Most performance optimization follows a familiar script: profile the code, find the bottleneck, apply a faster algorithm, repeat. That process has genuine value. But the engineers who produce the most dramatic speed improvements often work upstream of all of it. They ask a different question: does this work need to happen at all?
The answer, surprisingly often, is no.
1. The Best Query Is the One You Don’t Run
Database performance is one of the most studied problems in software engineering, and the consensus finding is consistent: the most expensive query is a redundant one. Applications routinely fetch the same data multiple times within a single request lifecycle, load entire tables when they need three columns, or compute aggregates row-by-row that the database could handle in a single pass.
The N+1 query problem is the canonical example. A page displaying a list of 100 users with their associated account types will, in a naive implementation, execute 101 queries: one to fetch the users, then one per user to fetch their account type. A single join eliminates 100 of those round trips. The data returned is identical. The work is reduced by 99 percent. No faster hardware required.
This pattern shows up everywhere that data access is abstracted away from the developer. Object-relational mappers are convenient, but they make it easy to write code that looks efficient while generating catastrophic query patterns underneath.
2. Caching Is Not a Performance Feature, It’s a Work-Elimination Feature
The conventional framing of caching is that it makes things faster. The more accurate framing is that it makes the same work unnecessary. A cache hit doesn’t speed up computation. It replaces computation with a memory lookup.
This distinction matters because it changes how you think about where to apply caching. The question isn’t “what’s slow?” It’s “what gets recomputed when the inputs haven’t changed?” Expensive calculations with stable inputs are candidates. Network calls that return the same payload across multiple users are candidates. Serializing the same object graph repeatedly is a candidate.
Memoization, the simplest form of caching, makes this explicit: store the result the first time a function runs with a given input, return the stored result every subsequent time. The function still exists. The algorithm still exists. It just runs once instead of a thousand times.
