The simple version
Prompt engineering exists because current AI models require humans to compensate for their limitations. As those limitations shrink, the compensation work disappears with them.
Why prompt engineering exists at all
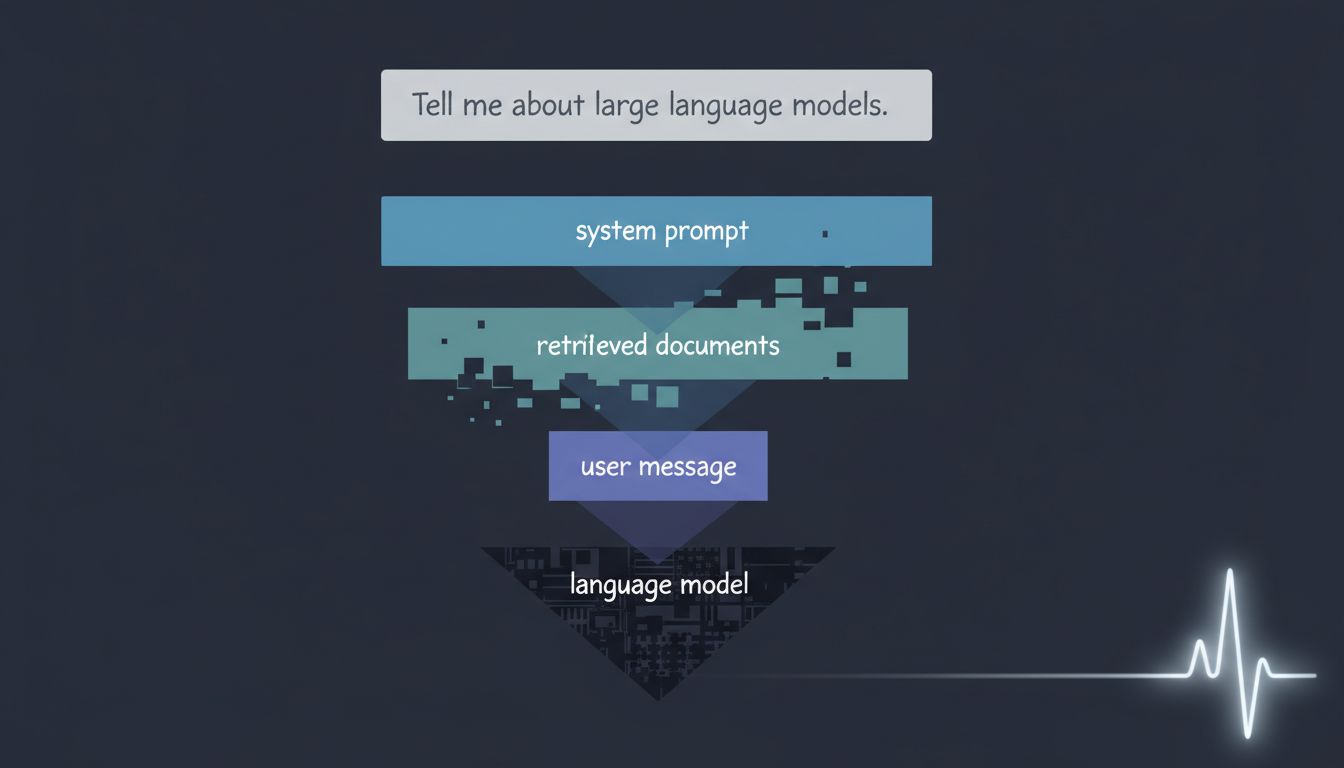
When you write a careful prompt, you are doing translation work. You have a goal in your head, and you are converting it into a form the model can act on reliably. You add context the model is missing. You specify the format you want. You tell it what to ignore. You give it examples of good outputs.
All of that work exists because there is a gap between what you mean and what the model understands. Prompt engineering is the art of bridging that gap manually.
