The Hype Has a History
Something funny happens when people describe what large language models do to code: they reach for words like “understands,” “reasons about,” and “optimizes.” These words carry weight. They imply something new is happening. But if you’ve spent time with compiler theory, you’ll recognize the underlying moves. Register allocation, loop unrolling, dead code elimination, inlining, constant folding. These are optimization problems, and compilers have been solving them automatically, without human guidance, for about forty years.
This isn’t a complaint about AI hype, exactly. The tools are genuinely useful. But the framing obscures something important: the hard problem of automatically transforming code to make it better is not new. Compilers just solved a constrained version of it first, and what they built to do that is worth understanding on its own terms.
What Optimization Actually Means
When a compiler optimizes your code, it’s not making aesthetic choices. It’s applying a series of provably correct transformations that preserve program behavior while changing the execution path. The word “provably” is doing a lot of work there.
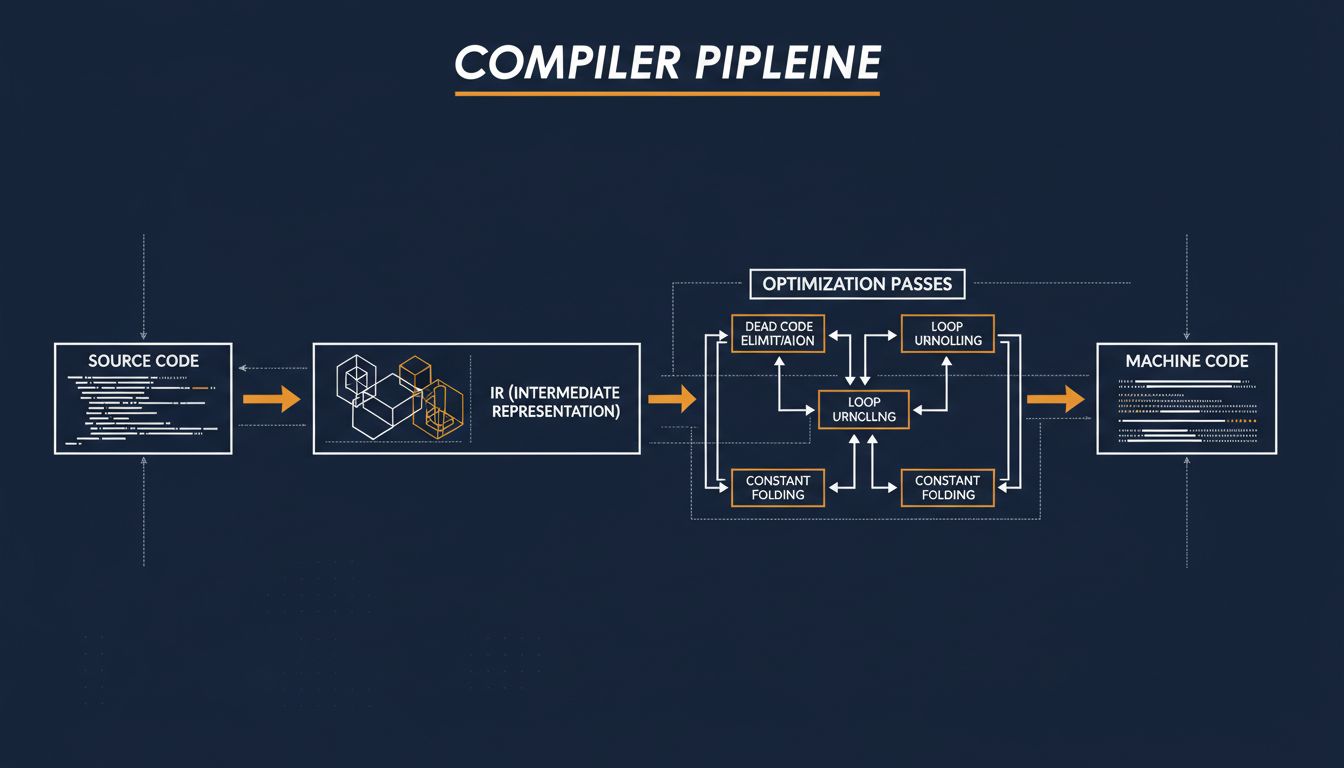
Take constant folding. If you write int x = 2 * 3 * 7;, a compiler doesn’t emit instructions to multiply those numbers at runtime. It sees that all the operands are known at compile time, computes the result (42) itself, and emits int x = 42;. Simple in concept, but this same logic extends surprisingly far. GCC and Clang can evaluate entire functions at compile time if their inputs are constants, turning what looks like runtime work into a single value baked into the binary.
Dead code elimination is the other canonical example. If a branch can never be reached given what the compiler knows about program state, modern compilers remove it. Not because you asked, but because they built up enough understanding of data flow to prove the branch is unreachable. The compiler is doing something that looks a lot like reasoning.
The key constraint: every transformation must be semantically equivalent. A compiler cannot introduce a bug while optimizing. This is the hard line that separates compiler optimization from what current AI coding tools do, and we’ll come back to it.
The Machinery Behind the Magic
Modern optimizing compilers work through a representation called SSA form (Static Single Assignment). Every variable is assigned exactly once in SSA. When you have something like x = 1; x = 2;, SSA splits this into x1 = 1; x2 = 2; and tracks which version of x flows into each part of the program. This sounds pedantic, but it makes a huge class of analysis problems dramatically easier to solve.
On top of SSA, compilers build a data flow graph, a control flow graph, and a dependency graph. These structures let the compiler ask and answer questions like: does this value escape this function? Can these two loads be reordered? Is this loop body side-effect-free? The answers to those questions unlock specific transformations.
