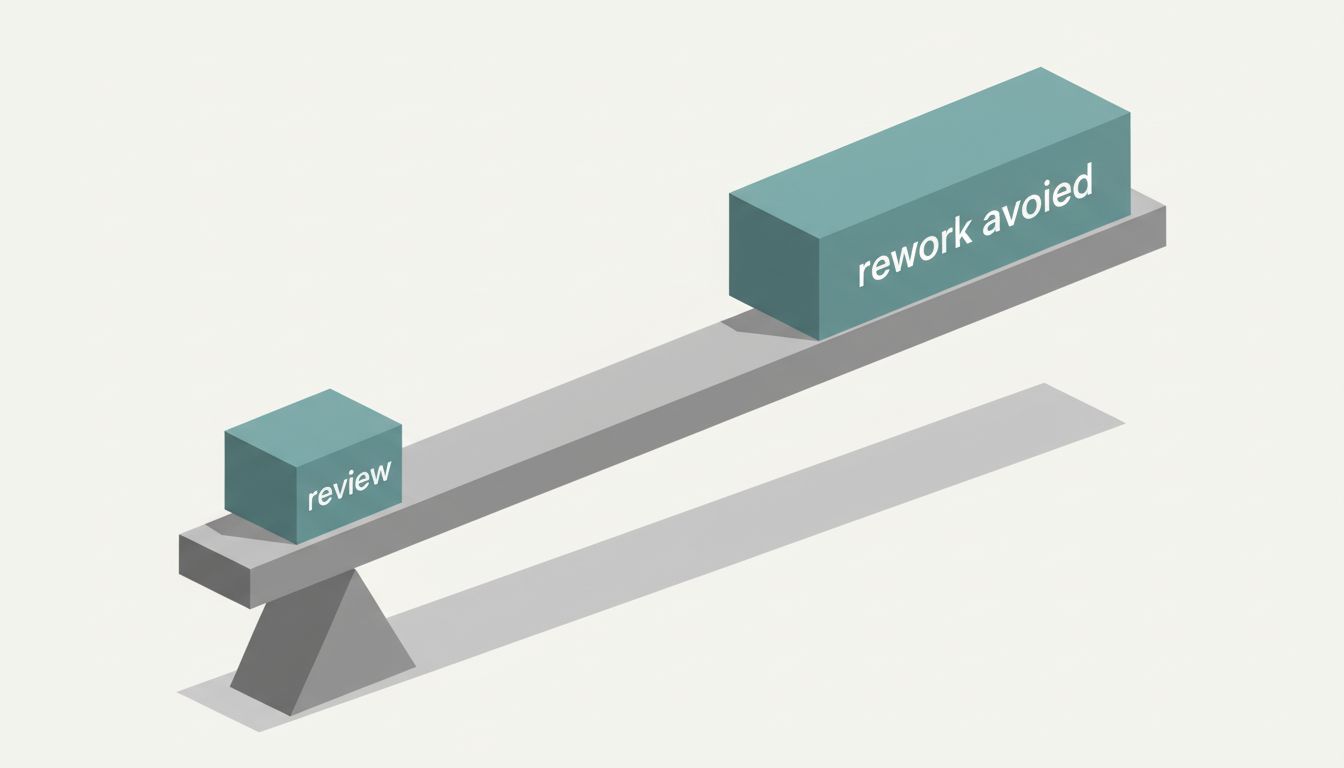
Why It Matters
The clearest way to see the economic value of the non-shipping engineer is to look at what happens when they leave.
In the years following an acquisition, technical debt frequently compounds in ways that acquirers do not anticipate. The engineers who kept systems coherent, who held institutional knowledge about why certain decisions were made, often depart early. What follows is a slow degradation that does not show up immediately in any metric but eventually forces expensive rewrites or rewrites-by-replacement (which is to say, the acquirer simply builds the capability again from scratch). What Happens to a $100M Acquisition When the Builders Walk explores this pattern in detail.
The knowledge that non-shipping engineers carry is often tacit and extraordinarily expensive to reconstruct. They know which database schema was designed under duress during a production crisis and has never been properly normalized. They know why the authentication flow has that unusual exception for enterprise customers. They know which team’s API is technically correct but practically unreliable under load. This knowledge lives in their heads, not in the codebase.
There is a harder version of this argument that most organizations resist: some of the most valuable engineering work is stopping projects entirely. Not slowing them down, not redirecting them, but killing them before they consume resources and produce systems that will eventually need to be unmaintained or removed.
The engineer who kills a project looks, on any standard metric, like a net negative. They blocked work. They prevented shipping. They added friction. The accounting is exactly backwards. A project that should not be built is pure cost if it gets built anyway, and the cost is not just the initial engineering time. It is the ongoing maintenance burden, the new engineer onboarding time explaining a system that should not exist, and the opportunity cost of every engineer hour spent on it that could have gone elsewhere.
What We Can Learn
The first practical lesson is to audit how your engineering performance systems actually work in practice, not in theory. If you have an engineering ladder that nominally rewards “organizational impact” but your actual promotion decisions consistently go to engineers with the highest commit counts, you have already answered the question of what your organization truly values. Engineers respond to incentives, and the best ones are good at reading the real incentives rather than the stated ones. They will leave when they realize the gap.
The second lesson is to think about leverage differently. A senior engineer who writes half the code of a junior engineer but prevents two major architectural mistakes per quarter is almost certainly generating more value. The math is not subtle. However, this only works if the senior engineer’s judgment is actually good, which means the hiring and development work upstream has to be rigorous. Not every non-shipping engineer is generating leverage. Some are just slow. Distinguishing between the two requires management judgment that cannot be automated away.
The third lesson is about time horizons. The value of preventive engineering is almost entirely long-term. A team that eliminates all its non-shipping engineers will likely look more productive for the next two quarters. The costs arrive later and diffusely, making causation difficult to establish. This is a variant of the general problem where optimizing for visible near-term metrics degrades invisible long-term health, a pattern that compounds quietly until it doesn’t.
There is one more thing worth sitting with. The engineers who are best at this work, who have the judgment and the patience and the technical breadth to provide genuine preventive value, are also the engineers with the most options. They can leave easily. They often recognize, faster than their managers do, when an organization’s incentive structure has stopped rewarding what they do.
When they leave, they typically do not write a detailed postmortem. They just go. The organization loses exactly the capability it most needed and has the hardest time measuring. It replaces them with someone who ships more code, and for a while everything looks fine.
This is where the real accounting error happens. Not in the performance review cycle, but in the exit interview that nobody analyzes carefully enough.





