The Simple Version
When you type a prompt into an AI product, your text gets wrapped in additional instructions, reformatted, and sometimes filtered before the model ever processes it. What the model reads is often substantially different from what you wrote.
There Is a Layer You Are Not Seeing
Most people who use AI tools think of the interaction as direct: you write something, the model reads it, the model responds. That mental model is wrong in a useful way.
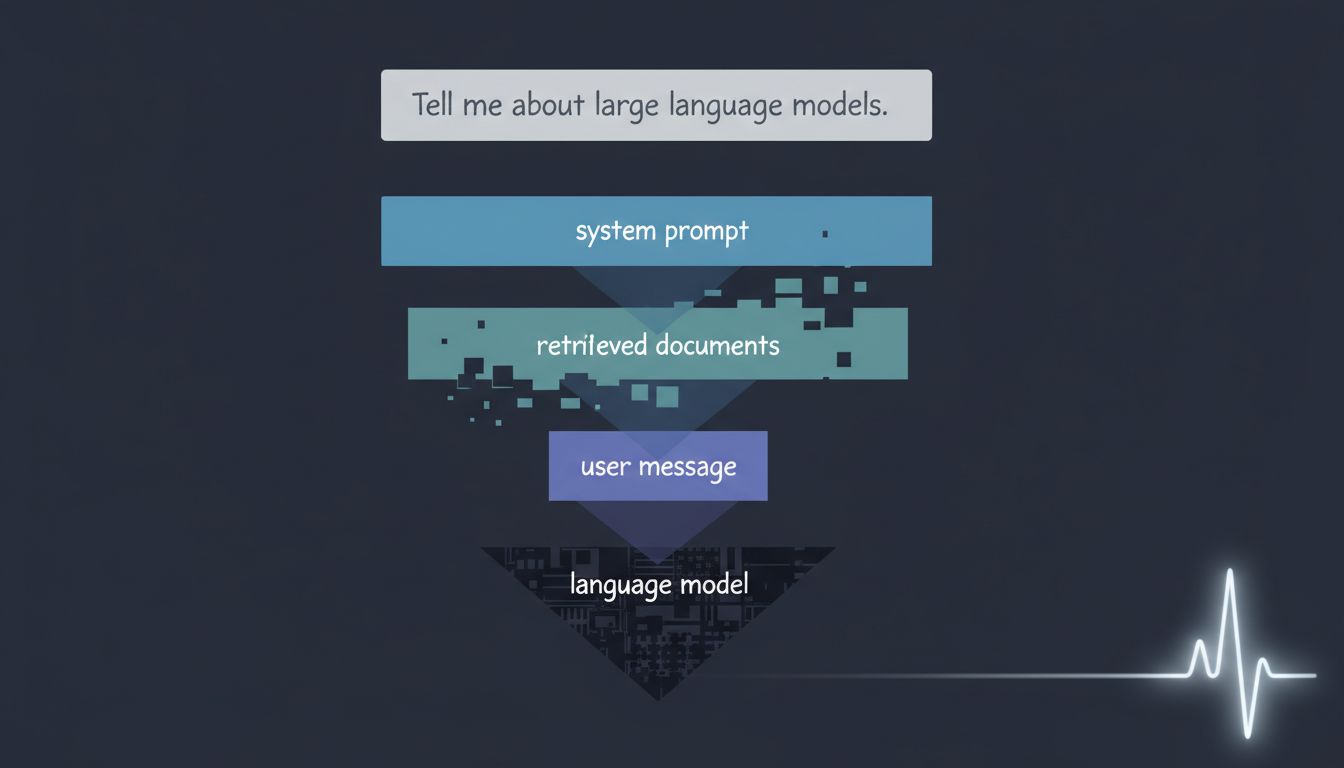
Every production AI application sits a system prompt in front of your input. A system prompt is a block of text, invisible to you, that the developers wrote to shape the model’s behavior. It might define a persona (“You are a helpful customer support agent for Acme Corp”), set constraints (“Never discuss competitor products”), establish a response format, or inject context like today’s date or the user’s account tier.
Your message gets appended after all of that. The model sees the system prompt first, then your words. That ordering matters because these models process context sequentially and weight earlier content heavily when deciding how to respond.
This is why the same question asked to ChatGPT, to a company’s support bot built on GPT-4, and to a custom internal tool can produce radically different answers. Same underlying model, same question, completely different context surrounding it.

Retrieval-Augmented Generation Adds Another Twist
System prompts are just the start. Many AI applications use a technique called retrieval-augmented generation, or RAG. The idea is straightforward: instead of relying only on what the model learned during training, the application searches a database of documents and injects relevant chunks into your prompt at query time.
So if you ask a customer-facing chatbot “What’s your return policy?”, the application might pull three paragraphs from a policy document and silently insert them between the system prompt and your question. The model now has access to current, specific information it was never trained on.
From your perspective, you asked one question. The model received something like:
[System: You are a support agent. Be concise and helpful.]
[Retrieved document: Return Policy v2.3 - Customers may return...]
[User: What's your return policy?]
The quality of the answer depends enormously on whether the retrieval step surfaced the right document. If it pulls an outdated policy or a tangentially related FAQ, the model will answer confidently based on wrong information. The failure is invisible to you because you never saw what got injected.
This is one of the messier failure modes in production AI systems: the model isn’t hallucinating in the classic sense, it’s faithfully answering based on bad context. Debugging it requires inspecting a layer most users don’t know exists. As AI writing your code can’t verify its own output, neither can a RAG system verify that what it retrieved was accurate before injecting it.
Context Windows and the Lost Middle
There’s a further complication. Language models have a context window, the maximum amount of text they can process in a single call. Longer prompts cost more to run and, more importantly, the model’s ability to attend to information degrades as the context grows.
Research has documented a real phenomenon sometimes called “lost in the middle”: when relevant information is buried in the middle of a long context window, models perform measurably worse than when that same information appears near the beginning or end. The model technically “read” everything, but its attention was uneven.
This has a direct consequence for anyone building with these systems. If your system prompt is 2,000 tokens, your retrieved documents are another 3,000 tokens, and the user’s actual question is 50 tokens, the model is spending most of its context budget on scaffolding. The user’s intent is a small signal at the end of a lot of noise. Understanding why context size affects model quality is increasingly practical knowledge for anyone shipping AI features.
What This Means If You Are Building or Prompting
If you are a user, the main takeaway is calibration. When an AI gives you a strange answer, the problem may not be the model’s fundamental capability. It may be that the application wrapped your question in constraints that prevented a useful response. Switching to a different interface for the same model, or asking the same question differently, can surface that.
If you are building AI applications, the prompt that reaches the model is engineering output, not just a text field. A few things follow from this:
System prompts should be versioned and tested. Changing a system prompt is a code change with behavioral consequences. Teams that treat it as a configuration detail rather than a code change end up debugging mysterious regressions.
Inspect what gets injected. Log the full prompt that reaches the model, not just the user query. When something goes wrong, you need to see the whole thing. Most AI frameworks (LangChain, LlamaIndex, the OpenAI API directly) give you access to this if you ask for it.
Be deliberate about ordering. Instructions placed early in the context carry more weight. If you want the model to follow a specific format, put that instruction before the retrieved documents, not after.
Trim aggressively. Every token of boilerplate in your system prompt is context budget spent on scaffolding. A tight, specific system prompt generally outperforms a verbose one that tries to anticipate every edge case.
The gap between what a user types and what a model reads is where most real-world AI quality problems actually live. It’s infrastructure, not magic, and it benefits from the same habits you’d apply to any other layer in a system: observability, testing, and honest accounting of what’s actually happening.