This is not a new problem. Every abstraction layer in computing history has existed to bridge a gap, then disappeared when a better abstraction closed it. Assembly language let programmers talk to hardware without writing raw machine code. High-level languages like C let them stop thinking about registers entirely. Garbage collection removed manual memory management. Each layer of abstraction was once a specialized skill, and each one eventually became invisible infrastructure. Compilers have been quietly doing this kind of optimization work for decades, translating human-readable code into something machines can use efficiently. Prompt engineering is just the newest version of the same pattern.
The three forces closing the gap
Three things are actively making prompt engineering less necessary, and they’re working from different directions simultaneously.
Models are getting better at inference. Newer models are significantly better at figuring out what you probably mean, even when you express it imprecisely. GPT-4 required noticeably more careful prompting than GPT-4o for many tasks. Claude’s recent versions handle ambiguous instructions more gracefully than their predecessors. This is not marketing. You can test it yourself by taking a prompt that worked well on an older model and running it on a newer one without modification. Often the newer model does better on both versions. The gap between a careful prompt and a casual one is shrinking.
Systems are being built to handle prompting for you. Most people using AI tools in 2025 are not writing raw prompts at all. They are clicking buttons in interfaces that generate prompts behind the scenes. Notion AI, GitHub Copilot, Cursor, and dozens of other products have absorbed the prompting layer into the product itself. The user says what they want in plain language (or doesn’t say anything at all, because the tool infers context from the file they have open). The prompt engineering happened upstream, at design time, by the people who built the tool.
AI systems are starting to prompt themselves. Agentic frameworks like those being built on top of models from Anthropic and OpenAI can now decompose a goal into sub-tasks, generate prompts for each sub-task, evaluate the outputs, and retry with modified prompts if something goes wrong. The model is, in a meaningful sense, doing prompt engineering on itself. You describe the outcome you want. The system figures out how to ask for it.
This does not mean the skill is worthless right now
If you are working with AI systems professionally today, prompt engineering knowledge is genuinely useful. Understanding why a model fails on a given task (ambiguous instruction, missing context, conflicting constraints) helps you fix it faster and build more reliable pipelines. Understanding the difference between zero-shot and few-shot prompting, or how to structure a system prompt for a customer-facing product, has real practical value in 2025.
The point is not that you should stop learning it. The point is that you should hold it the way you would hold any intermediate skill: useful for now, unlikely to be a career differentiator in ten years, and probably not the thing you want to bet your entire professional identity on.
As one frame for this: the people who were genuinely expert at writing SQL by hand in the 1990s were valuable precisely because the tools for generating SQL were bad. Now those tools are much better, and raw SQL authorship is a smaller fraction of what database work actually requires. The underlying knowledge (understanding relational data, query planning, indexing) stayed relevant. The manual translation layer did not.
Prompt engineering will follow the same arc. The manual craft fades. The conceptual understanding of how models process information, where they fail, and what kinds of problems they’re suited for stays relevant much longer. As our article on prompt brittleness points out, the prompt that works today will break next month anyway, which is itself a sign that the skill operates at the wrong level of abstraction to be durable.
What actually replaces it
When the manual prompting layer gets absorbed into tools and models, three other skills move up in value.
Problem decomposition. Knowing how to break a complex goal into pieces that an AI system can actually execute on is harder than it looks, and it’s not going away. This is less about knowing prompt syntax and more about understanding what makes a task well-defined.
Evaluation. As AI systems do more work autonomously, the bottleneck shifts to assessing whether the output is actually good. Evaluating AI outputs at scale (knowing what to measure, how to catch subtle failures, how to avoid being fooled by confident-sounding wrong answers) is a skill that gets more important as models get more capable, not less.
System design. How you connect AI capabilities to real workflows, what guardrails you build in, how you handle failure cases: these questions live above the prompt layer and don’t disappear when prompting gets automated.
The useful way to think about this
Prompt engineering is scaffolding. It was always meant to be temporary. The building going up behind it is AI systems that understand you well enough that you can just tell them what you want.
That future is not here yet, and the scaffolding is still load-bearing. Learn it, use it, but don’t confuse the scaffolding for the structure. The goal was always to make the translation layer thin enough to disappear. It’s working.