3. Lazy Evaluation Defers Work Until (and Unless) It’s Needed
Eager evaluation computes everything upfront and hopes the results get used. Lazy evaluation computes nothing until something asks for the result. The difference in real applications can be enormous.
Consider a reporting system that generates ten different summary statistics from a large dataset. If a user requests only two of them, an eager implementation does ten computations and discards eight results. A lazy implementation does two. The inputs are the same. The outputs are the same. The work is 80 percent less.
Haskell is the language most associated with lazy evaluation as a default, but the pattern appears across languages and frameworks. Python generators, SQL views that aren’t materialized until queried, React’s lazy component loading, and virtual scrolling in UI frameworks all represent variations on the same idea: don’t compute what hasn’t been requested.
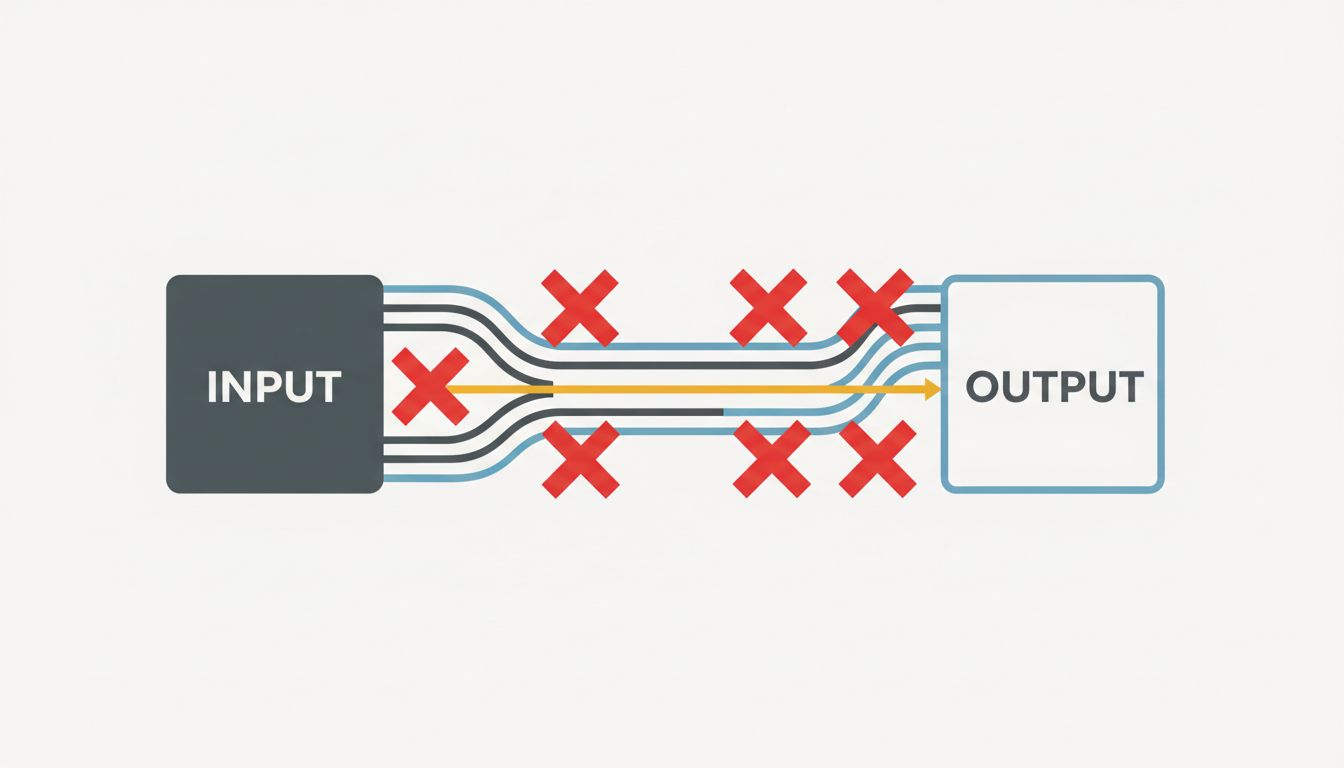
4. Early Exit Is Underrated
Most developers understand that returning early from a function when a condition is met is good for readability. Fewer think about it as a performance strategy at scale.
A validation function that checks ten conditions on an input doesn’t need to check all ten if the first one fails. A search function that looks for any matching record can stop at the first match. A pipeline processing streaming data can discard records that fail a filter before passing them to expensive downstream stages.
The gains here are probabilistic. If 90 percent of inputs fail the first check, you’ve eliminated 90 percent of the work for 90 percent of your data, before touching the rest of the pipeline. At the scale of billions of events per day (which is unremarkable for modern data infrastructure), that arithmetic matters considerably.
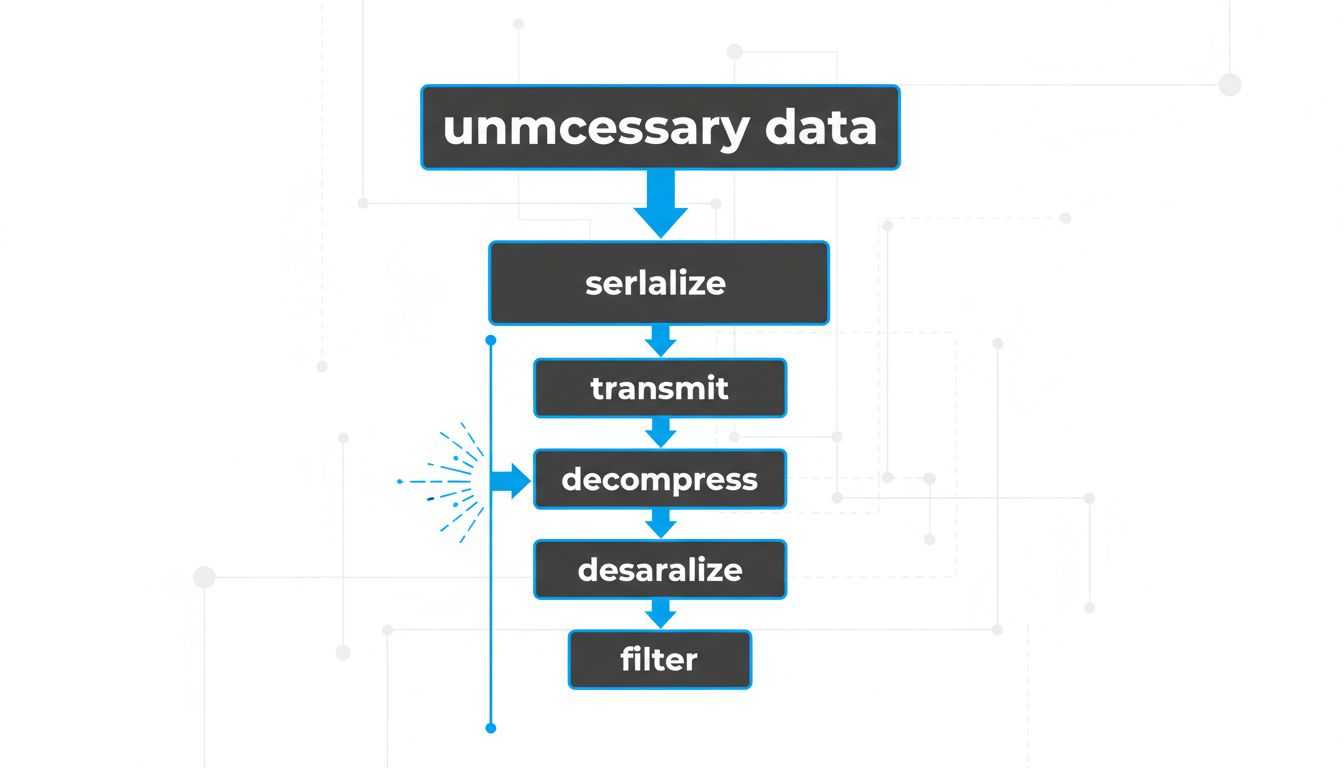
5. Data You Don’t Transmit Doesn’t Need to Be Compressed or Encrypted
Network optimization discussions tend to focus on compression ratios and protocol efficiency. Those matter. But the more tractable question is usually: why is this much data being sent at all?
APIs that return entire objects when callers need two fields are common. Payloads that include metadata the client will never display are common. Syncing entire state trees when only a delta changed is common. Each of these represents work that cascades: the server serializes it, the network carries it, the client deserializes it, the client-side code filters out the fields it needed.
