

The simple version
A smaller AI model trained or trimmed for a specific job usually outperforms a giant general-purpose model on that job. Less, done right, is genuinely more.
Why we got obsessed with size in the first place
For most of the past decade, scaling up worked. Researchers kept finding that adding more parameters, more data, and more compute made models measurably smarter. GPT-4 is better than GPT-3 in almost every measurable way. Gemini Ultra outperforms Gemini Nano on most benchmarks. The pattern was clear enough that “bigger is better” became something close to received wisdom.
But benchmarks measure breadth. They ask a model to do thousands of different things and average the results. Your actual application doesn’t work that way. You need a model to do one thing, or a narrow cluster of things, reliably and fast. That’s a different problem entirely.
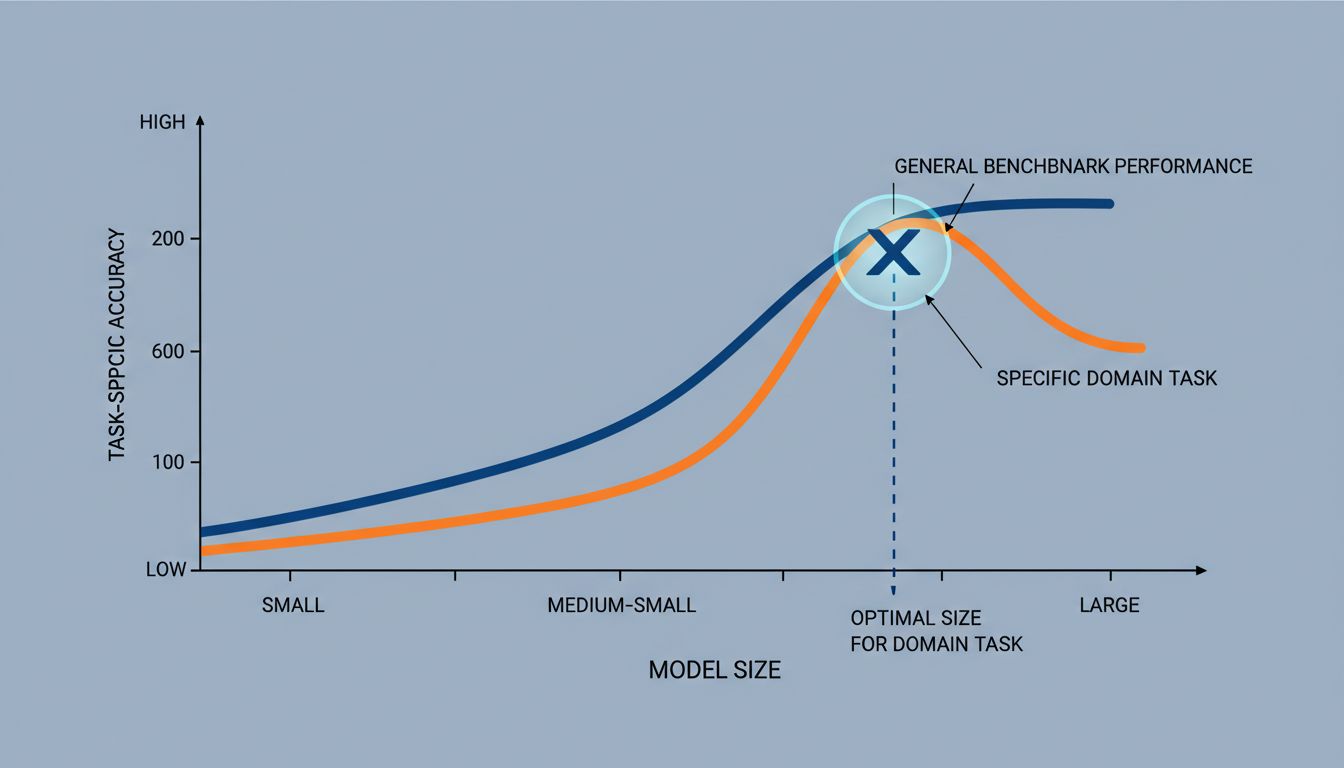
What actually happens when you shrink a model
There are a few distinct techniques people use here, and it’s worth knowing the difference.