Loop optimizations are where compilers historically earn their keep. A technique called loop unrolling replaces a loop that iterates N times with N copies of the loop body (or some factor of N), reducing branch overhead and giving the CPU more instructions to pipeline. Vectorization goes further: if the loop body operates independently on each element of an array, the compiler might replace scalar operations with SIMD instructions (Single Instruction, Multiple Data) that operate on 4, 8, or 16 elements simultaneously. LLVM’s auto-vectorizer does this routinely on modern x86 and ARM code.
Inlining is perhaps the most consequential optimization. When the compiler inlines a function, it replaces the function call with the body of the function at the call site. This eliminates call overhead, but more importantly, it exposes the inlined code to the surrounding context, unlocking further optimizations that cross function boundaries. A tight inner loop that calls a small helper function can become significantly faster after inlining because the compiler can now see that certain checks inside the helper are redundant given what it knows about the caller.

Profile-Guided Optimization: When Compilers Learn from Data
Here’s where the “AI” parallel gets genuinely interesting. Profile-guided optimization (PGO) is a technique where you compile your program, run it against representative workloads to collect execution data, then recompile using that data to guide optimization decisions.
The compiler uses the profiling data to answer questions like: which branches are taken most often? Which functions are called most frequently? Which code paths are hot? Armed with this, it makes better inlining decisions, places hot code in cache-friendly locations, and optimizes branch prediction by reordering the likely and unlikely paths.
This is training on data to improve future performance. It’s not a neural network, but the structural parallel is real. You’re feeding execution traces back into the system to make it make better decisions. Google has used PGO extensively on Chrome, reporting meaningful performance improvements from this technique alone. Firefox does the same. This is a production technique used by major projects, not a research curiosity.
AutoFDO (Automatic Feedback-Directed Optimization) extends this further: instead of requiring a special instrumented build, it uses performance counters from production workloads to generate optimization hints. The compiler is learning from what your real users actually do.
The Frontier: Polyhedral Optimization and Beyond
The most sophisticated compiler optimization work today happens in what’s called the polyhedral model. For programs with regular loop structures (which includes most numerical computing, linear algebra, and convolution operations used in ML inference), the polyhedral model represents the set of loop iterations as a geometric object and applies linear algebra to find optimal loop orderings, tilings, and parallelization strategies.
Tiling, specifically, is why matrix multiplication on modern hardware goes much faster than the naive triple-nested loop you’d write. The cache is finite. If your inner loop keeps evicting data from cache before the outer loop can reuse it, you’re bottlenecked on memory bandwidth. Tiling restructures the loop so that a small block of data is worked on completely before moving to the next block, keeping the working set in cache. Finding the right tile size for a given architecture is exactly the kind of search problem that learning systems are also good at, which is why projects like TVM and Halide try to automate this through learned cost models.
MLSys (machine learning for systems) is a genuine research area, and it does produce results. But it’s building on fifty years of compiler theory, not replacing it.
Where AI Coding Tools Actually Differ
So what does an LLM-based coding assistant do that a compiler doesn’t? The honest answer is that it operates in a completely different space.
A compiler works on code with formal semantics. Every operation has a defined meaning. The compiler can reason precisely about what the program does. An LLM works on the space of human intent, translating an ambiguous description into plausible code. These are different problems. One is search over a space of provably equivalent programs. The other is generation under uncertainty.
The AI coding tool’s superpower is handling things that don’t have formal specifications: “write something that feels like a REST API,” “refactor this to be more readable,” “generate test cases for edge cases I haven’t thought of.” A compiler cannot do any of that. It operates strictly on what you gave it.
The compiler’s superpower is correctness guarantees. When GCC inlines a function and then eliminates a redundant load, you can formally prove the output program is equivalent to the input. No LLM provides that guarantee. This is why the compiler doesn’t care what you name things but it cares deeply about types, memory aliasing, and side effects. These are the things it can actually reason about.
Why This History Matters Now
There’s a tendency to treat AI-powered developer tools as if optimization and program analysis emerged in 2022. They didn’t. The accumulated knowledge in compiler theory represents some of the deepest applied computer science done in the last half-century. The people who built LLVM’s optimizer, who proved the correctness of SSA transformations, who figured out how to vectorize arbitrary loop nests, were doing hard constraint satisfaction and formal reasoning. The vocabulary was different but the intellectual project was the same.
This matters because if you’re evaluating an AI tool that claims to optimize your code, you should be asking: what guarantees does it provide? Is it doing something the compiler already does, just with worse guarantees? Or is it operating in the space of higher-level structural changes that compilers genuinely can’t touch, things like algorithm selection, API design, or data structure choice?
There are real wins available in that latter space. A compiler cannot tell you that you should use a hash map instead of a sorted array, because that’s a semantic choice that depends on your access patterns and requirements, not a provably equivalent transformation. An LLM might reasonably suggest it, though it might also be wrong.
The tools are complements, not replacements, and understanding what each one actually does is how you use both well.
What This Means
Compilers perform sophisticated automated optimization using data flow analysis, graph transformations, and (via PGO) learned feedback from actual workloads. This is not a new idea. It is a mature, formally grounded body of work.
AI coding tools operate in a different space: they handle ambiguity, natural language intent, and structural suggestions that fall outside what formal verification can touch. That’s genuinely useful and genuinely different from what compilers do.
The interesting frontier is where these approaches meet: learned cost models guiding search over program transformations, ML-based autotuners finding tile sizes for specific hardware, compilers that use runtime traces to make better static decisions. That work is happening, and it’s incremental and grounded, not revolutionary.
Next time someone tells you AI is going to transform how we optimize code, the correct response is: it already has been, since roughly 1983. The question is what specific problem you’re trying to solve and which tool has the right guarantees for it.