GraphQL was built on exactly this observation. REST APIs tend to return fixed shapes; GraphQL lets callers specify exactly what they need. The productivity argument for GraphQL is reasonable, but the performance argument is more fundamental. Less data transmitted means less work at every layer of the stack.
6. The Most Expensive Code Is Code That Runs on Every Request
Performance problems compound at request boundaries. Code that takes 50 milliseconds to execute costs 50 milliseconds if it runs once. If it runs on every API call at a service handling 10,000 requests per second, it consumes 500 CPU-seconds per second, which is a physical impossibility without enormous hardware investment.
Middleware stacks are where this pattern bites hardest. Authentication middleware that makes a database call on every request, logging middleware that serializes full request objects, request validation that rebuilds context from scratch each time: these are all examples of per-request work that accumulates invisibly until load testing (or a production incident) makes it visible.
The fix is rarely a faster algorithm. It’s asking whether that work needs to run on every request, or whether results can be cached, precomputed, or relocated to a one-time initialization step. The economics of cloud infrastructure make this question especially consequential: per-request overhead scales with traffic, and traffic bills scale with compute.
7. The Work You Eliminate Doesn’t Come Back to Haunt You
Faster hardware and better algorithms are both valid optimization strategies. But they share a limitation: they make necessary work cheaper. They don’t make unnecessary work disappear.
A 2x faster machine running redundant queries still runs redundant queries. A more efficient sorting algorithm applied to data that didn’t need sorting still sorts unnecessarily. The performance ceiling for any system is set by the minimum work required to produce the correct output. Everything above that ceiling is overhead, and overhead responds to elimination better than it responds to acceleration.
The engineers who consistently build fast systems tend to share a habit: before asking how to speed something up, they ask whether it needs to happen. The question is simple. The answers, compounded across an entire codebase, are not.