Distillation takes a large model (the “teacher”) and trains a smaller model (the “student”) to reproduce its outputs. The student learns not just the correct answers but the teacher’s confidence patterns across wrong answers, which turns out to carry useful information. The result is a compact model that captures a surprising amount of the teacher’s reasoning.
Quantization reduces the numerical precision of a model’s weights. Instead of storing each weight as a 32-bit float, you store it as an 8-bit integer. You lose some fine-grained information, but models are often robust enough that the performance drop is small and the size reduction is dramatic, sometimes 4x smaller with minimal accuracy loss.
Pruning identifies weights that contribute little to outputs and removes them. Think of it as cutting dead wood. A well-pruned model runs faster without meaningful degradation on the tasks it was already good at.
Fine-tuning on a narrow domain isn’t exactly shrinking, but it’s related. You take a smaller base model and train it further on data specific to your use case. The model doesn’t need to be generally brilliant; it needs to be specifically reliable.
Meta’s LLaMA models made this concrete for a lot of developers. A fine-tuned LLaMA model at 7 or 13 billion parameters routinely beats much larger general models on specific tasks, at a fraction of the cost and latency.
The practical advantages compound
Speed is the obvious one. A smaller model returns results faster. For anything user-facing, latency matters more than people admit.
Cost follows directly. Running a large model on every query is expensive. Many companies find that a smaller, task-specific model handles 80% or more of their traffic at a fraction of the API cost, with the big model reserved for genuinely hard cases.
But there’s a less obvious advantage: predictability. Large general models have vast capability surfaces. They can go off in unexpected directions, especially when your prompt is ambiguous. A tightly scoped model has fewer degrees of freedom. It’s more likely to do exactly what you want and less likely to do something creative you didn’t ask for. For production systems, that’s not a limitation, it’s a feature.
This connects to something true about prompting more broadly. If you’ve read about why longer system prompts usually make LLMs worse, the intuition is similar: more constraint, applied thoughtfully, produces better behavior than leaving everything open.
The cases where big models still win
None of this means you should always reach for the smallest model available.
If your task genuinely requires broad reasoning, multi-step logic across unfamiliar domains, or the ability to handle unpredictable inputs gracefully, a large model earns its cost. Customer support for a narrow product line is a good fit for a small fine-tuned model. An AI research assistant that needs to synthesize across fields probably isn’t.
The mistake is defaulting to the largest available model because it feels safer. It often isn’t. A large model that performs adequately on your task with inconsistent reliability is worse in production than a smaller model that nails the task 95% of the time. Consistency is underrated.
There’s also the capability ceiling problem. If you fine-tune a small model and it still can’t do what you need, the model may simply lack the underlying capacity. Distillation can only transfer so much. Some tasks need the bigger foundation.
How to think about this for your own work
If you’re building something with AI, here’s a practical starting point.
First, define your task precisely. Not “answer customer questions” but “classify customer questions into one of seven categories and draft a response using approved language.” Specificity is what makes smaller models viable.
Second, test a small model against your actual data before assuming you need a large one. You may be surprised. Many teams discover that a smaller model, even without fine-tuning, performs adequately once they’ve tightened their prompts and inputs.
Third, if a small model falls short, consider fine-tuning before upgrading to a larger model. A modest fine-tuning run on good domain-specific data often closes the gap.
Fourth, reserve large models for where they’re genuinely needed. Route complex or ambiguous queries up the stack; handle the predictable majority with your efficient smaller model.
The pattern here isn’t unique to AI. Specialized tools beat general ones in the hands of someone who knows the job. A smaller model, shaped carefully for your specific purpose, is a specialist. The giant general model is a generalist. Generalists are great when you don’t know what you need. Once you do, bring in the specialist.





